 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAOI: Turning Failed Trajectories into Training Signals for Autonomous Cloud Diagnosis
Mar 05, 2026Large language model (LLM) agents offer a promising data-driven approach to automating Site Reliability Engineering (SRE), yet their enterprise deployment is constrained by three challenges: restricted access to proprietary data, unsafe action execution under permission-governed environments, and the inability of closed systems to improve from failures. We present AOI (Autonomous Operations Intelligence), a trainable multi-agent framework formulating automated operations as a structured trajectory learning problem under security constraints. Our approach integrates three key components. First, a trainable diagnostic system applies Group Relative Policy Optimization (GRPO) to distill expert-level knowledge into locally deployed open-source models, enabling preference-based learning without exposing sensitive data. Second, a read-write separated execution architecture decomposes operational trajectories into observation, reasoning, and action phases, allowing safe learning while preventing unauthorized state mutation. Third, a Failure Trajectory Closed-Loop Evolver mines unsuccessful trajectories and converts them into corrective supervision signals, enabling continual data augmentation. Evaluated on the AIOpsLab benchmark, our contributions yield cumulative gains. (1) The AOI runtime alone achieves 66.3% best@5 success on all 86 tasks, outperforming the prior state-of-the-art (41.9%) by 24.4 points. (2) Adding Observer GRPO training, a locally deployed 14B model reaches 42.9% avg@1 on 63 held-out tasks with unseen fault types, surpassing Claude Sonnet 4.5. (3) The Evolver converts 37 failed trajectories into diagnostic guidance, improving end-to-end avg@5 by 4.8 points while reducing variance by 35%.
From Abstract to Contextual: What LLMs Still Cannot Do in Mathematics
Jan 30, 2026Large language models now solve many benchmark math problems at near-expert levels, yet this progress has not fully translated into reliable performance in real-world applications. We study this gap through contextual mathematical reasoning, where the mathematical core must be formulated from descriptive scenarios. We introduce ContextMATH, a benchmark that repurposes AIME and MATH-500 problems into two contextual settings: Scenario Grounding (SG), which embeds abstract problems into realistic narratives without increasing reasoning complexity, and Complexity Scaling (CS), which transforms explicit conditions into sub-problems to capture how constraints often appear in practice. Evaluating 61 proprietary and open-source models, we observe sharp drops: on average, open-source models decline by 13 and 34 points on SG and CS, while proprietary models drop by 13 and 20. Error analysis shows that errors are dominated by incorrect problem formulation, with formulation accuracy declining as original problem difficulty increases. Correct formulation emerges as a prerequisite for success, and its sufficiency improves with model scale, indicating that larger models advance in both understanding and reasoning. Nevertheless, formulation and reasoning remain two complementary bottlenecks that limit contextual mathematical problem solving. Finally, we find that fine-tuning with scenario data improves performance, whereas formulation-only training is ineffective. However, performance gaps are only partially alleviated, highlighting contextual mathematical reasoning as a central unsolved challenge for LLMs.
Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
From Word to World: Can Large Language Models be Implicit Text-based World Models?
Dec 21, 2025Agentic reinforcement learning increasingly relies on experience-driven scaling, yet real-world environments remain non-adaptive, limited in coverage, and difficult to scale. World models offer a potential way to improve learning efficiency through simulated experience, but it remains unclear whether large language models can reliably serve this role and under what conditions they meaningfully benefit agents. We study these questions in text-based environments, which provide a controlled setting to reinterpret language modeling as next-state prediction under interaction. We introduce a three-level framework for evaluating LLM-based world models: (i) fidelity and consistency, (ii) scalability and robustness, and (iii) agent utility. Across five representative environments, we find that sufficiently trained world models maintain coherent latent state, scale predictably with data and model size, and improve agent performance via action verification, synthetic trajectory generation, and warm-starting reinforcement learning. Meanwhile, these gains depend critically on behavioral coverage and environment complexity, delineating clear boundry on when world modeling effectively supports agent learning.
