 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Oct 10, 2024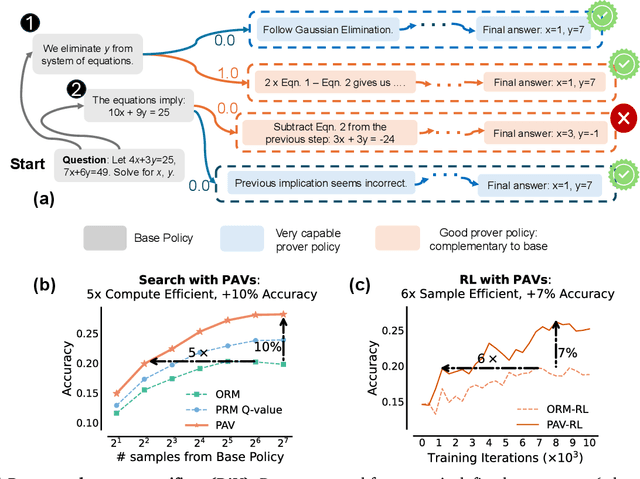
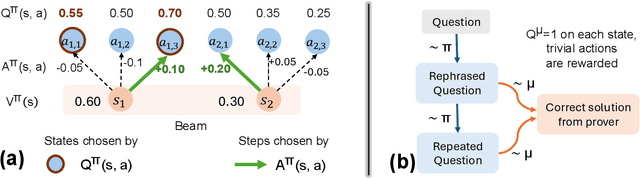
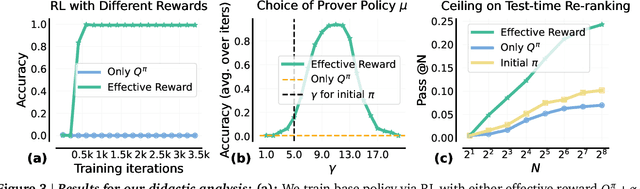
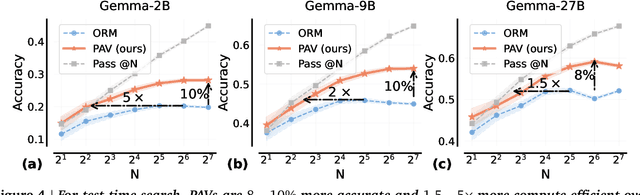
A promising approach for improving reasoning in large language models is to use process reward models (PRMs). PRMs provide feedback at each step of a multi-step reasoning trace, potentially improving credit assignment over outcome reward models (ORMs) that only provide feedback at the final step. However, collecting dense, per-step human labels is not scalable, and training PRMs from automatically-labeled data has thus far led to limited gains. To improve a base policy by running search against a PRM or using it as dense rewards for reinforcement learning (RL), we ask: "How should we design process rewards?". Our key insight is that, to be effective, the process reward for a step should measure progress: a change in the likelihood of producing a correct response in the future, before and after taking the step, corresponding to the notion of step-level advantages in RL. Crucially, this progress should be measured under a prover policy distinct from the base policy. We theoretically characterize the set of good provers and our results show that optimizing process rewards from such provers improves exploration during test-time search and online RL. In fact, our characterization shows that weak prover policies can substantially improve a stronger base policy, which we also observe empirically. We validate our claims by training process advantage verifiers (PAVs) to predict progress under such provers, and show that compared to ORMs, test-time search against PAVs is $>8\%$ more accurate, and $1.5-5\times$ more compute-efficient. Online RL with dense rewards from PAVs enables one of the first results with $5-6\times$ gain in sample efficiency, and $>6\%$ gain in accuracy, over ORMs.
RL on Incorrect Synthetic Data Scales the Efficiency of LLM Math Reasoning by Eight-Fold
Jun 20, 2024Training on model-generated synthetic data is a promising approach for finetuning LLMs, but it remains unclear when it helps or hurts. In this paper, we investigate this question for math reasoning via an empirical study, followed by building a conceptual understanding of our observations. First, we find that while the typical approach of finetuning a model on synthetic correct or positive problem-solution pairs generated by capable models offers modest performance gains, sampling more correct solutions from the finetuned learner itself followed by subsequent fine-tuning on this self-generated data $\textbf{doubles}$ the efficiency of the same synthetic problems. At the same time, training on model-generated positives can amplify various spurious correlations, resulting in flat or even inverse scaling trends as the amount of data increases. Surprisingly, we find that several of these issues can be addressed if we also utilize negative responses, i.e., model-generated responses that are deemed incorrect by a final answer verifier. Crucially, these negatives must be constructed such that the training can appropriately recover the utility or advantage of each intermediate step in the negative response. With this per-step scheme, we are able to attain consistent gains over only positive data, attaining performance similar to amplifying the amount of synthetic data by $\mathbf{8 \times}$. We show that training on per-step negatives can help to unlearn spurious correlations in the positive data, and is equivalent to advantage-weighted reinforcement learning (RL), implying that it inherits robustness benefits of RL over imitating positive data alone.
