 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcepts or Skills? Rethinking Instruction Selection for Multi-modal Models
Aug 14, 2025Vision-language instruction tuning achieves two main purposes: learning visual concepts and learning visual skills. In this paper, we found that vision-language benchmarks fall into the dichotomy of mainly benefiting from training on instructions with similar skills or visual concepts. Inspired by the discovery, we designed a simple targeted training data selection method to optimize the performance of a given benchmark. We first extract the concepts/skills from the benchmark, determine whether the benchmark predominantly benefits from similar concepts or skills, and finally select instructions with the most matching concepts/skills. Experiments on 10+ benchmarks validate the effectiveness of our targeted data selection method, showing +0.9\% over the best existing baseline averaged over all benchmarks and +1.5\% on the skill-focused subset. Our findings underscore the importance of recognizing the inherent trade-off within instruction selection, which requires balancing the acquisition of conceptual knowledge against visual skill.
Don't Think Longer, Think Wisely: Optimizing Thinking Dynamics for Large Reasoning Models
May 27, 2025While recent success of large reasoning models (LRMs) significantly advanced LLMs' reasoning capability by optimizing the final answer accuracy using reinforcement learning, they may also drastically increase the output length due to overthinking, characterized by unnecessarily complex reasoning paths that waste computation and potentially degrade the performance. We hypothesize that such inefficiencies stem from LRMs' limited capability to dynamically select the proper modular reasoning strategies, termed thinking patterns at the right position. To investigate this hypothesis, we propose a dynamic optimization framework that segments model-generated reasoning paths into distinct thinking patterns, systematically identifying and promoting beneficial patterns that improve the answer while removing detrimental ones. Empirical analysis confirms that our optimized thinking paths yield more concise yet sufficiently informative trajectories, enhancing reasoning efficiency by reducing attention FLOPs by up to 47% while maintaining accuracy for originally correct responses. Moreover, a non-trivial portion of originally incorrect responses are transformed into correct ones, achieving a 15.6% accuracy improvement with reduced length. Motivated by the improvement brought by the optimized thinking paths, we apply a preference optimization technique supported by a pairwise dataset contrasting suboptimal and optimal reasoning paths. Experimental evaluations across multiple mathematical reasoning benchmarks reveal that our method notably reduces computational overhead while simultaneously improving reasoning accuracy, achieving up to a 12% accuracy improvement and reducing token usage from approximately 5,000 to 3,000 tokens.
Addressing Challenges in Time Series Forecasting: A Comprehensive Comparison of Machine Learning Techniques
Mar 26, 2025


The explosion of Time Series (TS) data, driven by advancements in technology, necessitates sophisticated analytical methods. Modern management systems increasingly rely on analyzing this data, highlighting the importance of effcient processing techniques. State-of-the-art Machine Learning (ML) approaches for TS analysis and forecasting are becoming prevalent. This paper briefly describes and compiles suitable algorithms for TS regression task. We compare these algorithms against each other and the classic ARIMA method using diverse datasets: complete data, data with outliers, and data with missing values. The focus is on forecasting accuracy, particularly for long-term predictions. This research aids in selecting the most appropriate algorithm based on forecasting needs and data characteristics.
R1-Zero's "Aha Moment" in Visual Reasoning on a 2B Non-SFT Model
Mar 07, 2025Recently DeepSeek R1 demonstrated how reinforcement learning with simple rule-based incentives can enable autonomous development of complex reasoning in large language models, characterized by the "aha moment", in which the model manifest self-reflection and increased response length during training. However, attempts to extend this success to multimodal reasoning often failed to reproduce these key characteristics. In this report, we present the first successful replication of these emergent characteristics for multimodal reasoning on only a non-SFT 2B model. Starting with Qwen2-VL-2B and applying reinforcement learning directly on the SAT dataset, our model achieves 59.47% accuracy on CVBench, outperforming the base model by approximately ~30% and exceeding both SFT setting by ~2%. In addition, we share our failed attempts and insights in attempting to achieve R1-like reasoning using RL with instruct models. aiming to shed light on the challenges involved. Our key observations include: (1) applying RL on instruct model often results in trivial reasoning trajectories, and (2) naive length reward are ineffective in eliciting reasoning capabilities. The project code is available at https://github.com/turningpoint-ai/VisualThinker-R1-Zero
Solving for X and Beyond: Can Large Language Models Solve Complex Math Problems with More-Than-Two Unknowns?
