 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Interpretable Learners
Jun 25, 2024The trade-off between expressiveness and interpretability remains a core challenge when building human-centric predictive models for classification and decision-making. While symbolic rules offer interpretability, they often lack expressiveness, whereas neural networks excel in performance but are known for being black boxes. In this paper, we show a combination of Large Language Models (LLMs) and symbolic programs can bridge this gap. In the proposed LLM-based Symbolic Programs (LSPs), the pretrained LLM with natural language prompts provides a massive set of interpretable modules that can transform raw input into natural language concepts. Symbolic programs then integrate these modules into an interpretable decision rule. To train LSPs, we develop a divide-and-conquer approach to incrementally build the program from scratch, where the learning process of each step is guided by LLMs. To evaluate the effectiveness of LSPs in extracting interpretable and accurate knowledge from data, we introduce IL-Bench, a collection of diverse tasks, including both synthetic and real-world scenarios across different modalities. Empirical results demonstrate LSP's superior performance compared to traditional neurosymbolic programs and vanilla automatic prompt tuning methods. Moreover, as the knowledge learned by LSP is a combination of natural language descriptions and symbolic rules, it is easily transferable to humans (interpretable), and other LLMs, and generalizes well to out-of-distribution samples.
A Computationally Efficient Sparsified Online Newton Method
Nov 16, 2023Second-order methods hold significant promise for enhancing the convergence of deep neural network training; however, their large memory and computational demands have limited their practicality. Thus there is a need for scalable second-order methods that can efficiently train large models. In this paper, we introduce the Sparsified Online Newton (SONew) method, a memory-efficient second-order algorithm that yields a sparsified yet effective preconditioner. The algorithm emerges from a novel use of the LogDet matrix divergence measure; we combine it with sparsity constraints to minimize regret in the online convex optimization framework. Empirically, we test our method on large scale benchmarks of up to 1B parameters. We achieve up to 30% faster convergence, 3.4% relative improvement in validation performance, and 80% relative improvement in training loss, in comparison to memory efficient optimizers including first order methods. Powering the method is a surprising fact -- imposing structured sparsity patterns, like tridiagonal and banded structure, requires little to no overhead, making it as efficient and parallelizable as first-order methods. In wall-clock time, tridiagonal SONew is only about 3% slower per step than first-order methods but gives overall gains due to much faster convergence. In contrast, one of the state-of-the-art (SOTA) memory-intensive second-order methods, Shampoo, is unable to scale to large benchmarks. Additionally, while Shampoo necessitates significant engineering efforts to scale to large benchmarks, SONew offers a more straightforward implementation, increasing its practical appeal. SONew code is available at: https://github.com/devvrit/SONew
EHI: End-to-end Learning of Hierarchical Index for Efficient Dense Retrieval
Oct 13, 2023Dense embedding-based retrieval is now the industry standard for semantic search and ranking problems, like obtaining relevant web documents for a given query. Such techniques use a two-stage process: (a) contrastive learning to train a dual encoder to embed both the query and documents and (b) approximate nearest neighbor search (ANNS) for finding similar documents for a given query. These two stages are disjoint; the learned embeddings might be ill-suited for the ANNS method and vice-versa, leading to suboptimal performance. In this work, we propose End-to-end Hierarchical Indexing -- EHI -- that jointly learns both the embeddings and the ANNS structure to optimize retrieval performance. EHI uses a standard dual encoder model for embedding queries and documents while learning an inverted file index (IVF) style tree structure for efficient ANNS. To ensure stable and efficient learning of discrete tree-based ANNS structure, EHI introduces the notion of dense path embedding that captures the position of a query/document in the tree. We demonstrate the effectiveness of EHI on several benchmarks, including de-facto industry standard MS MARCO (Dev set and TREC DL19) datasets. For example, with the same compute budget, EHI outperforms state-of-the-art (SOTA) in by 0.6% (MRR@10) on MS MARCO dev set and by 4.2% (nDCG@10) on TREC DL19 benchmarks.
