 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Model Merging
Apr 22, 2026In machine learning applications, privacy requirements during inference or deployment time could change constantly due to varying policies, regulations, or user experience. In this work, we aim to generate a magnitude of models to satisfy any target differential privacy (DP) requirement without additional training steps, given a set of existing models trained on the same dataset with different privacy/utility tradeoffs. We propose two post processing techniques, namely random selection and linear combination, to output a final private model for any target privacy parameter. We provide privacy accounting of these approaches from the lens of R'enyi DP and privacy loss distributions for general problems. In a case study on private mean estimation, we fully characterize the privacy/utility results and theoretically establish the superiority of linear combination over random selection. Empirically, we validate our approach and analyses on several models and both synthetic and real-world datasets.
Interleaved Head Attention
Feb 24, 2026Multi-Head Attention (MHA) is the core computational primitive underlying modern Large Language Models (LLMs). However, MHA suffers from a fundamental linear scaling limitation: $H$ attention heads produce exactly $H$ independent attention matrices, with no communication between heads during attention computation. This becomes problematic for multi-step reasoning, where correct answers depend on aggregating evidence from multiple parts of the context and composing latent token-to-token relations over a chain of intermediate inferences. To address this, we propose Interleaved Head Attention (IHA), which enables cross-head mixing by constructing $P$ pseudo-heads per head (typically $P=H$), where each pseudo query/key/value is a learned linear combination of all $H$ original queries, keys and values respectively. Interactions between pseudo-query and pseudo-key heads induce up to $P^2$ attention patterns per head with modest parameter overhead $\mathcal{O}(H^2P)$. We provide theory showing improved efficiency in terms of number of parameters on the synthetic Polynomial task (IHA uses $Θ(\sqrt{k}n^2)$ parameters vs. $Θ(kn^2)$ for MHA) and on the synthetic order-sensitive CPM-3 task (IHA uses $\lceil\sqrt{N_{\max}}\rceil$ heads vs. $N_{\max}$ for MHA). On real-world benchmarks, IHA improves Multi-Key retrieval on RULER by 10-20% (4k-16k) and, after fine-tuning for reasoning on OpenThoughts, improves GSM8K by 5.8% and MATH-500 by 2.8% (Majority Vote) over full attention.
Fast and Simplex: 2-Simplicial Attention in Triton
Jul 03, 2025Recent work has shown that training loss scales as a power law with both model size and the number of tokens, and that achieving compute-optimal models requires scaling model size and token count together. However, these scaling laws assume an infinite supply of data and apply primarily in compute-bound settings. As modern large language models increasingly rely on massive internet-scale datasets, the assumption that they are compute-bound is becoming less valid. This shift highlights the need for architectures that prioritize token efficiency. In this work, we investigate the use of the 2-simplicial Transformer, an architecture that generalizes standard dot-product attention to trilinear functions through an efficient Triton kernel implementation. We demonstrate that the 2-simplicial Transformer achieves better token efficiency than standard Transformers: for a fixed token budget, similarly sized models outperform their dot-product counterparts on tasks involving mathematics, coding, reasoning, and logic. We quantify these gains by demonstrating that $2$-simplicial attention changes the exponent in the scaling laws for knowledge and reasoning tasks compared to dot product attention.
Efficient Distributed Optimization under Heavy-Tailed Noise
Feb 06, 2025Distributed optimization has become the default training paradigm in modern machine learning due to the growing scale of models and datasets. To mitigate communication overhead, local updates are often applied before global aggregation, resulting in a nested optimization approach with inner and outer steps. However, heavy-tailed stochastic gradient noise remains a significant challenge, particularly in attention-based models, hindering effective training. In this work, we propose TailOPT, an efficient framework designed to address heavy-tailed noise by leveraging adaptive optimization or clipping techniques. We establish convergence guarantees for the TailOPT framework under heavy-tailed noise with potentially unbounded gradient variance and local updates. Among its variants, we highlight a memory and communication efficient instantiation which we call $Bi^2Clip$, which performs coordinate-wise clipping at both the inner and outer optimizers, achieving adaptive-like performance (e.g., Adam) without the cost of maintaining or transmitting additional gradient statistics. Empirically, TailOPT, including $Bi^2Clip$, demonstrates superior performance on several language tasks and models, outperforming state-of-the-art methods.