Sequential Modeling Enables Scalable Learning for Large Vision Models
Dec 01, 2023
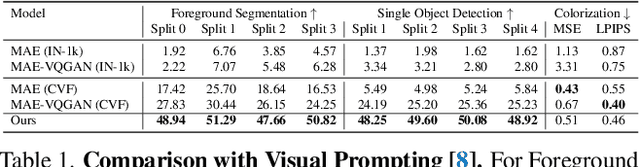
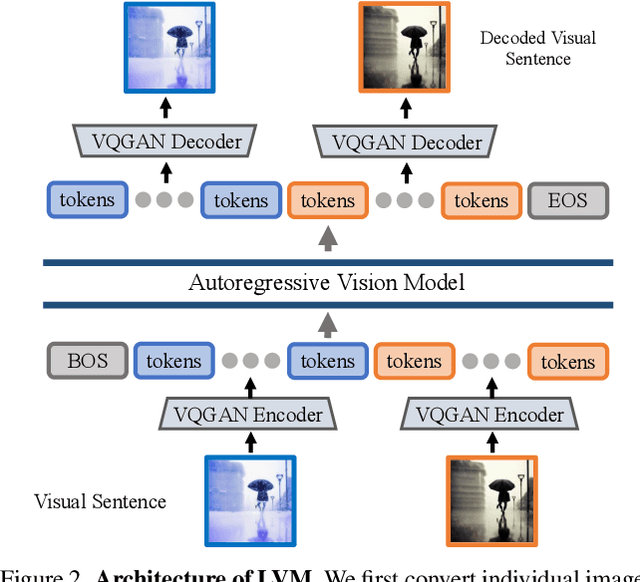
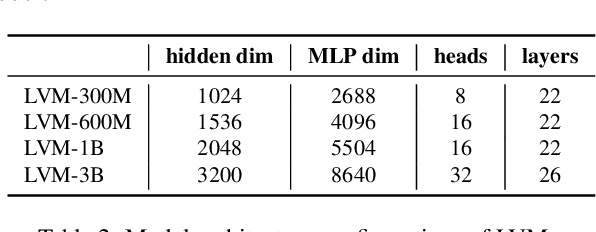
We introduce a novel sequential modeling approach which enables learning a Large Vision Model (LVM) without making use of any linguistic data. To do this, we define a common format, "visual sentences", in which we can represent raw images and videos as well as annotated data sources such as semantic segmentations and depth reconstructions without needing any meta-knowledge beyond the pixels. Once this wide variety of visual data (comprising 420 billion tokens) is represented as sequences, the model can be trained to minimize a cross-entropy loss for next token prediction. By training across various scales of model architecture and data diversity, we provide empirical evidence that our models scale effectively. Many different vision tasks can be solved by designing suitable visual prompts at test time.