MatFormer: Nested Transformer for Elastic Inference
Oct 11, 2023



Transformer models are deployed in a wide range of settings, from multi-accelerator clusters to standalone mobile phones. The diverse inference constraints in these scenarios necessitate practitioners to train foundation models such as PaLM 2, Llama, & ViTs as a series of models of varying sizes. Due to significant training costs, only a select few model sizes are trained and supported, limiting more fine-grained control over relevant tradeoffs, including latency, cost, and accuracy. This work introduces MatFormer, a nested Transformer architecture designed to offer elasticity in a variety of deployment constraints. Each Feed Forward Network (FFN) block of a MatFormer model is jointly optimized with a few nested smaller FFN blocks. This training procedure allows for the Mix'n'Match of model granularities across layers -- i.e., a trained universal MatFormer model enables extraction of hundreds of accurate smaller models, which were never explicitly optimized. We empirically demonstrate MatFormer's effectiveness across different model classes (decoders & encoders), modalities (language & vision), and scales (up to 2.6B parameters). We find that a 2.6B decoder-only MatFormer language model (MatLM) allows us to extract smaller models spanning from 1.5B to 2.6B, each exhibiting comparable validation loss and one-shot downstream evaluations to their independently trained counterparts. Furthermore, we observe that smaller encoders extracted from a universal MatFormer-based ViT (MatViT) encoder preserve the metric-space structure for adaptive large-scale retrieval. Finally, we showcase that speculative decoding with the accurate and consistent submodels extracted from MatFormer can further reduce inference latency.
Bayesian regularization of empirical MDPs
Aug 03, 2022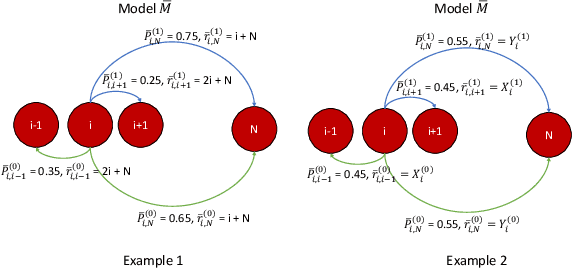
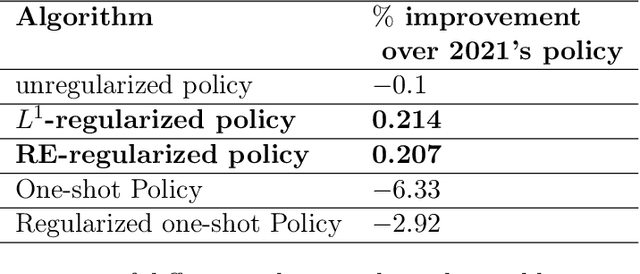
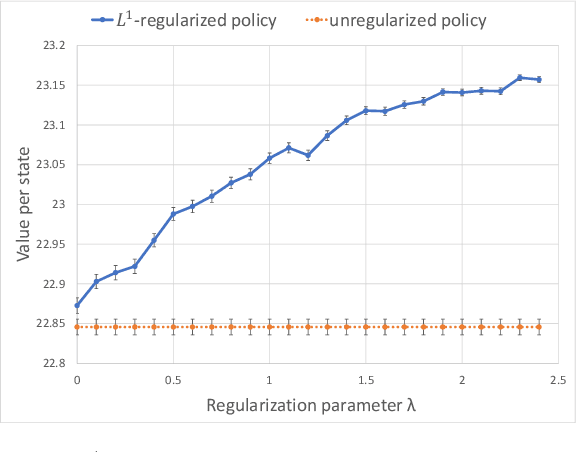
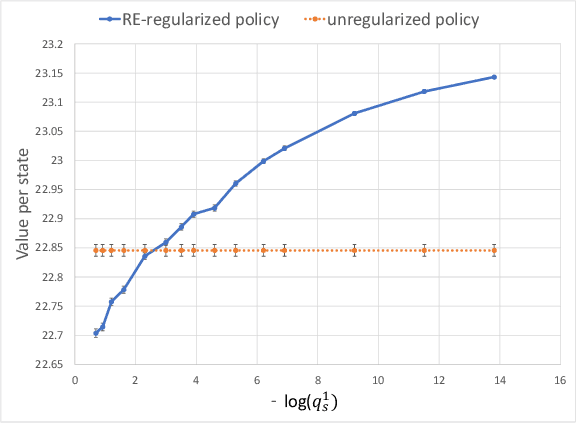
In most applications of model-based Markov decision processes, the parameters for the unknown underlying model are often estimated from the empirical data. Due to noise, the policy learnedfrom the estimated model is often far from the optimal policy of the underlying model. When applied to the environment of the underlying model, the learned policy results in suboptimal performance, thus calling for solutions with better generalization performance. In this work we take a Bayesian perspective and regularize the objective function of the Markov decision process with prior information in order to obtain more robust policies. Two approaches are proposed, one based on $L^1$ regularization and the other on relative entropic regularization. We evaluate our proposed algorithms on synthetic simulations and on real-world search logs of a large scale online shopping store. Our results demonstrate the robustness of regularized MDP policies against the noise present in the models.