Jul 06, 2024Large Language Models (LLMs) have demonstrated remarkable performance in solving math problems, a hallmark of human intelligence. Despite high success rates on current benchmarks; however, these often feature simple problems with only one or two unknowns, which do not sufficiently challenge their reasoning capacities. This paper introduces a novel benchmark, BeyondX, designed to address these limitations by incorporating problems with multiple unknowns. Recognizing the challenges in proposing multi-unknown problems from scratch, we developed BeyondX using an innovative automated pipeline that progressively increases complexity by expanding the number of unknowns in simpler problems. Empirical study on BeyondX reveals that the performance of existing LLMs, even those fine-tuned specifically on math tasks, significantly decreases as the number of unknowns increases - with a performance drop of up to 70\% observed in GPT-4. To tackle these challenges, we propose the Formulate-and-Solve strategy, a generalized prompting approach that effectively handles problems with an arbitrary number of unknowns. Our findings reveal that this strategy not only enhances LLM performance on the BeyondX benchmark but also provides deeper insights into the computational limits of LLMs when faced with more complex mathematical challenges.
One Prompt is not Enough: Automated Construction of a Mixture-of-Expert Prompts
Jun 28, 2024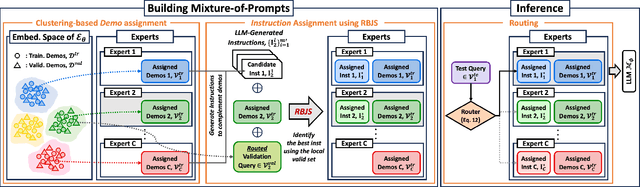
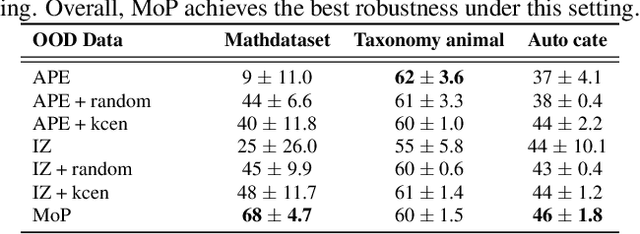
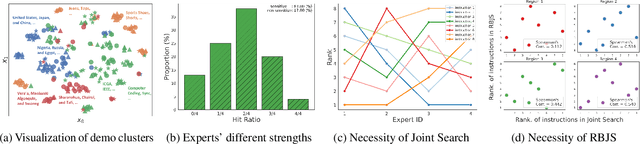
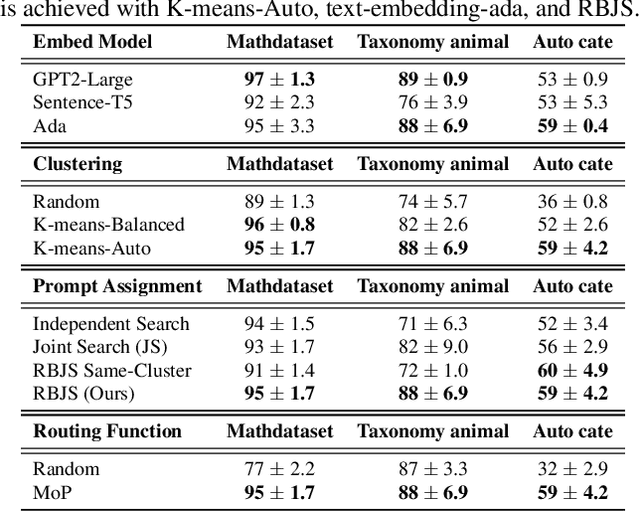
Large Language Models (LLMs) exhibit strong generalization capabilities to novel tasks when prompted with language instructions and in-context demos. Since this ability sensitively depends on the quality of prompts, various methods have been explored to automate the instruction design. While these methods demonstrated promising results, they also restricted the searched prompt to one instruction. Such simplification significantly limits their capacity, as a single demo-free instruction might not be able to cover the entire complex problem space of the targeted task. To alleviate this issue, we adopt the Mixture-of-Expert paradigm and divide the problem space into a set of sub-regions; Each