 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's (not) just put things in Context: Test-Time Training for Long-Context LLMs
Dec 15, 2025Progress on training and architecture strategies has enabled LLMs with millions of tokens in context length. However, empirical evidence suggests that such long-context LLMs can consume far more text than they can reliably use. On the other hand, it has been shown that inference-time compute can be used to scale performance of LLMs, often by generating thinking tokens, on challenging tasks involving multi-step reasoning. Through controlled experiments on sandbox long-context tasks, we find that such inference-time strategies show rapidly diminishing returns and fail at long context. We attribute these failures to score dilution, a phenomenon inherent to static self-attention. Further, we show that current inference-time strategies cannot retrieve relevant long-context signals under certain conditions. We propose a simple method that, through targeted gradient updates on the given context, provably overcomes limitations of static self-attention. We find that this shift in how inference-time compute is spent leads to consistently large performance improvements across models and long-context benchmarks. Our method leads to large 12.6 and 14.1 percentage point improvements for Qwen3-4B on average across subsets of LongBench-v2 and ZeroScrolls benchmarks. The takeaway is practical: for long context, a small amount of context-specific training is a better use of inference compute than current inference-time scaling strategies like producing more thinking tokens.
Fast and Simplex: 2-Simplicial Attention in Triton
Jul 03, 2025Recent work has shown that training loss scales as a power law with both model size and the number of tokens, and that achieving compute-optimal models requires scaling model size and token count together. However, these scaling laws assume an infinite supply of data and apply primarily in compute-bound settings. As modern large language models increasingly rely on massive internet-scale datasets, the assumption that they are compute-bound is becoming less valid. This shift highlights the need for architectures that prioritize token efficiency. In this work, we investigate the use of the 2-simplicial Transformer, an architecture that generalizes standard dot-product attention to trilinear functions through an efficient Triton kernel implementation. We demonstrate that the 2-simplicial Transformer achieves better token efficiency than standard Transformers: for a fixed token budget, similarly sized models outperform their dot-product counterparts on tasks involving mathematics, coding, reasoning, and logic. We quantify these gains by demonstrating that $2$-simplicial attention changes the exponent in the scaling laws for knowledge and reasoning tasks compared to dot product attention.
LASER: Attention with Exponential Transformation
Nov 05, 2024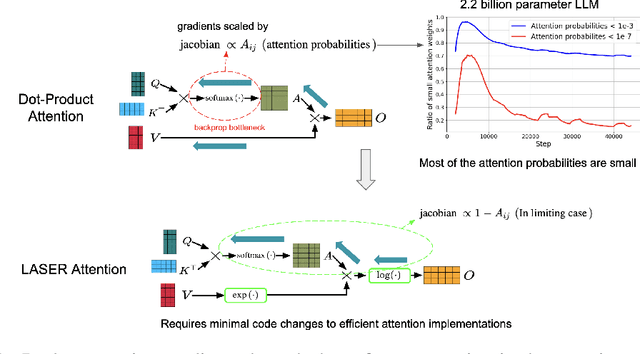

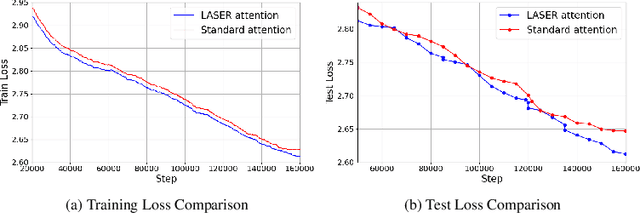
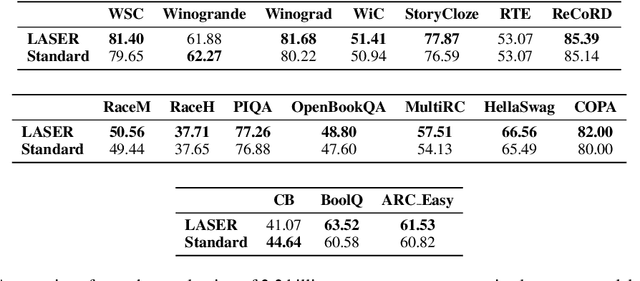
Transformers have had tremendous impact for several sequence related tasks, largely due to their ability to retrieve from any part of the sequence via softmax based dot-product attention. This mechanism plays a crucial role in Transformer's performance. We analyze the gradients backpropagated through the softmax operation in the attention mechanism and observe that these gradients can often be small. This poor gradient signal backpropagation can lead to inefficient learning of parameters preceeding the attention operations. To this end, we introduce a new attention mechanism called LASER, which we analytically show to admit a larger gradient signal. We show that LASER Attention can be implemented by making small modifications to existing attention implementations. We conduct experiments on autoregressive large language models (LLMs) with upto 2.2 billion parameters where we show upto 3.38% and an average of ~1% improvement over standard attention on downstream evaluations. Using LASER gives the following relative improvements in generalization performance across a variety of tasks (vision, text and speech): 4.67% accuracy in Vision Transformer (ViT) on Imagenet, 2.25% error rate in Conformer on the Librispeech speech-to-text and 0.93% fraction of incorrect predictions in BERT with 2.2 billion parameters.
LoRA Done RITE: Robust Invariant Transformation Equilibration for LoRA Optimization
Oct 27, 2024Low-rank adaption (LoRA) is a widely used parameter-efficient finetuning method for LLM that reduces memory requirements. However, current LoRA optimizers lack transformation invariance, meaning the actual updates to the weights depends on how the two LoRA factors are scaled or rotated. This deficiency leads to inefficient learning and sub-optimal solutions in practice. This paper introduces LoRA-RITE, a novel adaptive matrix preconditioning method for LoRA optimization, which can achieve transformation invariance and remain computationally efficient. We provide theoretical analysis to demonstrate the benefit of our method and conduct experiments on various LLM tasks with different models including Gemma 2B, 7B, and mT5-XXL. The results demonstrate consistent improvements against existing optimizers. For example, replacing Adam with LoRA-RITE during LoRA fine-tuning of Gemma-2B yielded 4.6\% accuracy gain on Super-Natural Instructions and 3.5\% accuracy gain across other four LLM benchmarks (HellaSwag, ArcChallenge, GSM8K, OpenBookQA).
A Computationally Efficient Sparsified Online Newton Method
Nov 16, 2023Second-order methods hold significant promise for enhancing the convergence of deep neural network training; however, their large memory and computational demands have limited their practicality. Thus there is a need for scalable second-order methods that can efficiently train large models. In this paper, we introduce the Sparsified Online Newton (SONew) method, a memory-efficient second-order algorithm that yields a sparsified yet effective preconditioner. The algorithm emerges from a novel use of the LogDet matrix divergence measure; we combine it with sparsity constraints to minimize regret in the online convex optimization framework. Empirically, we test our method on large scale benchmarks of up to 1B parameters. We achieve up to 30% faster convergence, 3.4% relative improvement in validation performance, and 80% relative improvement in training loss, in comparison to memory efficient optimizers including first order methods. Powering the method is a surprising fact -- imposing structured sparsity patterns, like tridiagonal and banded structure, requires little to no overhead, making it as efficient and parallelizable as first-order methods. In wall-clock time, tridiagonal SONew is only about 3% slower per step than first-order methods but gives overall gains due to much faster convergence. In contrast, one of the state-of-the-art (SOTA) memory-intensive second-order methods, Shampoo, is unable to scale to large benchmarks. Additionally, while Shampoo necessitates significant engineering efforts to scale to large benchmarks, SONew offers a more straightforward implementation, increasing its practical appeal. SONew code is available at: https://github.com/devvrit/SONew