Positive Unlabeled Contrastive Learning
Jun 01, 2022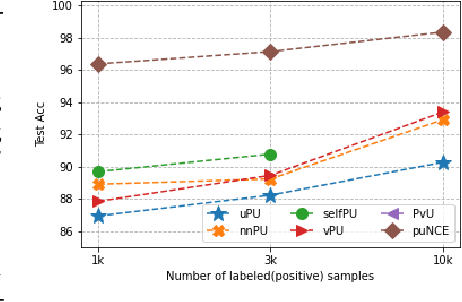
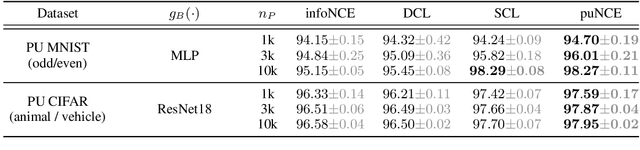
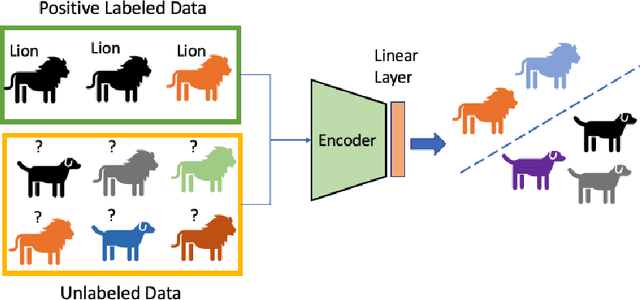
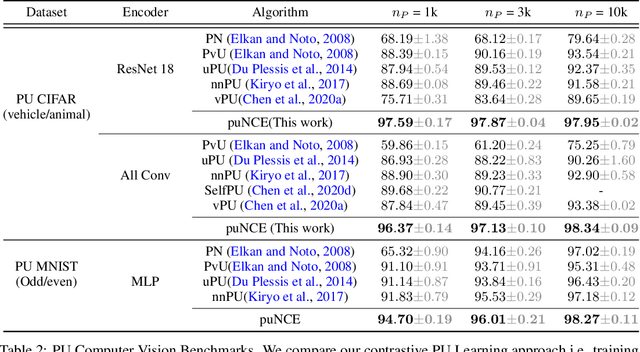
Self-supervised pretraining on unlabeled data followed by supervised finetuning on labeled data is a popular paradigm for learning from limited labeled examples. In this paper, we investigate and extend this paradigm to the classical positive unlabeled (PU) setting - the weakly supervised task of learning a binary classifier only using a few labeled positive examples and a set of unlabeled samples. We propose a novel PU learning objective positive unlabeled Noise Contrastive Estimation (puNCE) that leverages the available explicit (from labeled samples) and implicit (from unlabeled samples) supervision to learn useful representations from positive unlabeled input data. The underlying idea is to assign each training sample an individual weight; labeled positives are given unit weight; unlabeled samples are duplicated, one copy is labeled positive and the other as negative with weights $\pi$ and $(1-\pi)$ where $\pi$ denotes the class prior. Extensive experiments across vision and natural language tasks reveal that puNCE consistently improves over existing unsupervised and supervised contrastive baselines under limited supervision.
