 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models
Jan 20, 2026Mechanistic Interpretability (MI) has emerged as a vital approach to demystify the opaque decision-making of Large Language Models (LLMs). However, existing reviews primarily treat MI as an observational science, summarizing analytical insights while lacking a systematic framework for actionable intervention. To bridge this gap, we present a practical survey structured around the pipeline: "Locate, Steer, and Improve." We formally categorize Localizing (diagnosis) and Steering (intervention) methods based on specific Interpretable Objects to establish a rigorous intervention protocol. Furthermore, we demonstrate how this framework enables tangible improvements in Alignment, Capability, and Efficiency, effectively operationalizing MI as an actionable methodology for model optimization. The curated paper list of this work is available at https://github.com/rattlesnakey/Awesome-Actionable-MI-Survey.
HermesFlow: Seamlessly Closing the Gap in Multimodal Understanding and Generation
Feb 17, 2025The remarkable success of the autoregressive paradigm has made significant advancement in Multimodal Large Language Models (MLLMs), with powerful models like Show-o, Transfusion and Emu3 achieving notable progress in unified image understanding and generation. For the first time, we uncover a common phenomenon: the understanding capabilities of MLLMs are typically stronger than their generative capabilities, with a significant gap between the two. Building on this insight, we propose HermesFlow, a simple yet general framework designed to seamlessly bridge the gap between understanding and generation in MLLMs. Specifically, we take the homologous data as input to curate homologous preference data of both understanding and generation. Through Pair-DPO and self-play iterative optimization, HermesFlow effectively aligns multimodal understanding and generation using homologous preference data. Extensive experiments demonstrate the significant superiority of our approach over prior methods, particularly in narrowing the gap between multimodal understanding and generation. These findings highlight the potential of HermesFlow as a general alignment framework for next-generation multimodal foundation models. Code: https://github.com/Gen-Verse/HermesFlow
AnyCharV: Bootstrap Controllable Character Video Generation with Fine-to-Coarse Guidance
Feb 12, 2025Character video generation is a significant real-world application focused on producing high-quality videos featuring specific characters. Recent advancements have introduced various control signals to animate static characters, successfully enhancing control over the generation process. However, these methods often lack flexibility, limiting their applicability and making it challenging for users to synthesize a source character into a desired target scene. To address this issue, we propose a novel framework, AnyCharV, that flexibly generates character videos using arbitrary source characters and target scenes, guided by pose information. Our approach involves a two-stage training process. In the first stage, we develop a base model capable of integrating the source character with the target scene using pose guidance. The second stage further bootstraps controllable generation through a self-boosting mechanism, where we use the generated video in the first stage and replace the fine mask with the coarse one, enabling training outcomes with better preservation of character details. Experimental results demonstrate the effectiveness and robustness of our proposed method. Our project page is https://anycharv.github.io.
ShifCon: Enhancing Non-Dominant Language Capabilities with a Shift-based Contrastive Framework
Oct 25, 2024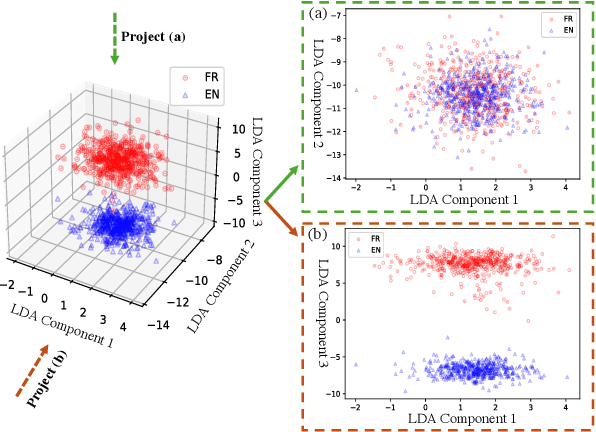
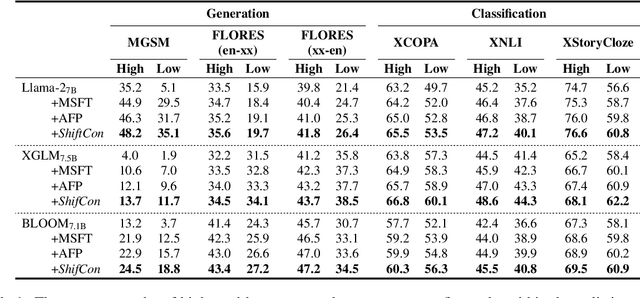
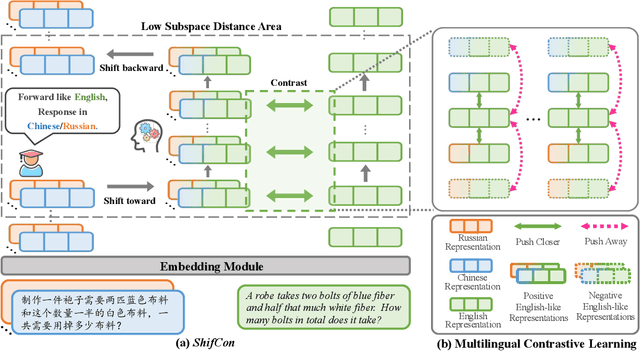
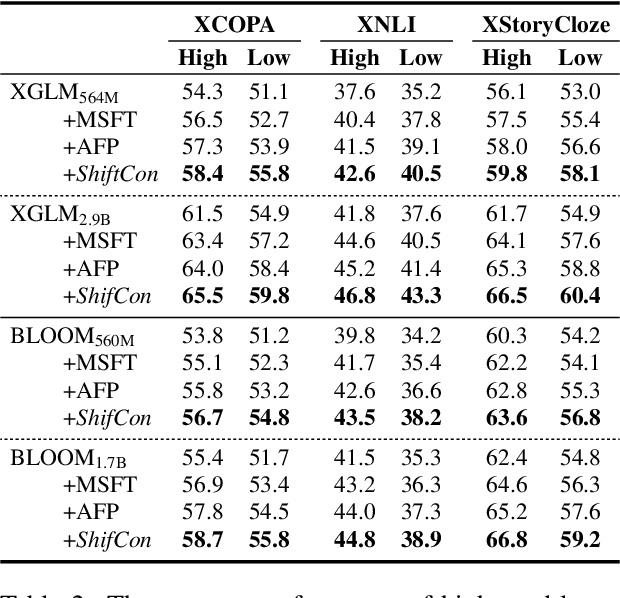
