 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple-Prediction-Powered Inference
Mar 28, 2026Statistical estimation often involves tradeoffs between expensive, high-quality measurements and a variety of lower-quality proxies. We introduce Multiple-Prediction-Powered Inference (MultiPPI): a general framework for constructing statistically efficient estimates by optimally allocating resources across these diverse data sources. This work provides theoretical guarantees about the minimax optimality, finite-sample performance, and asymptotic normality of the MultiPPI estimator. Through experiments across three diverse large language model (LLM) evaluation scenarios, we show that MultiPPI consistently achieves lower estimation error than existing baselines. This advantage stems from its budget-adaptive allocation strategy, which strategically combines subsets of models by learning their complex cost and correlation structures.
Rich Insights from Cheap Signals: Efficient Evaluations via Tensor Factorization
Mar 04, 2026Moving beyond evaluations that collapse performance across heterogeneous prompts toward fine-grained evaluation at the prompt level, or within relatively homogeneous subsets, is necessary to diagnose generative models' strengths and weaknesses. Such fine-grained evaluations, however, suffer from a data bottleneck: human gold-standard labels are too costly at this scale, while automated ratings are often misaligned with human judgment. To resolve this challenge, we propose a novel statistical model based on tensor factorization that merges cheap autorater data with a limited set of human gold-standard labels. Specifically, our approach uses autorater scores to pretrain latent representations of prompts and generative models, and then aligns those pretrained representations to human preferences using a small calibration set. This sample-efficient methodology is robust to autorater quality, more accurately predicts human preferences on a per-prompt basis than standard baselines, and provides tight confidence intervals for key statistical parameters of interest. We also showcase the practical utility of our method by constructing granular leaderboards based on prompt qualities and by estimating model performance solely from autorater scores, eliminating the need for additional human annotations.
MT-PingEval: Evaluating Multi-Turn Collaboration with Private Information Games
Feb 27, 2026We present a scalable methodology for evaluating language models in multi-turn interactions, using a suite of collaborative games that require effective communication about private information. This enables an interactive scaling analysis, in which a fixed token budget is divided over a variable number of turns. We find that in many cases, language models are unable to use interactive collaboration to improve over the non-interactive baseline scenario in which one agent attempts to summarize its information and the other agent immediately acts -- despite substantial headroom. This suggests that state-of-the-art models still suffer from significant weaknesses in planning and executing multi-turn collaborative conversations. We analyze the linguistic features of these dialogues, assessing the roles of sycophancy, information density, and discourse coherence. While there is no single linguistic explanation for the collaborative weaknesses of contemporary language models, we note that humans achieve comparable task success at superior token efficiency by producing dialogues that are more coherent than those produced by most language models. The proactive management of private information is a defining feature of real-world communication, and we hope that MT-PingEval will drive further work towards improving this capability.
Cost-Optimal Active AI Model Evaluation
Jun 09, 2025The development lifecycle of generative AI systems requires continual evaluation, data acquisition, and annotation, which is costly in both resources and time. In practice, rapid iteration often makes it necessary to rely on synthetic annotation data because of the low cost, despite the potential for substantial bias. In this paper, we develop novel, cost-aware methods for actively balancing the use of a cheap, but often inaccurate, weak rater -- such as a model-based autorater that is designed to automatically assess the quality of generated content -- with a more expensive, but also more accurate, strong rater alternative such as a human. More specifically, the goal of our approach is to produce a low variance, unbiased estimate of the mean of the target "strong" rating, subject to some total annotation budget. Building on recent work in active and prediction-powered statistical inference, we derive a family of cost-optimal policies for allocating a given annotation budget between weak and strong raters so as to maximize statistical efficiency. Using synthetic and real-world data, we empirically characterize the conditions under which these policies yield improvements over prior methods. We find that, especially in tasks where there is high variability in the difficulty of examples, our policies can achieve the same estimation precision at a far lower total annotation budget than standard evaluation methods.