A Fresh Take on Stale Embeddings: Improving Dense Retriever Training with Corrector Networks
Sep 03, 2024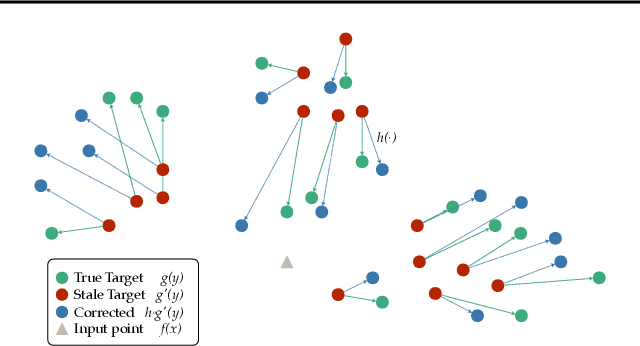
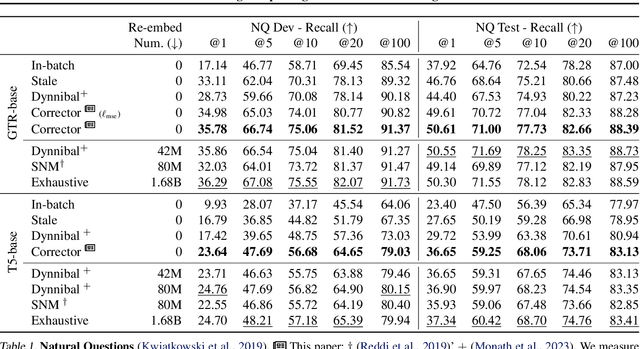
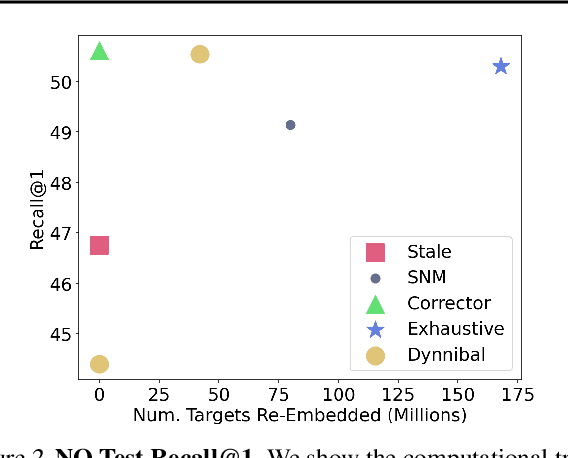
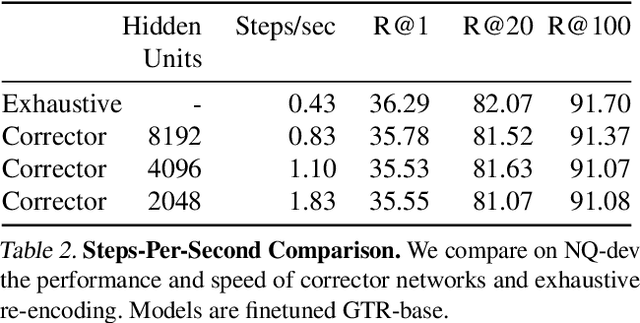
In dense retrieval, deep encoders provide embeddings for both inputs and targets, and the softmax function is used to parameterize a distribution over a large number of candidate targets (e.g., textual passages for information retrieval). Significant challenges arise in training such encoders in the increasingly prevalent scenario of (1) a large number of targets, (2) a computationally expensive target encoder model, (3) cached target embeddings that are out-of-date due to ongoing training of target encoder parameters. This paper presents a simple and highly scalable response to these challenges by training a small parametric corrector network that adjusts stale cached target embeddings, enabling an accurate softmax approximation and thereby sampling of up-to-date high scoring "hard negatives." We theoretically investigate the generalization properties of our proposed target corrector, relating the complexity of the network, staleness of cached representations, and the amount of training data. We present experimental results on large benchmark dense retrieval datasets as well as on QA with retrieval augmented language models. Our approach matches state-of-the-art results even when no target embedding updates are made during training beyond an initial cache from the unsupervised pre-trained model, providing a 4-80x reduction in re-embedding computational cost.