Accelerating Primal-dual Methods for Regularized Markov Decision Processes
Feb 21, 2022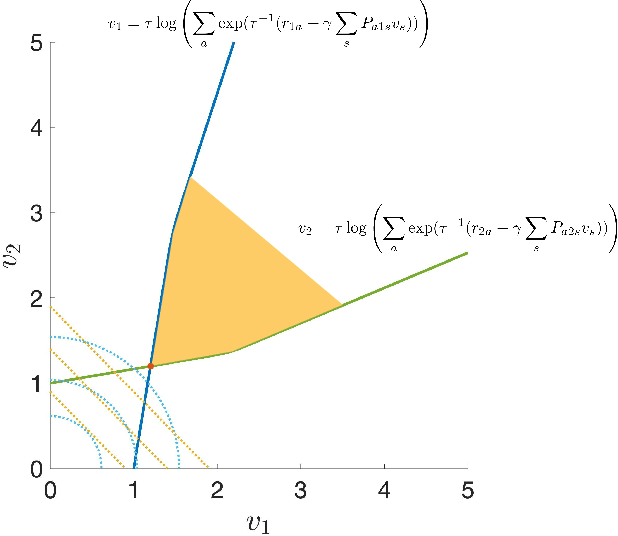
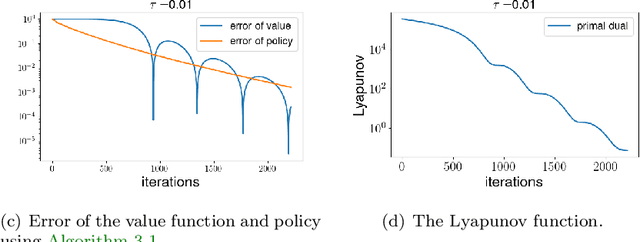
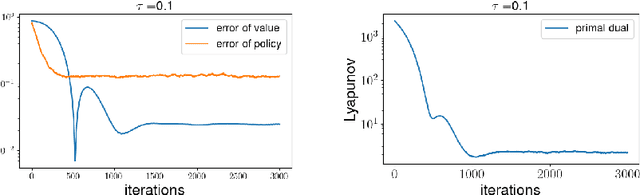
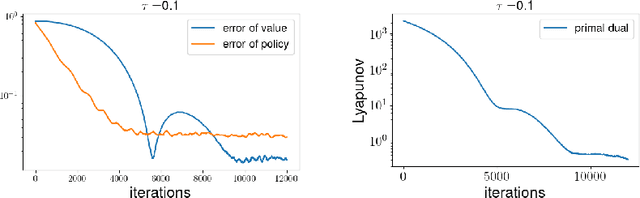
Entropy regularized Markov decision processes have been widely used in reinforcement learning. This paper is concerned with the primal-dual formulation of the entropy regularized problems. Standard first-order methods suffer from slow convergence due to the lack of strict convexity and concavity. To address this issue, we first introduce a new quadratically convexified primal-dual formulation. The natural gradient ascent descent of the new formulation enjoys global convergence guarantee and exponential convergence rate. We also propose a new interpolating metric that further accelerates the convergence significantly. Numerical results are provided to demonstrate the performance of the proposed methods under multiple settings.