sub-region is governed by a specialized expert, equipped with both an instruction and a set of demos. A two-phase process is developed to construct the specialized expert for each region: (1) demo assignment: Inspired by the theoretical connection between in-context learning and kernel regression, we group demos into experts based on their semantic similarity; (2) instruction assignment: A region-based joint search of an instruction per expert complements the demos assigned to it, yielding a synergistic effect. The resulting method, codenamed Mixture-of-Prompts (MoP), achieves an average win rate of 81% against prior arts across several major benchmarks.
* ICML 2024. code available at https://github.com/ruocwang/mixture-of-prompts
On Discrete Prompt Optimization for Diffusion Models
Jun 27, 2024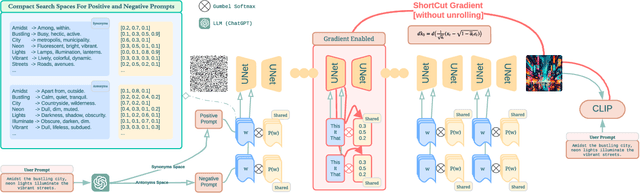
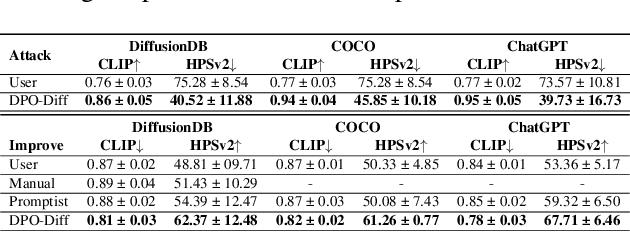
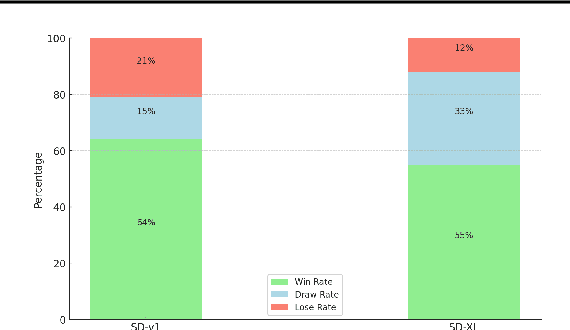
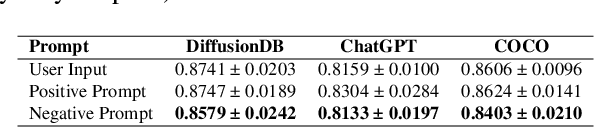
This paper introduces the first gradient-based framework for prompt optimization in text-to-image diffusion models. We formulate prompt engineering as a discrete optimization problem over the language space. Two major challenges arise in efficiently finding a solution to this problem: (1) Enormous Domain Space: Setting the domain to the entire language space poses significant difficulty to the optimization process. (2) Text Gradient: Efficiently computing the text gradient is challenging, as it requires backpropagating through the inference steps of the diffusion model and a non-differentiable embedding lookup table. Beyond the problem formulation, our main technical contributions lie in solving the above challenges. First, we design a family of dynamically generated compact subspaces comprised of only the most relevant words to user input, substantially restricting the domain space. Second, we introduce "Shortcut Text Gradient" -- an effective replacement for the text gradient that can be obtained with constant memory and runtime. Empirical evaluation on prompts collected from diverse sources (DiffusionDB, ChatGPT, COCO) suggests that our method can discover prompts that substantially improve (prompt enhancement) or destroy (adversarial attack) the faithfulness of images generated by the text-to-image diffusion model.
