 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Architectures for Language Models: Systematic Analysis and Design Insights
Oct 06, 2025Recent progress in large language models demonstrates that hybrid architectures--combining self-attention mechanisms with structured state space models like Mamba--can achieve a compelling balance between modeling quality and computational efficiency, particularly for long-context tasks. While these hybrid models show promising performance, systematic comparisons of hybridization strategies and analyses on the key factors behind their effectiveness have not been clearly shared to the community. In this work, we present a holistic evaluation of hybrid architectures based on inter-layer (sequential) or intra-layer (parallel) fusion. We evaluate these designs from a variety of perspectives: language modeling performance, long-context capabilities, scaling analysis, and training and inference efficiency. By investigating the core characteristics of their computational primitive, we identify the most critical elements for each hybridization strategy and further propose optimal design recipes for both hybrid models. Our comprehensive analysis provides practical guidance and valuable insights for developing hybrid language models, facilitating the optimization of architectural configurations.
Graph Neural Network for Cerebral Blood Flow Prediction With Clinical Datasets
Nov 27, 2024

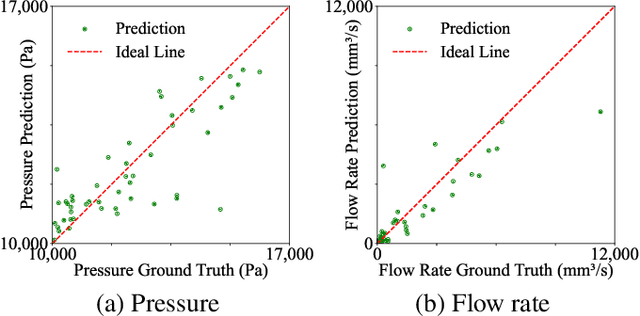
Accurate prediction of cerebral blood flow is essential for the diagnosis and treatment of cerebrovascular diseases. Traditional computational methods, however, often incur significant computational costs, limiting their practicality in real-time clinical applications. This paper proposes a graph neural network (GNN) to predict blood flow and pressure in previously unseen cerebral vascular network structures that were not included in training data. The GNN was developed using clinical datasets from patients with stenosis, featuring complex and abnormal vascular geometries. Additionally, the GNN model was trained on data incorporating a wide range of inflow conditions, vessel topologies, and network connectivities to enhance its generalization capability. The approach achieved Pearson's correlation coefficients of 0.727 for pressure and 0.824 for flow rate, with sufficient training data. These findings demonstrate the potential of the GNN for real-time cerebrovascular diagnostics, particularly in handling intricate and pathological vascular networks.
Relaxed Recursive Transformers: Effective Parameter Sharing with Layer-wise LoRA
Oct 28, 2024



Large language models (LLMs) are expensive to deploy. Parameter sharing offers a possible path towards reducing their size and cost, but its effectiveness in modern LLMs remains fairly limited. In this work, we revisit "layer tying" as form of parameter sharing in Transformers, and introduce novel methods for converting existing LLMs into smaller "Recursive Transformers" that share parameters across layers, with minimal loss of performance. Here, our Recursive Transformers are efficiently initialized from standard pretrained Transformers, but only use a single block of unique layers that is then repeated multiple times in a loop. We further improve performance by introducing Relaxed Recursive Transformers that add flexibility to the layer tying constraint via depth-wise low-rank adaptation (LoRA) modules, yet still preserve the compactness of the overall model. We show that our recursive models (e.g., recursive Gemma 1B) outperform both similar-sized vanilla pretrained models (such as TinyLlama 1.1B and Pythia 1B) and knowledge distillation baselines -- and can even recover most of the performance of the original "full-size" model (e.g., Gemma 2B with no shared parameters). Finally, we propose Continuous Depth-wise Batching, a promising new inference paradigm enabled by the Recursive Transformer when paired with early exiting. In a theoretical analysis, we show that this has the potential to lead to significant (2-3x) gains in inference throughput.
A Little Help Goes a Long Way: Efficient LLM Training by Leveraging Small LMs
Oct 24, 2024
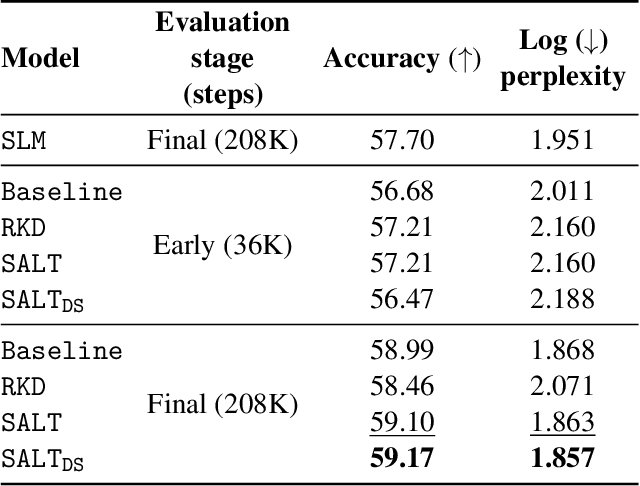