Action-Quantized Offline Reinforcement Learning for Robotic Skill Learning
Oct 18, 2023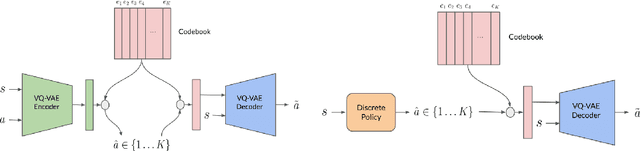

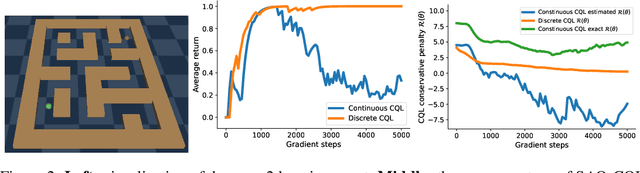
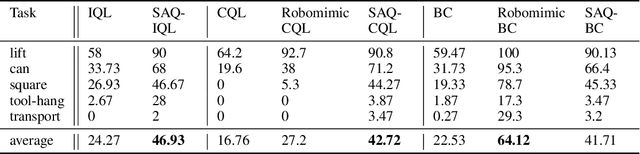
The offline reinforcement learning (RL) paradigm provides a general recipe to convert static behavior datasets into policies that can perform better than the policy that collected the data. While policy constraints, conservatism, and other methods for mitigating distributional shifts have made offline reinforcement learning more effective, the continuous action setting often necessitates various approximations for applying these techniques. Many of these challenges are greatly alleviated in discrete action settings, where offline RL constraints and regularizers can often be computed more precisely or even exactly. In this paper, we propose an adaptive scheme for action quantization. We use a VQ-VAE to learn state-conditioned action quantization, avoiding the exponential blowup that comes with na\"ive discretization of the action space. We show that several state-of-the-art offline RL methods such as IQL, CQL, and BRAC improve in performance on benchmarks when combined with our proposed discretization scheme. We further validate our approach on a set of challenging long-horizon complex robotic manipulation tasks in the Robomimic environment, where our discretized offline RL algorithms are able to improve upon their continuous counterparts by 2-3x. Our project page is at https://saqrl.github.io/
Latent Conservative Objective Models for Data-Driven Crystal Structure Prediction
Oct 16, 2023



In computational chemistry, crystal structure prediction (CSP) is an optimization problem that involves discovering the lowest energy stable crystal structure for a given chemical formula. This problem is challenging as it requires discovering globally optimal designs with the lowest energies on complex manifolds. One approach to tackle this problem involves building simulators based on density functional theory (DFT) followed by running search in simulation, but these simulators are painfully slow. In this paper, we study present and study an alternate, data-driven approach to crystal structure prediction: instead of directly searching for the most stable structures in simulation, we train a surrogate model of the crystal formation energy from a database of existing crystal structures, and then optimize this model with respect to the parameters of the crystal structure. This surrogate model is trained to be conservative so as to prevent exploitation of its errors by the optimizer. To handle optimization in the non-Euclidean space of crystal structures, we first utilize a state-of-the-art graph diffusion auto-encoder (CD-VAE) to convert a crystal structure into a vector-based search space and then optimize a conservative surrogate model of the crystal energy, trained on top of this vector representation. We show that our approach, dubbed LCOMs (latent conservative objective models), performs comparably to the best current approaches in terms of success rate of structure prediction, while also drastically reducing computational cost.
Multi-Stage Cable Routing through Hierarchical Imitation Learning
Jul 23, 2023



We study the problem of learning to perform multi-stage robotic manipulation tasks, with applications to cable routing, where the robot must route a cable through a series of clips. This setting presents challenges representative of complex multi-stage robotic manipulation scenarios: handling deformable objects, closing the loop on visual perception, and handling extended behaviors consisting of multiple steps that must be executed successfully to complete the entire task. In such settings, learning individual primitives for each stage that succeed with a high enough rate to perform a complete temporally extended task is impractical: if each stage must be completed successfully and has a non-negligible probability of failure, the likelihood of successful completion of the entire task becomes negligible. Therefore, successful controllers for such multi-stage tasks must be able to recover from failure and compensate for imperfections in low-level controllers by smartly choosing which controllers to trigger at any given time, retrying, or taking corrective action as needed. To this end, we describe an imitation learning system that uses vision-based policies trained from demonstrations at both the lower (motor control) and the upper (sequencing) level, present a system for instantiating this method to learn the cable routing task, and perform evaluations showing great performance in generalizing to very challenging clip placement variations. Supplementary videos, datasets, and code can be found at https://sites.google.com/view/cablerouting.
The False Promise of Imitating Proprietary LLMs
May 25, 2023



An emerging method to cheaply improve a weaker language model is to finetune it on outputs from a stronger model, such as a proprietary system like ChatGPT (e.g., Alpaca, Self-Instruct, and others). This approach looks to cheaply imitate the proprietary model's capabilities using a weaker open-source model. In this work, we critically analyze this approach. We first finetune a series of LMs that imitate ChatGPT using varying base model sizes (1.5B--13B), data sources, and imitation data amounts (0.3M--150M tokens). We then evaluate the models using crowd raters and canonical NLP benchmarks. Initially, we were surprised by the output quality of our imitation models -- they appear far better at following instructions, and crowd workers rate their outputs as competitive with ChatGPT. However, when conducting more targeted automatic evaluations, we find that imitation models close little to none of the gap from the base LM to ChatGPT on tasks that are not heavily supported in the imitation data. We show that these performance discrepancies may slip past human raters because imitation models are adept at mimicking ChatGPT's style but not its factuality. Overall, we conclude that model imitation is a false promise: there exists a substantial capabilities gap between open and closed LMs that, with current methods, can only be bridged using an unwieldy amount of imitation data or by using more capable base LMs. In turn, we argue that the highest leverage action for improving open-source models is to tackle the difficult challenge of developing better base LMs, rather than taking the shortcut of imitating proprietary systems.