Although fine-tuning Large Language Models (LLMs) with multilingual data can rapidly enhance the multilingual capabilities of LLMs, they still exhibit a performance gap between the dominant language (e.g., English) and non-dominant ones due to the imbalance of training data across languages. To further enhance the performance of non-dominant languages, we propose ShifCon, a Shift-based Contrastive framework that aligns the internal forward process of other languages toward that of the dominant one. Specifically, it shifts the representations of non-dominant languages into the dominant language subspace, allowing them to access relatively rich information encoded in the model parameters. The enriched representations are then shifted back into their original language subspace before generation. Moreover, we introduce a subspace distance metric to pinpoint the optimal layer area for shifting representations and employ multilingual contrastive learning to further enhance the alignment of representations within this area. Experiments demonstrate that our ShifCon framework significantly enhances the performance of non-dominant languages, particularly for low-resource ones. Further analysis offers extra insights to verify the effectiveness of ShifCon and propel future research
Understanding Multimodal Deep Neural Networks: A Concept Selection View
Apr 13, 2024



The multimodal deep neural networks, represented by CLIP, have generated rich downstream applications owing to their excellent performance, thus making understanding the decision-making process of CLIP an essential research topic. Due to the complex structure and the massive pre-training data, it is often regarded as a black-box model that is too difficult to understand and interpret. Concept-based models map the black-box visual representations extracted by deep neural networks onto a set of human-understandable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. However, these methods involve the datasets labeled with fine-grained attributes by expert knowledge, which incur high costs and introduce excessive human prior knowledge and bias. In this paper, we observe the long-tail distribution of concepts, based on which we propose a two-stage Concept Selection Model (CSM) to mine core concepts without introducing any human priors. The concept greedy rough selection algorithm is applied to extract head concepts, and then the concept mask fine selection method performs the extraction of core concepts. Experiments show that our approach achieves comparable performance to end-to-end black-box models, and human evaluation demonstrates that the concepts discovered by our method are interpretable and comprehensible for humans.
Incremental Residual Concept Bottleneck Models
Apr 13, 2024



Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
A Question-centric Multi-experts Contrastive Learning Framework for Improving the Accuracy and Interpretability of Deep Sequential Knowledge Tracing Models
Mar 12, 2024Knowledge tracing (KT) plays a crucial role in predicting students' future performance by analyzing their historical learning processes. Deep neural networks (DNNs) have shown great potential in solving the KT problem. However, there still exist some important challenges when applying deep learning techniques to model the KT process. The first challenge lies in taking the individual information of the question into modeling. This is crucial because, despite questions sharing the same knowledge component (KC), students' knowledge acquisition on homogeneous questions can vary significantly. The second challenge lies in interpreting the prediction results from existing deep learning-based KT models. In real-world applications, while it may not be necessary to have complete transparency and interpretability of the model parameters, it is crucial to present the model's prediction results in a manner that teachers find interpretable. This makes teachers accept the rationale behind the prediction results and utilize them to design teaching activities and tailored learning strategies for students. However, the inherent black-box nature of deep learning techniques often poses a hurdle for teachers to fully embrace the model's prediction results. To address these challenges, we propose a Question-centric Multi-experts Contrastive Learning framework for KT called Q-MCKT.