Extreme Zero-Shot Learning for Extreme Text Classification
Dec 16, 2021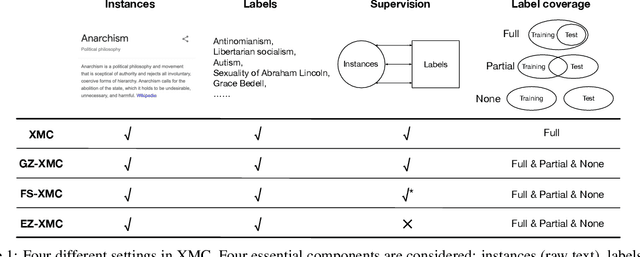
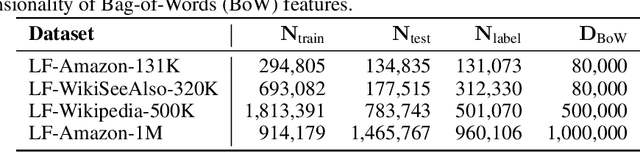
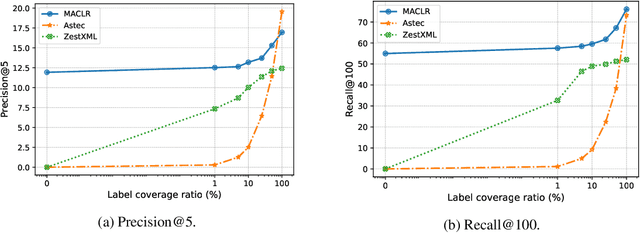
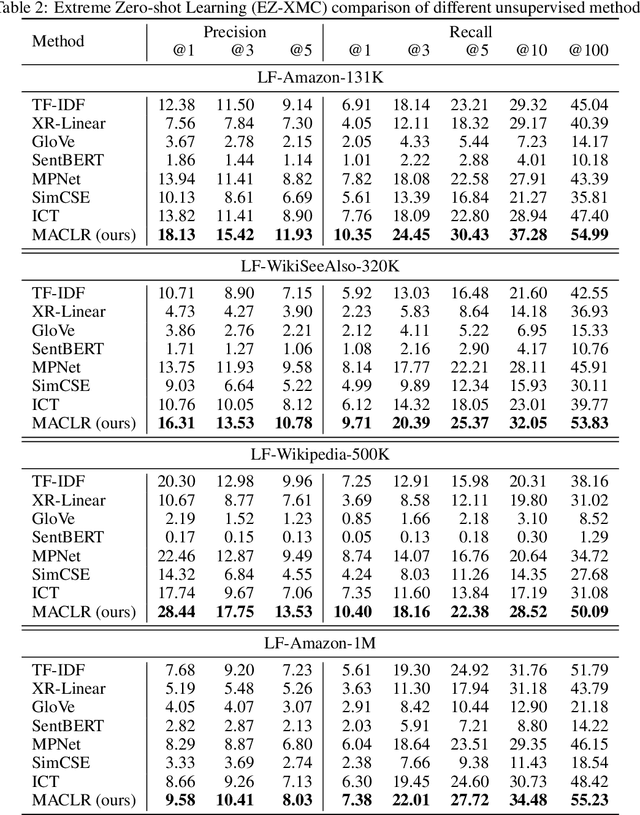
The eXtreme Multi-label text Classification (XMC) problem concerns finding most relevant labels for an input text instance from a large label set. However, the XMC setup faces two challenges: (1) it is not generalizable to predict unseen labels in dynamic environments, and (2) it requires a large amount of supervised (instance, label) pairs, which can be difficult to obtain for emerging domains. Recently, the generalized zero-shot XMC (GZ-XMC) setup has been studied and ZestXML is proposed accordingly to handle the unseen labels, which still requires a large number of annotated (instance, label) pairs. In this paper, we consider a more practical scenario called Extreme Zero-Shot XMC (EZ-XMC), in which no supervision is needed and merely raw text of instances and labels are accessible. Few-Shot XMC (FS-XMC), an extension to EZ-XMC with limited supervision is also investigated. To learn the semantic embeddings of instances and labels with raw text, we propose to pre-train Transformer-based encoders with self-supervised contrastive losses. Specifically, we develop a pre-training method MACLR, which thoroughly leverages the raw text with techniques including Multi-scale Adaptive Clustering, Label Regularization, and self-training with pseudo positive pairs. Experimental results on four public EZ-XMC datasets demonstrate that MACLR achieves superior performance compared to all other leading baseline methods, in particular with approximately 5-10% improvement in precision and recall on average. Moreover, we also show that our pre-trained encoder can be further improved on FS-XMC when there are a limited number of ground-truth positive pairs in training. By fine-tuning the encoder on such a few-shot subset, MACLR still outperforms other extreme classifiers significantly.