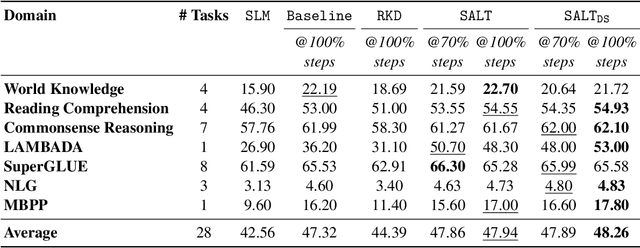
A primary challenge in large language model (LLM) development is their onerous pre-training cost. Typically, such pre-training involves optimizing a self-supervised objective (such as next-token prediction) over a large corpus. This paper explores a promising paradigm to improve LLM pre-training efficiency and quality by suitably leveraging a small language model (SLM). In particular, this paradigm relies on an SLM to both (1) provide soft labels as additional training supervision, and (2) select a small subset of valuable ("informative" and "hard") training examples. Put together, this enables an effective transfer of the SLM's predictive distribution to the LLM, while prioritizing specific regions of the training data distribution. Empirically, this leads to reduced LLM training time compared to standard training, while improving the overall quality. Theoretically, we develop a statistical framework to systematically study the utility of SLMs in enabling efficient training of high-quality LLMs. In particular, our framework characterizes how the SLM's seemingly low-quality supervision can enhance the training of a much more capable LLM. Furthermore, it also highlights the need for an adaptive utilization of such supervision, by striking a balance between the bias and variance introduced by the SLM-provided soft labels. We corroborate our theoretical framework by improving the pre-training of an LLM with 2.8B parameters by utilizing a smaller LM with 1.5B parameters on the Pile dataset.
Proleptic Temporal Ensemble for Improving the Speed of Robot Tasks Generated by Imitation Learning
Oct 22, 2024
Imitation learning, which enables robots to learn behaviors from demonstrations by non-experts, has emerged as a promising solution for generating robot motions in such environments. The imitation learning based robot motion generation method, however, has the drawback of being limited by the demonstrators task execution speed. This paper presents a novel temporal ensemble approach applied to imitation learning algorithms, allowing for execution of future actions. The proposed method leverages existing demonstration data and pretrained policies, offering the advantages of requiring no additional computation and being easy to implement. The algorithms performance was validated through real world experiments involving robotic block color sorting, demonstrating up to 3x increase in task execution speed while maintaining a high success rate compared to the action chunking with transformer method. This study highlights the potential for significantly improving the performance of imitation learning-based policies, which were previously limited by the demonstrator's speed. It is expected to contribute substantially to future advancements in autonomous object manipulation technologies aimed at enhancing productivity.
Analysis of Plan-based Retrieval for Grounded Text Generation
Aug 20, 2024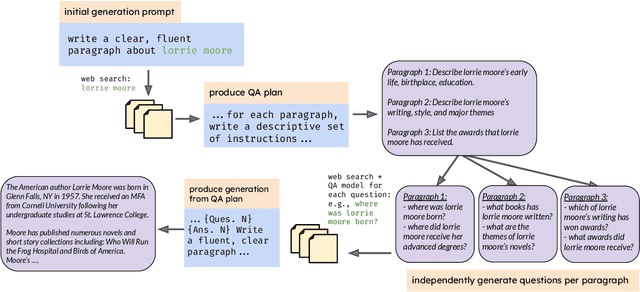
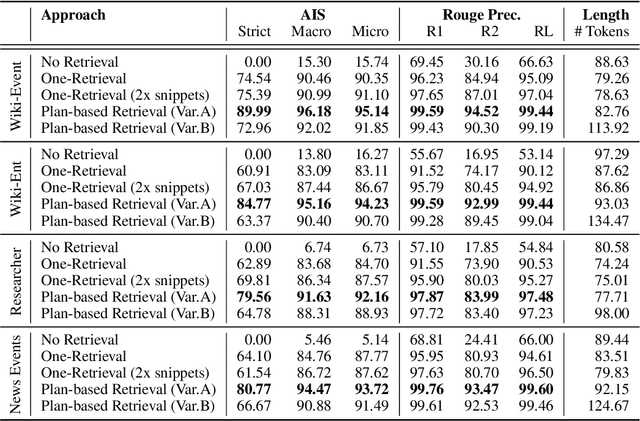

