 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Token-Level Hallucination Detection in Large Language Models
May 12, 2026Large language models (LLMs) have demonstrated remarkable capabilities, but they still frequently produce hallucinations. These hallucinations are difficult to detect in reasoning-intensive tasks, where the content appears coherent but contains errors like logical flaws and unreliable intermediate results. While step-level analysis is commonly used to detect internal hallucinations, it suffers from limited granularity and poor scalability due to its reliance on step segmentation. To address these limitations, we propose TokenHD, a holistic pipeline for training token-level hallucination detectors. Specifically, TokenHD consists of a scalable data engine for synthesizing large-scale hallucination annotations along with a training recipe featuring an importance-weighted strategy for robust model training. To systematically assess the detection performance, we also provide a rigorous evaluation protocol. Through training within TokenHD, our detector operates directly on free-form text to identify hallucinations, eliminating the need for predefined step segmentation or additional text reformatting. Our experiments show that even a small detector (0.6B) achieves substantial performance gains after training, surpassing much larger reasoning models (e.g., QwQ-32B), and detection performance scales consistently with model size from 0.6B to 8B. Finally, we show that our detector can generalize well across diverse practical scenarios and explore strategies to further enhance its cross-domain generalization capability.
Route Before Retrieve: Activating Latent Routing Abilities of LLMs for RAG vs. Long-Context Selection
May 11, 2026Recent advances in large language models (LLMs) have expanded the context window to beyond 128K tokens, enabling long-document understanding and multi-source reasoning. A key challenge, however, lies in choosing between retrieval-augmented generation (RAG) and long-context (LC) strategies: RAG is efficient but constrained by retrieval quality, while LC supports global reasoning at higher cost and with position sensitivity. Existing methods such as Self-Route adopt failure-driven fallback from RAG to LC, but remain passive, inefficient, and hard to interpret. We propose Pre-Route, a proactive routing framework that performs structured reasoning before answering. Using lightweight metadata (e.g., document type, length, initial snippet), Pre-Route enables task analysis, coverage estimation, and information-need prediction, producing explainable and cost-efficient routing decisions. Our study shows three key findings: (i) LLMs possess latent routing ability that can be reliably elicited with guidelines, allowing single-sample performance to approach that of multi-sample (Best-of-N) results; (ii) linear probes reveal that structured prompts sharpen the separability of the "optimal routing dimension" in representation space; and (iii) distillation transfers this reasoning structure to smaller models for lightweight deployment. Experiments on LaRA (in-domain) and LongBench-v2 (OOD) confirm that Pre-Route outperforms Always-RAG, Always-LC, and Self-Route baselines, achieving superior overall cost-effectiveness.
CARV: A Diagnostic Benchmark for Compositional Analogical Reasoning in Multimodal LLMs
Mar 30, 2026Analogical reasoning tests a fundamental aspect of human cognition: mapping the relation from one pair of objects to another. Existing evaluations of this ability in multimodal large language models (MLLMs) overlook the ability to compose rules from multiple sources, a critical component of higher-order intelligence. To close this gap, we introduce CARV (Compositional Analogical Reasoning in Vision), a novel task together with a 5,500-sample dataset as the first diagnostic benchmark. We extend the analogy from a single pair to multiple pairs, which requires MLLMs to extract symbolic rules from each pair and compose new transformations. Evaluation on the state-of-the-art MLLMs reveals a striking performance gap: even Gemini-2.5 Pro achieving only 40.4% accuracy, far below human-level performance of 100%. Diagnostic analysis shows two consistent failure modes: (1) decomposing visual changes into symbolic rules, and (2) maintaining robustness under diverse or complex settings, highlighting the limitations of current MLLMs on this task.
Deconstructing Multimodal Mathematical Reasoning: Towards a Unified Perception-Alignment-Reasoning Paradigm
Mar 09, 2026Multimodal Mathematical Reasoning (MMR) has recently attracted increasing attention for its capability to solve mathematical problems that involve both textual and visual modalities. However, current models still face significant challenges in real-world visual math tasks. They often misinterpret diagrams, fail to align mathematical symbols with visual evidence, and produce inconsistent reasoning steps. Moreover, existing evaluations mainly focus on checking final answers rather than verifying the correctness or executability of each intermediate step. To address these limitations, a growing body of recent research addresses these issues by integrating structured perception, explicit alignment, and verifiable reasoning within unified frameworks. To establish a clear roadmap for understanding and comparing different MMR approaches, we systematically study them around four fundamental questions: (1) What to extract from multimodal inputs, (2) How to represent and align textual and visual information, (3) How to perform the reasoning, and (4) How to evaluate the correctness of the overall reasoning process. Finally, we discuss open challenges and offer perspectives on promising directions for future research.