Don't lie to your friends: Learning what you know from collaborative self-play
Mar 18, 2025To be helpful assistants, AI agents must be aware of their own capabilities and limitations. This includes knowing when to answer from parametric knowledge versus using tools, when to trust tool outputs, and when to abstain or hedge. Such capabilities are hard to teach through supervised fine-tuning because they require constructing examples that reflect the agent's specific capabilities. We therefore propose a radically new approach to teaching agents what they know: \emph{collaborative self-play}. We construct multi-agent collaborations in which the group is rewarded for collectively arriving at correct answers. The desired meta-knowledge emerges from the incentives built into the structure of the interaction. We focus on small societies of agents that have access to heterogeneous tools (corpus-specific retrieval), and therefore must collaborate to maximize their success while minimizing their effort. Experiments show that group-level rewards for multi-agent communities can induce policies that \emph{transfer} to improve tool use and selective prediction in settings where individual agents are deployed in isolation.
Mitigating Preference Hacking in Policy Optimization with Pessimism
Mar 10, 2025This work tackles the problem of overoptimization in reinforcement learning from human feedback (RLHF), a prevalent technique for aligning models with human preferences. RLHF relies on reward or preference models trained on \emph{fixed preference datasets}, and these models are unreliable when evaluated outside the support of this preference data, leading to the common reward or preference hacking phenomenon. We propose novel, pessimistic objectives for RLHF which are provably robust to overoptimization through the use of pessimism in the face of uncertainty, and design practical algorithms, P3O and PRPO, to optimize these objectives. Our approach is derived for the general preference optimization setting, but can be used with reward models as well. We evaluate P3O and PRPO on the tasks of fine-tuning language models for document summarization and creating helpful assistants, demonstrating remarkable resilience to overoptimization.
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
Oct 28, 2024



Large language models (LLMs) are expensive to deploy. Parameter sharing offers a possible path towards reducing their size and cost, but its effectiveness in modern LLMs remains fairly limited. In this work, we revisit "layer tying" as form of parameter sharing in Transformers, and introduce novel methods for converting existing LLMs into smaller "Recursive Transformers" that share parameters across layers, with minimal loss of performance. Here, our Recursive Transformers are efficiently initialized from standard pretrained Transformers, but only use a single block of unique layers that is then repeated multiple times in a loop. We further improve performance by introducing Relaxed Recursive Transformers that add flexibility to the layer tying constraint via depth-wise low-rank adaptation (LoRA) modules, yet still preserve the compactness of the overall model. We show that our recursive models (e.g., recursive Gemma 1B) outperform both similar-sized vanilla pretrained models (such as TinyLlama 1.1B and Pythia 1B) and knowledge distillation baselines -- and can even recover most of the performance of the original "full-size" model (e.g., Gemma 2B with no shared parameters). Finally, we propose Continuous Depth-wise Batching, a promising new inference paradigm enabled by the Recursive Transformer when paired with early exiting. In a theoretical analysis, we show that this has the potential to lead to significant (2-3x) gains in inference throughput.