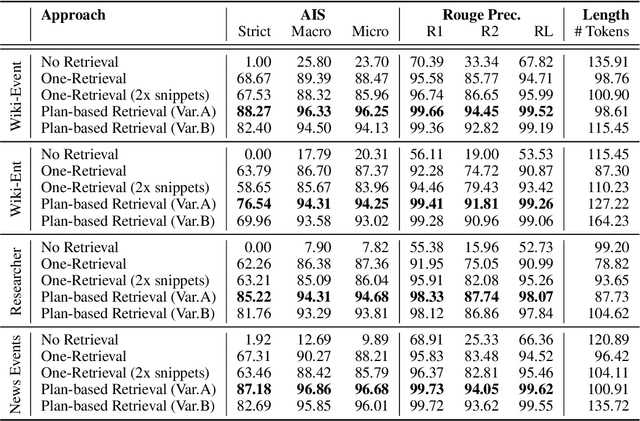
In text generation, hallucinations refer to the generation of seemingly coherent text that contradicts established knowledge. One compelling hypothesis is that hallucinations occur when a language model is given a generation task outside its parametric knowledge (due to rarity, recency, domain, etc.). A common strategy to address this limitation is to infuse the language models with retrieval mechanisms, providing the model with relevant knowledge for the task. In this paper, we leverage the planning capabilities of instruction-tuned LLMs and analyze how planning can be used to guide retrieval to further reduce the frequency of hallucinations. We empirically evaluate several variations of our proposed approach on long-form text generation tasks. By improving the coverage of relevant facts, plan-guided retrieval and generation can produce more informative responses while providing a higher rate of attribution to source documents.
Motion Manifold Flow Primitives for Language-Guided Trajectory Generation
Jul 29, 2024



Developing text-based robot trajectory generation models is made particularly difficult by the small dataset size, high dimensionality of the trajectory space, and the inherent complexity of the text-conditional motion distribution. Recent manifold learning-based methods have partially addressed the dimensionality and dataset size issues, but struggle with the complex text-conditional distribution. In this paper we propose a text-based trajectory generation model that attempts to address all three challenges while relying on only a handful of demonstration trajectory data. Our key idea is to leverage recent flow-based models capable of capturing complex conditional distributions, not directly in the high-dimensional trajectory space, but rather in the low-dimensional latent coordinate space of the motion manifold, with deliberately designed regularization terms to ensure smoothness of motions and robustness to text variations. We show that our {\it Motion Manifold Flow Primitive (MMFP)} framework can accurately generate qualitatively distinct motions for a wide range of text inputs, significantly outperforming existing methods.
Faster Cascades via Speculative Decoding
May 29, 2024