VisCodex: Unified Multimodal Code Generation via Merging Vision and Coding Models
Aug 13, 2025Multimodal large language models (MLLMs) have significantly advanced the integration of visual and textual understanding. However, their ability to generate code from multimodal inputs remains limited. In this work, we introduce VisCodex, a unified framework that seamlessly merges vision and coding language models to empower MLLMs with strong multimodal code generation abilities. Leveraging a task vector-based model merging technique, we integrate a state-of-the-art coding LLM into a strong vision-language backbone, while preserving both visual comprehension and advanced coding skills. To support training and evaluation, we introduce the Multimodal Coding Dataset (MCD), a large-scale and diverse collection of 598k samples, including high-quality HTML code, chart image-code pairs, image-augmented StackOverflow QA, and algorithmic problems. Furthermore, we propose InfiBench-V, a novel and challenging benchmark specifically designed to assess models on visually-rich, real-world programming questions that demand a nuanced understanding of both textual and visual contexts. Extensive experiments show that VisCodex achieves state-of-the-art performance among open-source MLLMs and approaches proprietary models like GPT-4o, highlighting the effectiveness of our model merging strategy and new datasets.
Scaling Laws of Synthetic Data for Language Models
Mar 26, 2025



Large language models (LLMs) achieve strong performance across diverse tasks, largely driven by high-quality web data used in pre-training. However, recent studies indicate this data source is rapidly depleting. Synthetic data emerges as a promising alternative, but it remains unclear whether synthetic datasets exhibit predictable scalability comparable to raw pre-training data. In this work, we systematically investigate the scaling laws of synthetic data by introducing SynthLLM, a scalable framework that transforms pre-training corpora into diverse, high-quality synthetic datasets. Our approach achieves this by automatically extracting and recombining high-level concepts across multiple documents using a graph algorithm. Key findings from our extensive mathematical experiments on SynthLLM include: (1) SynthLLM generates synthetic data that reliably adheres to the rectified scaling law across various model sizes; (2) Performance improvements plateau near 300B tokens; and (3) Larger models approach optimal performance with fewer training tokens. For instance, an 8B model peaks at 1T tokens, while a 3B model requires 4T. Moreover, comparisons with existing synthetic data generation and augmentation methods demonstrate that SynthLLM achieves superior performance and scalability. Our findings highlight synthetic data as a scalable and reliable alternative to organic pre-training corpora, offering a viable path toward continued improvement in model performance.
Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective
Jan 19, 2025Large Language Models (LLMs) have made notable progress in mathematical reasoning, yet they often rely on single-paradigm reasoning that limits their effectiveness across diverse tasks. In this paper, we introduce Chain-of-Reasoning (CoR), a novel unified framework that integrates multiple reasoning paradigms--Natural Language Reasoning (NLR), Algorithmic Reasoning (AR), and Symbolic Reasoning (SR)--to enable synergistic collaboration. CoR generates multiple potential answers using different reasoning paradigms and synthesizes them into a coherent final solution. We propose a Progressive Paradigm Training (PPT) strategy that allows models to progressively master these paradigms, culminating in the development of CoR-Math-7B. Experimental results demonstrate that CoR-Math-7B significantly outperforms current SOTA models, achieving up to a 41.0% absolute improvement over GPT-4 in theorem proving tasks and a 7.9% improvement over RL-based methods in arithmetic tasks. These results showcase the enhanced mathematical comprehensive ability of our model, achieving significant performance gains on specific tasks and enabling zero-shot generalization across tasks.