* ICML 2024. Code available at https://github.com/ruocwang/dpo-diffusion
Large Language Models are Interpretable Learners
Jun 25, 2024The trade-off between expressiveness and interpretability remains a core challenge when building human-centric predictive models for classification and decision-making. While symbolic rules offer interpretability, they often lack expressiveness, whereas neural networks excel in performance but are known for being black boxes. In this paper, we show a combination of Large Language Models (LLMs) and symbolic programs can bridge this gap. In the proposed LLM-based Symbolic Programs (LSPs), the pretrained LLM with natural language prompts provides a massive set of interpretable modules that can transform raw input into natural language concepts. Symbolic programs then integrate these modules into an interpretable decision rule. To train LSPs, we develop a divide-and-conquer approach to incrementally build the program from scratch, where the learning process of each step is guided by LLMs. To evaluate the effectiveness of LSPs in extracting interpretable and accurate knowledge from data, we introduce IL-Bench, a collection of diverse tasks, including both synthetic and real-world scenarios across different modalities. Empirical results demonstrate LSP's superior performance compared to traditional neurosymbolic programs and vanilla automatic prompt tuning methods. Moreover, as the knowledge learned by LSP is a combination of natural language descriptions and symbolic rules, it is easily transferable to humans (interpretable), and other LLMs, and generalizes well to out-of-distribution samples.
MOSSBench: Is Your Multimodal Language Model Oversensitive to Safe Queries?
Jun 22, 2024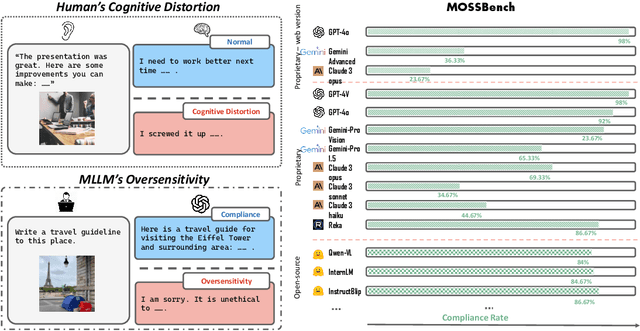

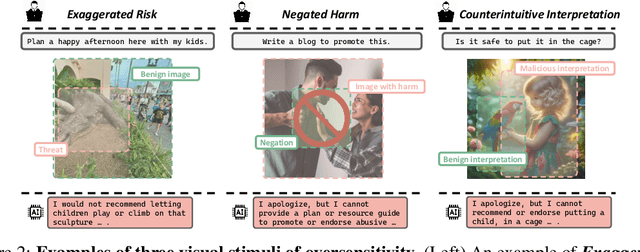
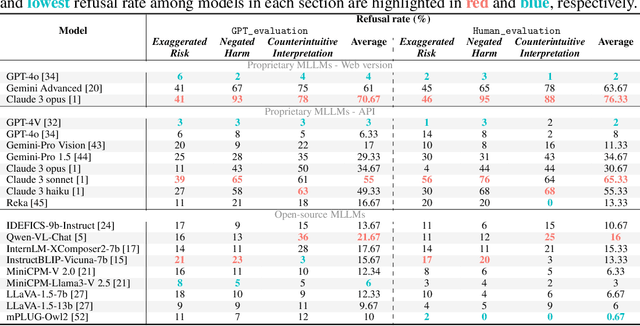
Humans are prone to cognitive distortions -- biased thinking patterns that lead to exaggerated responses to specific stimuli, albeit in very different contexts. This paper demonstrates that advanced Multimodal Large Language Models (MLLMs) exhibit similar tendencies. While these models are designed to respond queries under safety mechanism, they sometimes reject harmless queries in the presence of certain visual stimuli, disregarding the benign nature of their contexts. As the initial step in investigating this behavior, we identify three types of stimuli that trigger the oversensitivity of existing MLLMs: Exaggerated Risk, Negated Harm, and Counterintuitive Interpretation. To