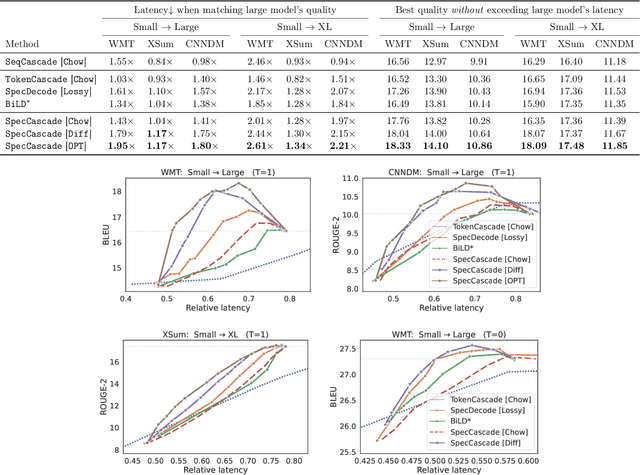

Cascades and speculative decoding are two common approaches to improving language models' inference efficiency. Both approaches involve interleaving models of different sizes, but via fundamentally distinct mechanisms: cascades employ a deferral rule that invokes the larger model only for "hard" inputs, while speculative decoding uses speculative execution to primarily invoke the larger model in parallel verification mode. These mechanisms offer different benefits: empirically, cascades are often capable of yielding better quality than even the larger model, while theoretically, speculative decoding offers a guarantee of quality-neutrality. In this paper, we leverage the best of both these approaches by designing new speculative cascading techniques that implement their deferral rule through speculative execution. We characterize the optimal deferral rule for our speculative cascades, and employ a plug-in approximation to the optimal rule. Through experiments with T5 models on benchmark language tasks, we show that the proposed approach yields better cost-quality trade-offs than cascading and speculative decoding baselines.
Supervision Complexity and its Role in Knowledge Distillation
Jan 28, 2023Despite the popularity and efficacy of knowledge distillation, there is limited understanding of why it helps. In order to study the generalization behavior of a distilled student, we propose a new theoretical framework that leverages supervision complexity: a measure of alignment between teacher-provided supervision and the student's neural tangent kernel. The framework highlights a delicate interplay among the teacher's accuracy, the student's margin with respect to the teacher predictions, and the complexity of the teacher predictions. Specifically, it provides a rigorous justification for the utility of various techniques that are prevalent in the context of distillation, such as early stopping and temperature scaling. Our analysis further suggests the use of online distillation, where a student receives increasingly more complex supervision from teachers in different stages of their training. We demonstrate efficacy of online distillation and validate the theoretical findings on a range of image classification benchmarks and model architectures.
EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval
Jan 27, 2023



Large neural models (such as Transformers) achieve state-of-the-art performance for information retrieval (IR). In this paper, we aim to improve distillation methods that pave the way for the deployment of such models in practice. The proposed distillation approach supports both retrieval and re-ranking stages and crucially leverages the relative geometry among queries and documents learned by the large teacher model. It goes beyond existing distillation methods in the IR literature, which simply rely on the teacher's scalar scores over the training data, on two fronts: providing stronger signals about local geometry via embedding matching and attaining better coverage of data manifold globally via query generation. Embedding matching provides a stronger signal to align the representations of the teacher and student models. At the same time, query generation explores the data manifold to reduce the discrepancies between the student and teacher where training data is sparse. Our distillation approach is theoretically justified and applies to both dual encoder (DE) and cross-encoder (CE) models. Furthermore, for distilling a CE model to a DE model via embedding matching, we propose a novel dual pooling-based scorer for the CE model that facilitates a distillation-friendly embedding geometry, especially for DE student models.