Empowering Reliable Visual-Centric Instruction Following in MLLMs
Jan 06, 2026Evaluating the instruction-following (IF) capabilities of Multimodal Large Language Models (MLLMs) is essential for rigorously assessing how faithfully model outputs adhere to user-specified intentions. Nevertheless, existing benchmarks for evaluating MLLMs' instruction-following capability primarily focus on verbal instructions in the textual modality. These limitations hinder a thorough analysis of instruction-following capabilities, as they overlook the implicit constraints embedded in the semantically rich visual modality. To address this gap, we introduce VC-IFEval, a new benchmark accompanied by a systematically constructed dataset that evaluates MLLMs' instruction-following ability under multimodal settings. Our benchmark systematically incorporates vision-dependent constraints into instruction design, enabling a more rigorous and fine-grained assessment of how well MLLMs align their outputs with both visual input and textual instructions. Furthermore, by fine-tuning MLLMs on our dataset, we achieve substantial gains in visual instruction-following accuracy and adherence. Through extensive evaluation across representative MLLMs, we provide new insights into the strengths and limitations of current models.
PISanitizer: Preventing Prompt Injection to Long-Context LLMs via Prompt Sanitization
Nov 13, 2025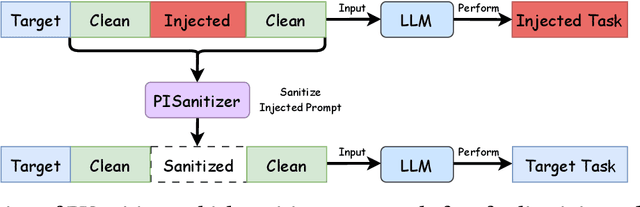
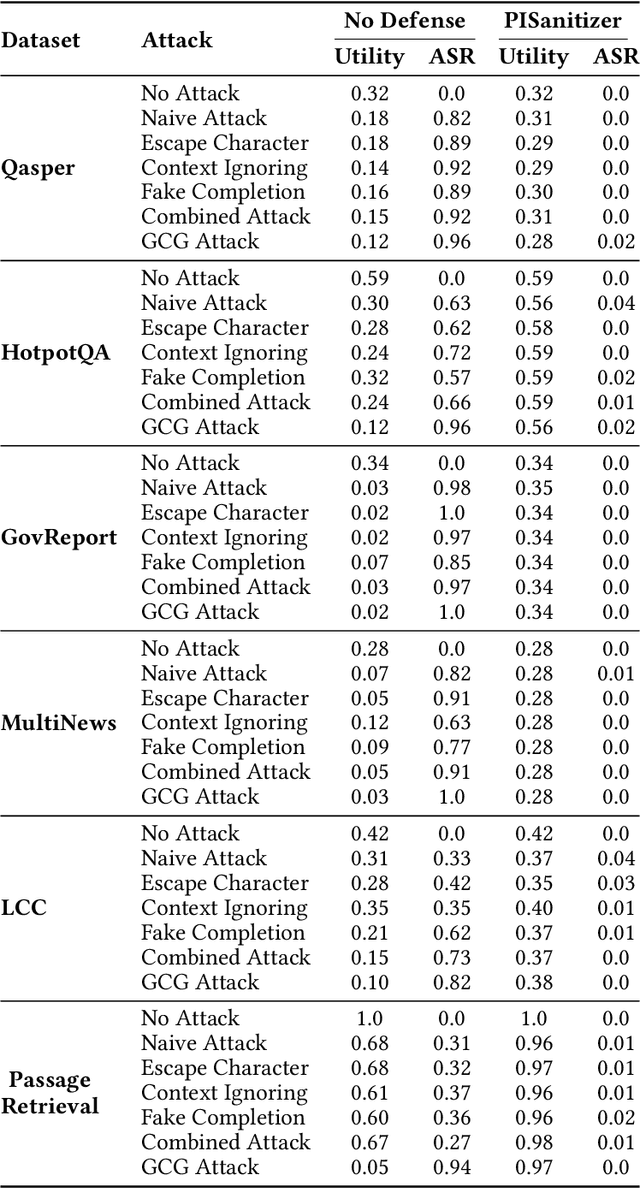
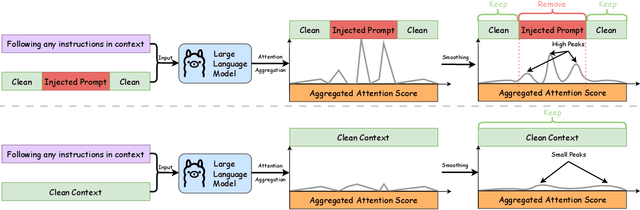

Long context LLMs are vulnerable to prompt injection, where an attacker can inject an instruction in a long context to induce an LLM to generate an attacker-desired output. Existing prompt injection defenses are designed for short contexts. When extended to long-context scenarios, they have limited effectiveness. The reason is that an injected instruction constitutes only a very small portion of a long context, making the defense very challenging. In this work, we propose PISanitizer, which first pinpoints and sanitizes potential injected tokens (if any) in a context before letting a backend LLM generate a response, thereby eliminating the influence of the injected instruction. To sanitize injected tokens, PISanitizer builds on two observations: (1) prompt injection attacks essentially craft an instruction that compels