Offline Q-Learning on Diverse Multi-Task Data Both Scales And Generalizes
Nov 28, 2022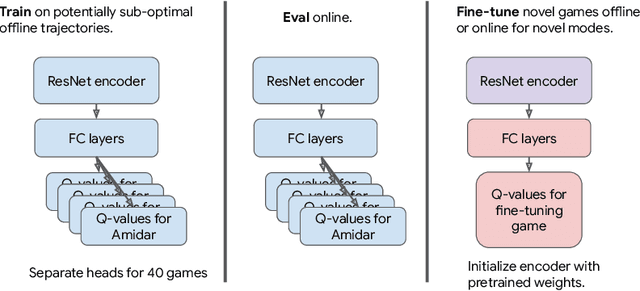



The potential of offline reinforcement learning (RL) is that high-capacity models trained on large, heterogeneous datasets can lead to agents that generalize broadly, analogously to similar advances in vision and NLP. However, recent works argue that offline RL methods encounter unique challenges to scaling up model capacity. Drawing on the learnings from these works, we re-examine previous design choices and find that with appropriate choices: ResNets, cross-entropy based distributional backups, and feature normalization, offline Q-learning algorithms exhibit strong performance that scales with model capacity. Using multi-task Atari as a testbed for scaling and generalization, we train a single policy on 40 games with near-human performance using up-to 80 million parameter networks, finding that model performance scales favorably with capacity. In contrast to prior work, we extrapolate beyond dataset performance even when trained entirely on a large (400M transitions) but highly suboptimal dataset (51% human-level performance). Compared to return-conditioned supervised approaches, offline Q-learning scales similarly with model capacity and has better performance, especially when the dataset is suboptimal. Finally, we show that offline Q-learning with a diverse dataset is sufficient to learn powerful representations that facilitate rapid transfer to novel games and fast online learning on new variations of a training game, improving over existing state-of-the-art representation learning approaches.
FCM: Forgetful Causal Masking Makes Causal Language Models Better Zero-Shot Learners
Oct 24, 2022


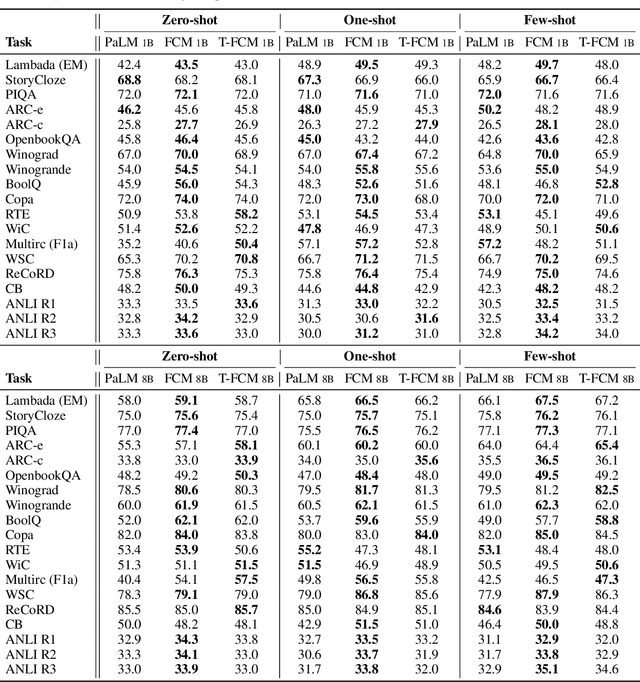
Large language models (LLM) trained using the next-token-prediction objective, such as GPT3 and PaLM, have revolutionized natural language processing in recent years by showing impressive zero-shot and few-shot capabilities across a wide range of tasks. In this work, we propose a simple technique that significantly boosts the performance of LLMs without adding computational cost. Our key observation is that, by performing the next token prediction task with randomly selected past tokens masked out, we can improve the quality of the learned representations for downstream language understanding tasks. We hypothesize that randomly masking past tokens prevents over-attending to recent tokens and encourages attention to tokens in the distant past. By randomly masking input tokens in the PaLM model, we show that we can significantly improve 1B and 8B PaLM's zero-shot performance on the SuperGLUE benchmark from 55.7 to 59.2 and from 61.6 to 64.0, respectively. Our largest 8B model matches the score of PaLM with an average score of 64, despite the fact that PaLM is trained on a much larger dataset (780B tokens) of high-quality conversation and webpage data, while ours is trained on the smaller C4 dataset (180B tokens). Experimental results show that our method also improves PaLM's zero and few-shot performance on a diverse suite of tasks, including commonsense reasoning, natural language inference and cloze completion. Moreover, we show that our technique also helps representation learning, significantly improving PaLM's finetuning results.