A Statistical Framework for Data-dependent Retrieval-Augmented Models
Aug 27, 2024Modern ML systems increasingly augment input instances with additional relevant information to enhance final prediction. Despite growing interest in such retrieval-augmented models, their fundamental properties and training are not well understood. We propose a statistical framework to study such models with two components: 1) a {\em retriever} to identify the relevant information out of a large corpus via a data-dependent metric; and 2) a {\em predictor} that consumes the input instances along with the retrieved information to make the final predictions. We present a principled method for end-to-end training of both components and draw connections with various training approaches in the literature. Furthermore, we establish excess risk bounds for retrieval-augmented models while delineating the contributions of both retriever and predictor towards the model performance. We validate the utility of our proposed training methods along with the key takeaways from our statistical analysis on open domain question answering task where retrieval augmentation is important.
Analysis of Plan-based Retrieval for Grounded Text Generation
Aug 20, 2024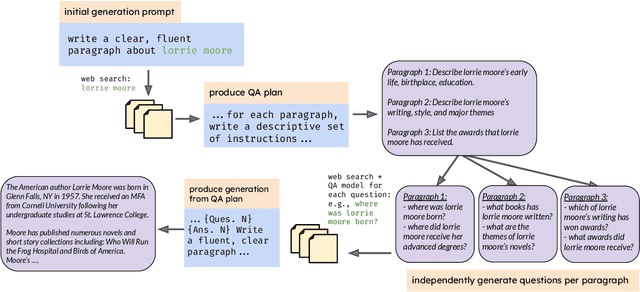
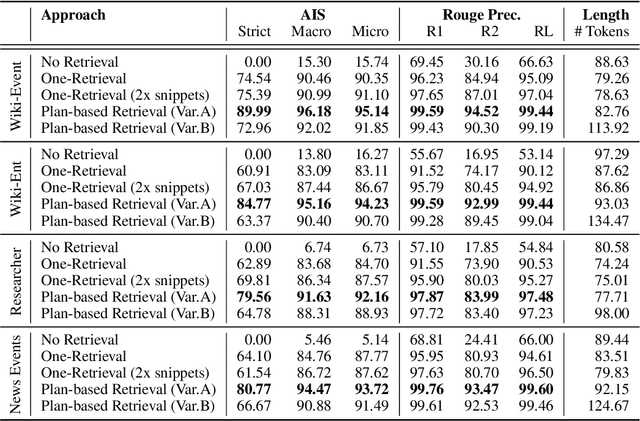

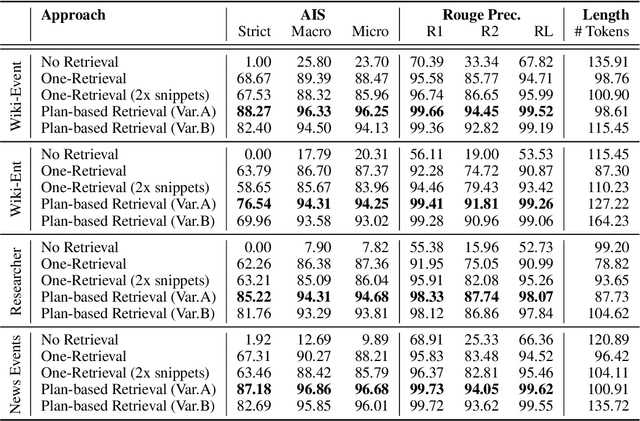
In text generation, hallucinations refer to the generation of seemingly coherent text that contradicts established knowledge. One compelling hypothesis is that hallucinations occur when a language model is given a generation task outside its parametric knowledge (due to rarity, recency, domain, etc.). A common strategy to address this limitation is to infuse the language models with retrieval mechanisms, providing the model with relevant knowledge for the task. In this paper, we leverage the planning capabilities of instruction-tuned LLMs and analyze how planning can be used to guide retrieval to further reduce the frequency of hallucinations. We empirically evaluate several variations of our proposed approach on long-form text generation tasks. By improving the coverage of relevant facts, plan-guided retrieval and generation can produce more informative responses while providing a higher rate of attribution to source documents.
Natural Language Outlines for Code: Literate Programming in the LLM Era
Aug 09, 2024



We propose using natural language outlines as a novel modality and interaction surface for providing AI assistance to developers throughout the software development process. An NL outline for a code function comprises multiple statements written in concise prose, which partition the code and summarize its main ideas in the style of literate programming. Crucially, we find that modern LLMs can generate accurate and high-quality NL outlines in practice. Moreover, NL outlines enable a bidirectional sync between code and NL, allowing changes in one to be automatically reflected in the other. We discuss many use cases for NL outlines: they can accelerate understanding and navigation of code and diffs, simplify code maintenance, augment code search, steer code generation, and more. We then propose and compare multiple LLM prompting techniques for generating outlines and ask professional developers to judge outline quality. Finally, we present two case studies applying NL outlines toward code review and the difficult task of malware detection.