ShifCon: Enhancing Non-Dominant Language Capabilities with a Shift-based Contrastive Framework
Oct 25, 2024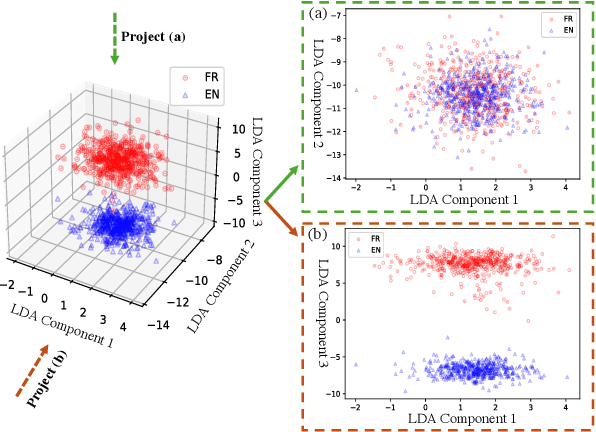
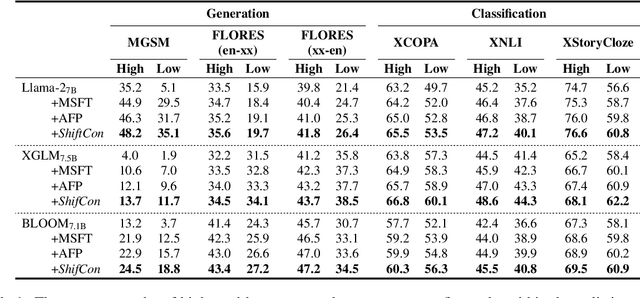
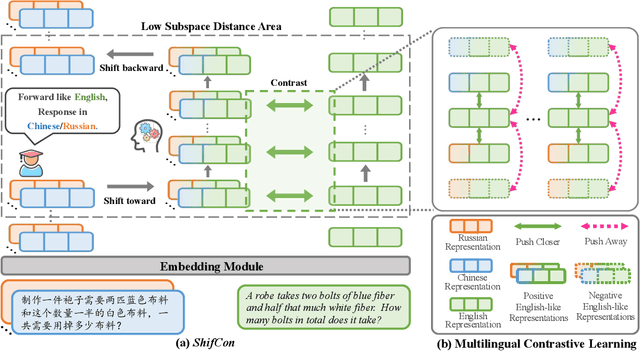
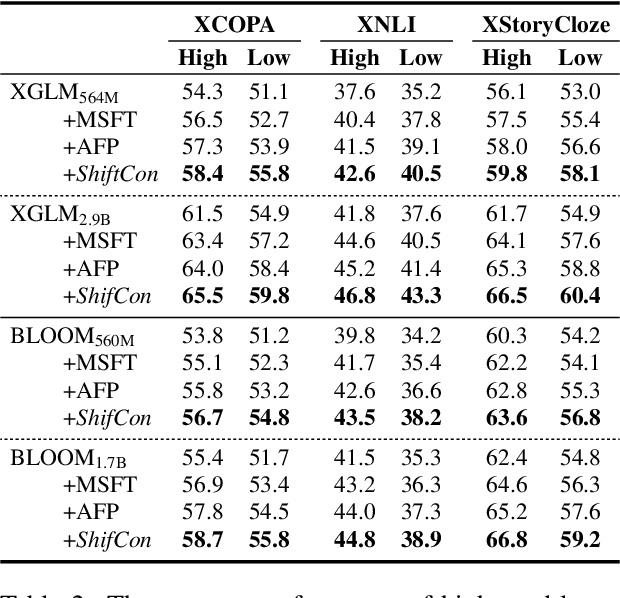
Although fine-tuning Large Language Models (LLMs) with multilingual data can rapidly enhance the multilingual capabilities of LLMs, they still exhibit a performance gap between the dominant language (e.g., English) and non-dominant ones due to the imbalance of training data across languages. To further enhance the performance of non-dominant languages, we propose ShifCon, a Shift-based Contrastive framework that aligns the internal forward process of other languages toward that of the dominant one. Specifically, it shifts the representations of non-dominant languages into the dominant language subspace, allowing them to access relatively rich information encoded in the model parameters. The enriched representations are then shifted back into their original language subspace before generation. Moreover, we introduce a subspace distance metric to pinpoint the optimal layer area for shifting representations and employ multilingual contrastive learning to further enhance the alignment of representations within this area. Experiments demonstrate that our ShifCon framework significantly enhances the performance of non-dominant languages, particularly for low-resource ones. Further analysis offers extra insights to verify the effectiveness of ShifCon and propel future research
Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Feb 26, 2024



Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on two representative LLMs, namely LLaMA-2 and BLOOM. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to "steer" the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.
Synthetic Data (Almost) from Scratch: Generalized Instruction Tuning for Language Models
Feb 20, 2024We introduce Generalized Instruction Tuning (called GLAN), a general and scalable method for instruction tuning of Large Language Models (LLMs). Unlike prior work that relies on seed examples or existing datasets to construct instruction tuning data, GLAN exclusively utilizes a pre-curated taxonomy of human knowledge and capabilities as input and generates large-scale synthetic instruction data across all disciplines. Specifically, inspired by the systematic structure in human education system, we build the taxonomy by decomposing human knowledge and capabilities to various fields, sub-fields and ultimately, distinct disciplines semi-automatically, facilitated by LLMs. Subsequently, we generate a comprehensive list of subjects for every discipline and proceed to design a syllabus tailored to each subject, again utilizing LLMs. With the fine-grained key concepts detailed in every class session of the syllabus, we are able to generate diverse instructions with a broad coverage across the entire spectrum of human knowledge and skills. Extensive experiments on large language models (e.g., Mistral) demonstrate that GLAN excels in multiple dimensions from mathematical reasoning, coding, academic exams, logical reasoning to general instruction following without using task-specific training data of these tasks. In addition, GLAN allows for easy customization and new fields or skills can be added by simply incorporating a new node into our taxonomy.