Multimodal Masked Autoencoders Learn Transferable Representations
May 31, 2022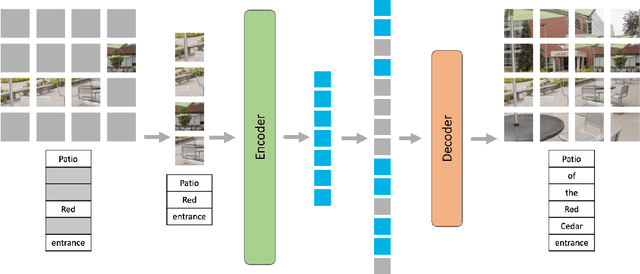
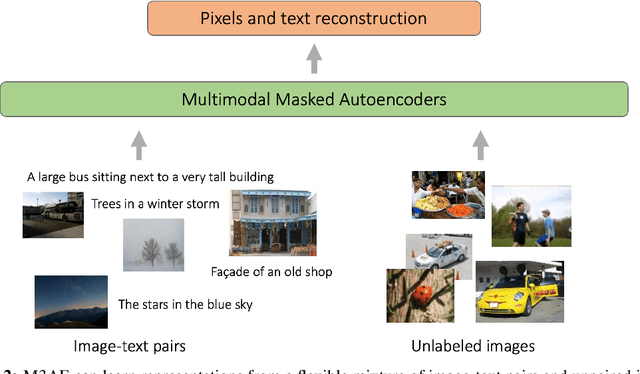
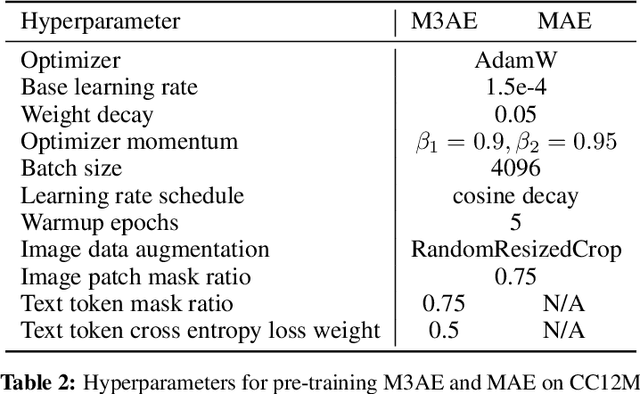
Building scalable models to learn from diverse, multimodal data remains an open challenge. For vision-language data, the dominant approaches are based on contrastive learning objectives that train a separate encoder for each modality. While effective, contrastive learning approaches introduce sampling bias depending on the data augmentations used, which can degrade performance on downstream tasks. Moreover, these methods are limited to paired image-text data, and cannot leverage widely-available unpaired data. In this paper, we investigate whether a large multimodal model trained purely via masked token prediction, without using modality-specific encoders or contrastive learning, can learn transferable representations for downstream tasks. We propose a simple and scalable network architecture, the Multimodal Masked Autoencoder (M3AE), which learns a unified encoder for both vision and language data via masked token prediction. We provide an empirical study of M3AE trained on a large-scale image-text dataset, and find that M3AE is able to learn generalizable representations that transfer well to downstream tasks. Surprisingly, we find that M3AE benefits from a higher text mask ratio (50-90%), in contrast to BERT whose standard masking ratio is 15%, due to the joint training of two data modalities. We also provide qualitative analysis showing that the learned representation incorporates meaningful information from both image and language. Lastly, we demonstrate the scalability of M3AE with larger model size and training time, and its flexibility to train on both paired image-text data as well as unpaired data.