an LLM to follow it, and (2) LLMs intrinsically leverage the attention mechanism to focus on crucial input tokens for output generation. Guided by these two observations, we first intentionally let an LLM follow arbitrary instructions in a context and then sanitize tokens receiving high attention that drive the instruction-following behavior of the LLM. By design, PISanitizer presents a dilemma for an attacker: the more effectively an injected instruction compels an LLM to follow it, the more likely it is to be sanitized by PISanitizer. Our extensive evaluation shows that PISanitizer can successfully prevent prompt injection, maintain utility, outperform existing defenses, is efficient, and is robust to optimization-based and strong adaptive attacks. The code is available at https://github.com/sleeepeer/PISanitizer.
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
Sep 16, 2025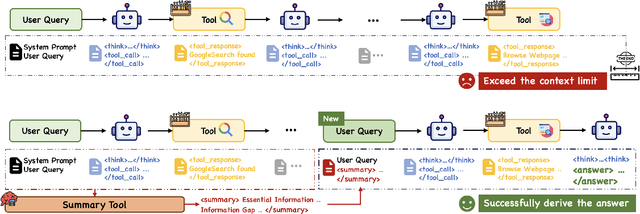
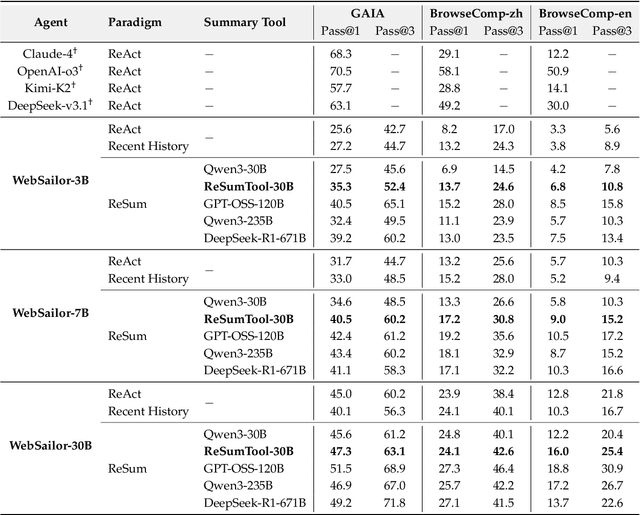
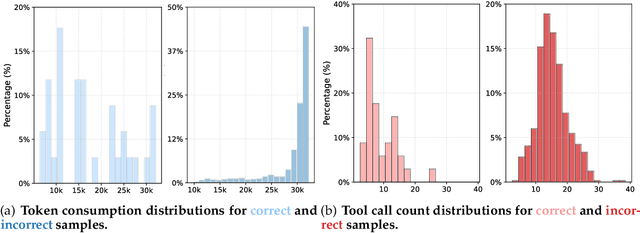
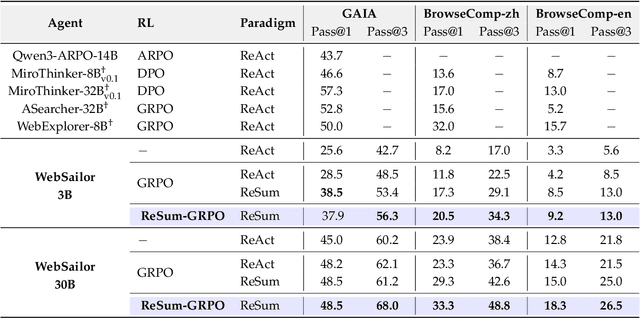
Large Language Model (LLM)-based web agents demonstrate strong performance on knowledge-intensive tasks but are hindered by context window limitations in paradigms like ReAct. Complex queries involving multiple entities, intertwined relationships, and high uncertainty demand extensive search cycles that rapidly exhaust context budgets before reaching complete solutions. To overcome this challenge, we introduce ReSum, a novel paradigm that enables indefinite exploration through periodic context summarization. ReSum converts growing interaction histories into compact reasoning states, maintaining awareness of prior discoveries while bypassing context constraints. For paradigm adaptation, we propose ReSum-GRPO, integrating GRPO with segmented trajectory training and advantage broadcasting to familiarize agents with summary-conditioned reasoning. Extensive experiments on web agents of varying scales across three benchmarks demonstrate that ReSum delivers an average absolute improvement of 4.5\% over ReAct, with further gains of up to 8.2\% following ReSum-GRPO training. Notably, with only 1K training samples, our WebResummer-30B (a ReSum-GRPO-trained version of WebSailor-30B) achieves 33.3\% Pass@1 on BrowseComp-zh and 18.3\% on BrowseComp-en, surpassing existing open-source web agents.