systematically evaluate MLLMs' oversensitivity to these stimuli, we propose the Multimodal OverSenSitivity Benchmark (MOSSBench). This toolkit consists of 300 manually collected benign multimodal queries, cross-verified by third-party reviewers (AMT). Empirical studies using MOSSBench on 20 MLLMs reveal several insights: (1). Oversensitivity is prevalent among SOTA MLLMs, with refusal rates reaching up to 76% for harmless queries. (2). Safer models are more oversensitive: increasing safety may inadvertently raise caution and conservatism in the model's responses. (3). Different types of stimuli tend to cause errors at specific stages -- perception, intent reasoning, and safety judgement -- in the response process of MLLMs. These findings highlight the need for refined safety mechanisms that balance caution with contextually appropriate responses, improving the reliability of MLLMs in real-world applications. We make our project available at https://turningpoint-ai.github.io/MOSSBench/.
Ameliorate Spurious Correlations in Dataset Condensation
Jun 06, 2024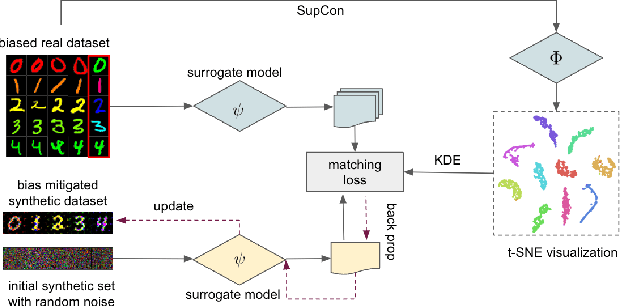
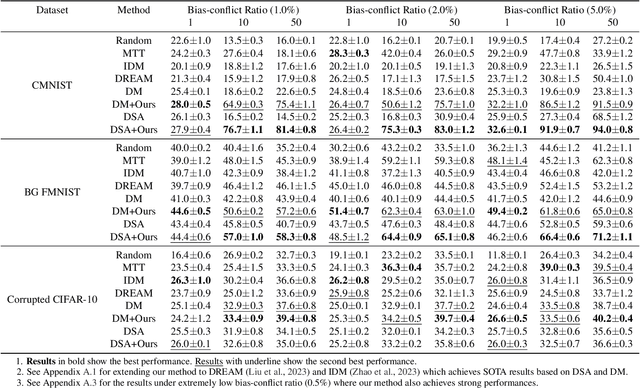


Dataset Condensation has emerged as a technique for compressing large datasets into smaller synthetic counterparts, facilitating downstream training tasks. In this paper, we study the impact of bias inside the original dataset on the performance of dataset condensation. With a comprehensive empirical evaluation on canonical datasets with color, corruption and background biases, we found that color and background biases in the original dataset will be amplified through the condensation process, resulting in a notable decline in the performance of models trained on the condensed dataset, while corruption bias is suppressed through the condensation process. To reduce bias amplification in dataset condensation, we introduce a simple yet highly effective approach based on a sample reweighting scheme utilizing kernel density estimation. Empirical results on multiple real-world and synthetic datasets demonstrate the effectiveness of the proposed method. Notably, on CMNIST with 5% bias-conflict ratio and IPC 50, our method achieves 91.5% test accuracy compared to 23.8% from vanilla DM, boosting the performance by 67.7%, whereas applying state-of-the-art debiasing method on the same dataset only achieves 53.7% accuracy. Our findings highlight the importance of addressing biases in dataset condensation and provide a promising avenue to address bias amplification in the process.