Quasi-Newton policy gradient algorithms
Oct 12, 2021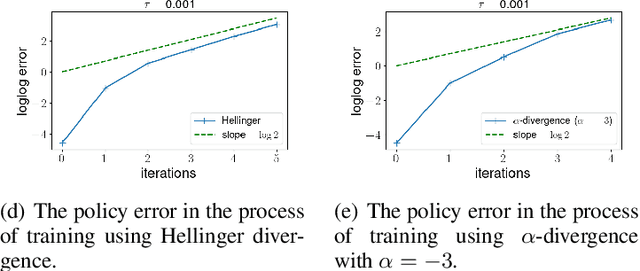

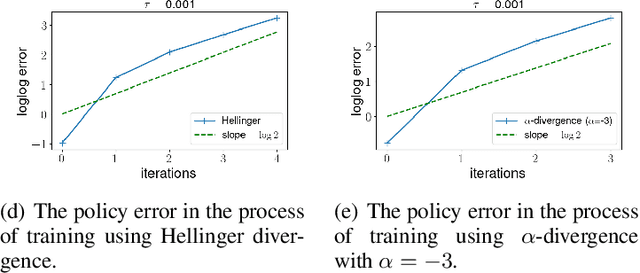
Policy gradient algorithms have been widely applied to reinforcement learning (RL) problems in recent years. Regularization with various entropy functions is often used to encourage exploration and improve stability. In this paper, we propose a quasi-Newton method for the policy gradient algorithm with entropy regularization. In the case of Shannon entropy, the resulting algorithm reproduces the natural policy gradient (NPG) algorithm. For other entropy functions, this method results in brand new policy gradient algorithms. We provide a simple proof that all these algorithms enjoy the Newton-type quadratic convergence near the optimal policy. Using synthetic and industrial-scale examples, we demonstrate that the proposed quasi-Newton method typically converges in single-digit iterations, often orders of magnitude faster than other state-of-the-art algorithms.
Accelerating Inference for Sparse Extreme Multi-Label Ranking Trees
Jun 09, 2021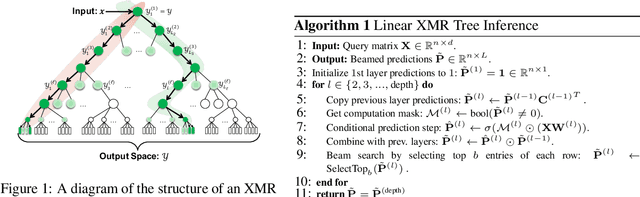

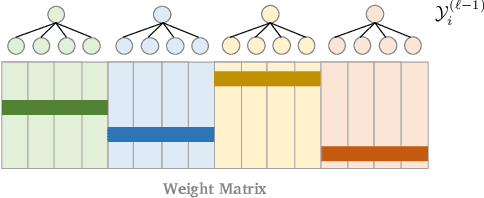
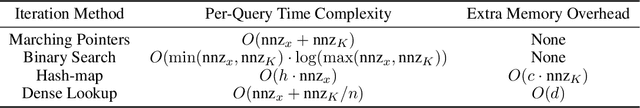
Tree-based models underpin many modern semantic search engines and recommender systems due to their sub-linear inference times. In industrial applications, these models operate at extreme scales, where every bit of performance is critical. Memory constraints at extreme scales also require that models be sparse, hence tree-based models are often back-ended by sparse matrix algebra routines. However, there are currently no sparse matrix techniques specifically designed for the sparsity structure one encounters in tree-based models for extreme multi-label ranking/classification (XMR/XMC) problems. To address this issue, we present the masked sparse chunk multiplication (MSCM) technique, a sparse matrix technique specifically tailored to XMR trees. MSCM is easy to implement, embarrassingly parallelizable, and offers a significant performance boost to any existing tree inference pipeline at no cost. We perform a comprehensive study of MSCM applied to several different sparse inference schemes and benchmark our methods on a general purpose extreme multi-label ranking framework. We observe that MSCM gives consistently dramatic speedups across both the online and batch inference settings, single- and multi-threaded settings, and on many different tree models and datasets. To demonstrate its utility in industrial applications, we apply MSCM to an enterprise-scale semantic product search problem with 100 million products and achieve sub-millisecond latency of 0.88 ms per query on a single thread -- an 8x reduction in latency over vanilla inference techniques. The MSCM technique requires absolutely no sacrifices to model accuracy as it gives exactly the same results as standard sparse matrix techniques. Therefore, we believe that MSCM will enable users of XMR trees to save a substantial amount of compute resources in their inference pipelines at very little cost.