Improving Low-Resource Knowledge Tracing Tasks by Supervised Pre-training and Importance Mechanism Fine-tuning
Mar 11, 2024



Knowledge tracing (KT) aims to estimate student's knowledge mastery based on their historical interactions. Recently, the deep learning based KT (DLKT) approaches have achieved impressive performance in the KT task. These DLKT models heavily rely on the large number of available student interactions. However, due to various reasons such as budget constraints and privacy concerns, observed interactions are very limited in many real-world scenarios, a.k.a, low-resource KT datasets. Directly training a DLKT model on a low-resource KT dataset may lead to overfitting and it is difficult to choose the appropriate deep neural architecture. Therefore, in this paper, we propose a low-resource KT framework called LoReKT to address above challenges. Inspired by the prevalent "pre-training and fine-tuning" paradigm, we aim to learn transferable parameters and representations from rich-resource KT datasets during the pre-training stage and subsequently facilitate effective adaptation to low-resource KT datasets. Specifically, we simplify existing sophisticated DLKT model architectures with purely a stack of transformer decoders. We design an encoding mechanism to incorporate student interactions from multiple KT data sources and develop an importance mechanism to prioritize updating parameters with high importance while constraining less important ones during the fine-tuning stage. We evaluate LoReKT on six public KT datasets and experimental results demonstrate the superiority of our approach in terms of AUC and Accuracy. To encourage reproducible research, we make our data and code publicly available at https://anonymous.4open.science/r/LoReKT-C619.
Assisting Language Learners: Automated Trans-Lingual Definition Generation via Contrastive Prompt Learning
Jun 09, 2023The standard definition generation task requires to automatically produce mono-lingual definitions (e.g., English definitions for English words), but ignores that the generated definitions may also consist of unfamiliar words for language learners. In this work, we propose a novel task of Trans-Lingual Definition Generation (TLDG), which aims to generate definitions in another language, i.e., the native speaker's language. Initially, we explore the unsupervised manner of this task and build up a simple implementation of fine-tuning the multi-lingual machine translation model. Then, we develop two novel methods, Prompt Combination and Contrastive Prompt Learning, for further enhancing the quality of the generation. Our methods are evaluated against the baseline Pipeline method in both rich- and low-resource settings, and we empirically establish its superiority in generating higher-quality trans-lingual definitions.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
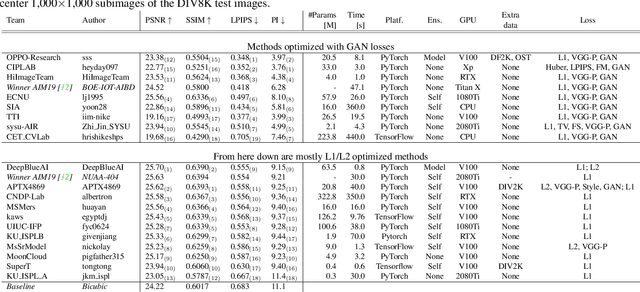

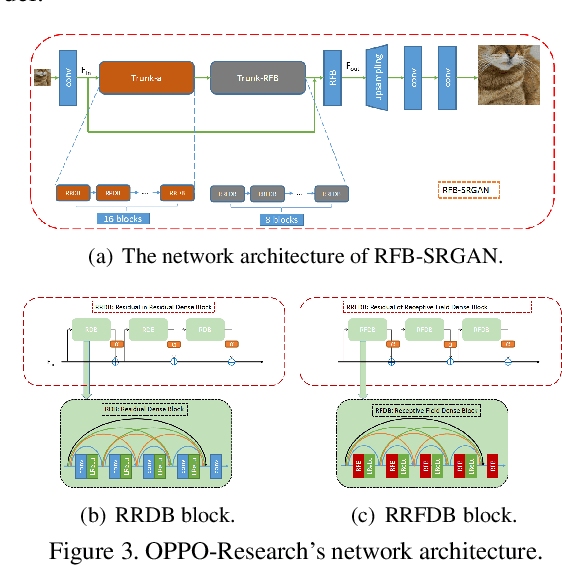
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.