Deep Reinforcement Learning for Sequential Combinatorial Auctions
Jul 10, 2024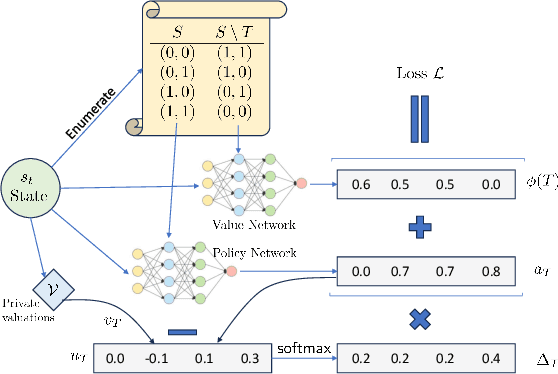
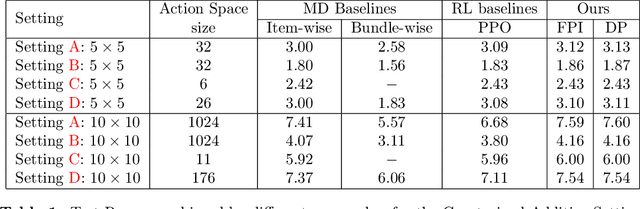
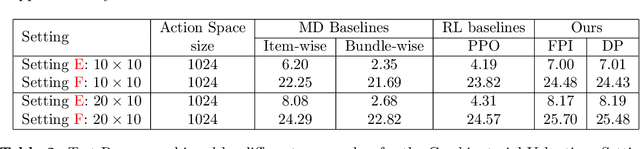

Revenue-optimal auction design is a challenging problem with significant theoretical and practical implications. Sequential auction mechanisms, known for their simplicity and strong strategyproofness guarantees, are often limited by theoretical results that are largely existential, except for certain restrictive settings. Although traditional reinforcement learning methods such as Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC) are applicable in this domain, they struggle with computational demands and convergence issues when dealing with large and continuous action spaces. In light of this and recognizing that we can model transitions differentiable for our settings, we propose using a new reinforcement learning framework tailored for sequential combinatorial auctions that leverages first-order gradients. Our extensive evaluations show that our approach achieves significant improvement in revenue over both analytical baselines and standard reinforcement learning algorithms. Furthermore, we scale our approach to scenarios involving up to 50 agents and 50 items, demonstrating its applicability in complex, real-world auction settings. As such, this work advances the computational tools available for auction design and contributes to bridging the gap between theoretical results and practical implementations in sequential auction design.
Adaptive Retrieval and Scalable Indexing for k-NN Search with Cross-Encoders
May 06, 2024Cross-encoder (CE) models which compute similarity by jointly encoding a query-item pair perform better than embedding-based models (dual-encoders) at estimating query-item relevance. Existing approaches perform k-NN search with CE by approximating the CE similarity with a vector embedding space fit either with dual-encoders (DE) or CUR matrix factorization. DE-based retrieve-and-rerank approaches suffer from poor recall on new domains and the retrieval with DE is decoupled from the CE. While CUR-based approaches can be more accurate than the DE-based approach, they require a prohibitively large number of CE calls to compute item embeddings, thus making it impractical for deployment at scale. In this paper, we address these shortcomings with our proposed sparse-matrix factorization based method that efficiently computes latent query and item embeddings to approximate CE scores and performs k-NN search with the approximate CE similarity. We compute item embeddings offline by factorizing a sparse matrix containing query-item CE scores for a set of train queries. Our method produces a high-quality approximation while requiring only a fraction of CE calls as compared to CUR-based methods, and allows for leveraging DE to initialize the embedding space while avoiding compute- and resource-intensive finetuning of DE via distillation. At test time, the item embeddings remain fixed and retrieval occurs over rounds, alternating between a) estimating the test query embedding by minimizing error in approximating CE scores of items retrieved thus far, and b) using the updated test query embedding for retrieving more items. Our k-NN search method improves recall by up to 5% (k=1) and 54% (k=100) over DE-based approaches. Additionally, our indexing approach achieves a speedup of up to 100x over CUR-based and 5x over DE distillation methods, while matching or improving k-NN search recall over baselines.