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Oct 10, 2024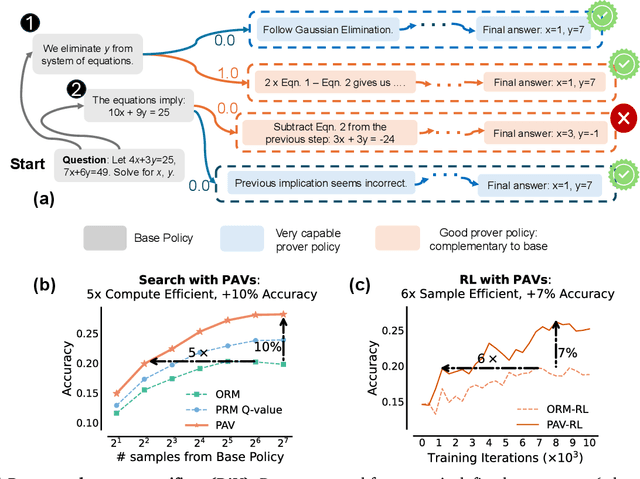
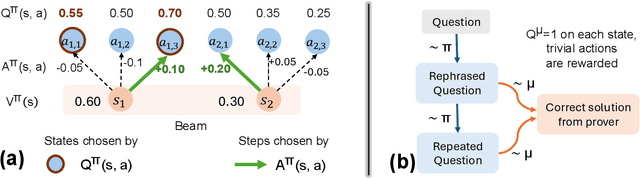
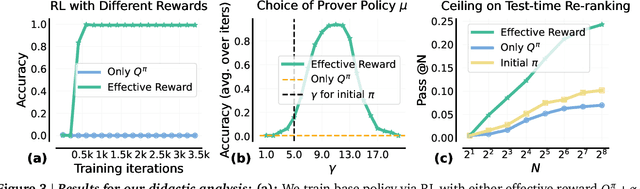
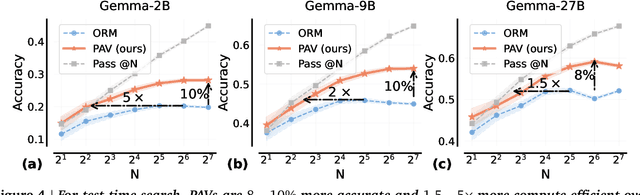
A promising approach for improving reasoning in large language models is to use process reward models (PRMs). PRMs provide feedback at each step of a multi-step reasoning trace, potentially improving credit assignment over outcome reward models (ORMs) that only provide feedback at the final step. However, collecting dense, per-step human labels is not scalable, and training PRMs from automatically-labeled data has thus far led to limited gains. To improve a base policy by running search against a PRM or using it as dense rewards for reinforcement learning (RL), we ask: "How should we design process rewards?". Our key insight is that, to be effective, the process reward for a step should measure progress: a change in the likelihood of producing a correct response in the future, before and after taking the step, corresponding to the notion of step-level advantages in RL. Crucially, this progress should be measured under a prover policy distinct from the base policy. We theoretically characterize the set of good provers and our results show that optimizing process rewards from such provers improves exploration during test-time search and online RL. In fact, our characterization shows that weak prover policies can substantially improve a stronger base policy, which we also observe empirically. We validate our claims by training process advantage verifiers (PAVs) to predict progress under such provers, and show that compared to ORMs, test-time search against PAVs is $>8\%$ more accurate, and $1.5-5\times$ more compute-efficient. Online RL with dense rewards from PAVs enables one of the first results with $5-6\times$ gain in sample efficiency, and $>6\%$ gain in accuracy, over ORMs.
Stratified Prediction-Powered Inference for Hybrid Language Model Evaluation
Jun 06, 2024

Prediction-powered inference (PPI) is a method that improves statistical estimates based on limited human-labeled data. PPI achieves this by combining small amounts of human-labeled data with larger amounts of data labeled by a reasonably accurate -- but potentially biased -- automatic system, in a way that results in tighter confidence intervals for certain parameters of interest (e.g., the mean performance of a language model). In this paper, we propose a method called Stratified Prediction-Powered Inference (StratPPI), in which we show that the basic PPI estimates can be considerably improved by employing simple data stratification strategies. Without making any assumptions on the underlying automatic labeling system or data distribution, we derive an algorithm for computing provably valid confidence intervals for population parameters (such as averages) that is based on stratified sampling. In particular, we show both theoretically and empirically that, with appropriate choices of stratification and sample allocation, our approach can provide substantially tighter confidence intervals than unstratified approaches. Specifically, StratPPI is expected to improve in cases where the performance of the autorater varies across different conditional distributions of the target data.