Exploring Expert Failures Improves LLM Agent Tuning
Apr 18, 2025Large Language Models (LLMs) have shown tremendous potential as agents, excelling at tasks that require multiple rounds of reasoning and interactions. Rejection Sampling Fine-Tuning (RFT) has emerged as an effective method for finetuning LLMs as agents: it first imitates expert-generated successful trajectories and further improves agentic skills through iterative fine-tuning on successful, self-generated trajectories. However, since the expert (e.g., GPT-4) succeeds primarily on simpler subtasks and RFT inherently favors simpler scenarios, many complex subtasks remain unsolved and persistently out-of-distribution (OOD). Upon investigating these challenging subtasks, we discovered that previously failed expert trajectories can often provide valuable guidance, e.g., plans and key actions, that can significantly improve agent exploration efficiency and acquisition of critical skills. Motivated by these observations, we propose Exploring Expert Failures (EEF), which identifies beneficial actions from failed expert trajectories and integrates them into the training dataset. Potentially harmful actions are meticulously excluded to prevent contamination of the model learning process. By leveraging the beneficial actions in expert failures, EEF successfully solves some previously unsolvable subtasks and improves agent tuning performance. Remarkably, our approach achieved a 62\% win rate in WebShop, outperforming RFT (53. 6\%) and GPT-4 (35. 6\%), and to the best of our knowledge, setting a new state-of-the-art as the first method to surpass a score of 0.81 in WebShop and exceed 81 in SciWorld.
Scaling Laws of Synthetic Data for Language Models
Mar 26, 2025



Large language models (LLMs) achieve strong performance across diverse tasks, largely driven by high-quality web data used in pre-training. However, recent studies indicate this data source is rapidly depleting. Synthetic data emerges as a promising alternative, but it remains unclear whether synthetic datasets exhibit predictable scalability comparable to raw pre-training data. In this work, we systematically investigate the scaling laws of synthetic data by introducing SynthLLM, a scalable framework that transforms pre-training corpora into diverse, high-quality synthetic datasets. Our approach achieves this by automatically extracting and recombining high-level concepts across multiple documents using a graph algorithm. Key findings from our extensive mathematical experiments on SynthLLM include: (1) SynthLLM generates synthetic data that reliably adheres to the rectified scaling law across various model sizes; (2) Performance improvements plateau near 300B tokens; and (3) Larger models approach optimal performance with fewer training tokens. For instance, an 8B model peaks at 1T tokens, while a 3B model requires 4T. Moreover, comparisons with existing synthetic data generation and augmentation methods demonstrate that SynthLLM achieves superior performance and scalability. Our findings highlight synthetic data as a scalable and reliable alternative to organic pre-training corpora, offering a viable path toward continued improvement in model performance.
R1-Zero's "Aha Moment" in Visual Reasoning on a 2B Non-SFT Model
Mar 07, 2025Recently DeepSeek R1 demonstrated how reinforcement learning with simple rule-based incentives can enable autonomous development of complex reasoning in large language models, characterized by the "aha moment", in which the model manifest self-reflection and increased response length during training. However, attempts to extend this success to multimodal reasoning often failed to reproduce these key characteristics. In this report, we present the first successful replication of these emergent characteristics for multimodal reasoning on only a non-SFT 2B model. Starting with Qwen2-VL-2B and applying reinforcement learning directly on the SAT dataset, our model achieves 59.47% accuracy on CVBench, outperforming the base model by approximately ~30% and exceeding both SFT setting by ~2%. In addition, we share our failed attempts and insights in attempting to achieve R1-like reasoning using RL with instruct models. aiming to shed light on the challenges involved. Our key observations include: (1) applying RL on instruct model often results in trivial reasoning trajectories, and (2) naive length reward are ineffective in eliciting reasoning capabilities. The project code is available at https://github.com/turningpoint-ai/VisualThinker-R1-Zero