Block Transformer: Global-to-Local Language Modeling for Fast Inference
Jun 04, 2024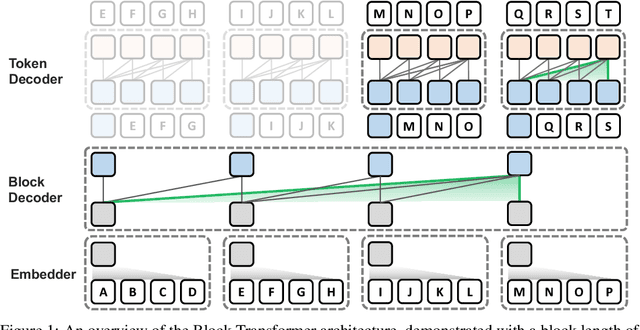
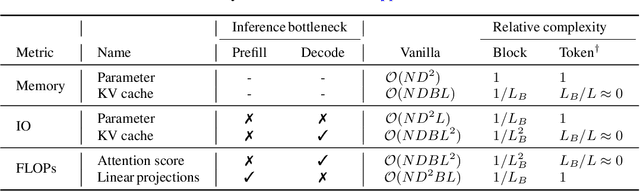
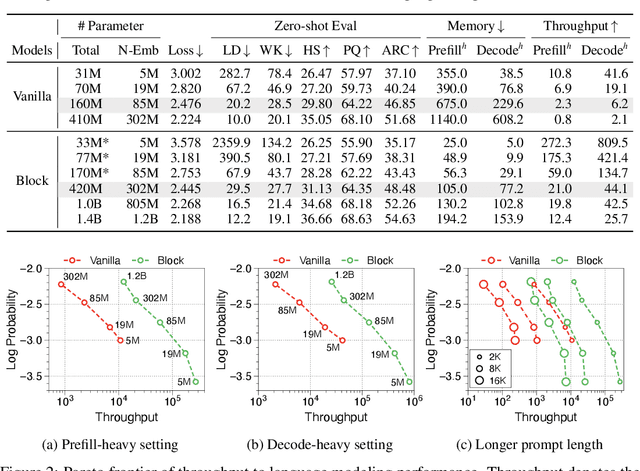
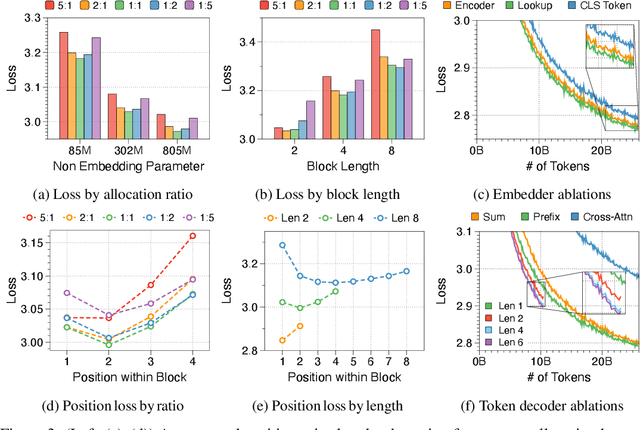
This paper presents the Block Transformer architecture which adopts hierarchical global-to-local modeling to autoregressive transformers to mitigate the inference bottlenecks of self-attention. To apply self-attention, the key-value (KV) cache of all previous sequences must be retrieved from memory at every decoding step. Thereby, this KV cache IO becomes a significant bottleneck in batch inference. We notice that these costs stem from applying self-attention on the global context, therefore we isolate the expensive bottlenecks of global modeling to lower layers and apply fast local modeling in upper layers. To mitigate the remaining costs in the lower layers, we aggregate input tokens into fixed size blocks and then apply self-attention at this coarse level. Context information is aggregated into a single embedding to enable upper layers to decode the next block of tokens, without global attention. Free of global attention bottlenecks, the upper layers can fully utilize the compute hardware to maximize inference throughput. By leveraging global and local modules, the Block Transformer architecture demonstrates 10-20x gains in inference throughput compared to vanilla transformers with equivalent perplexity. Our work introduces a new approach to optimize language model inference through novel application of global-to-local modeling. Code is available at https://github.com/itsnamgyu/block-transformer.