 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTessellation GS: Neural Mesh Gaussians for Robust Monocular Reconstruction of Dynamic Objects
Dec 08, 20253D Gaussian Splatting (GS) enables highly photorealistic scene reconstruction from posed image sequences but struggles with viewpoint extrapolation due to its anisotropic nature, leading to overfitting and poor generalization, particularly in sparse-view and dynamic scene reconstruction. We propose Tessellation GS, a structured 2D GS approach anchored on mesh faces, to reconstruct dynamic scenes from a single continuously moving or static camera. Our method constrains 2D Gaussians to localized regions and infers their attributes via hierarchical neural features on mesh faces. Gaussian subdivision is guided by an adaptive face subdivision strategy driven by a detail-aware loss function. Additionally, we leverage priors from a reconstruction foundation model to initialize Gaussian deformations, enabling robust reconstruction of general dynamic objects from a single static camera, previously extremely challenging for optimization-based methods. Our method outperforms previous SOTA method, reducing LPIPS by 29.1% and Chamfer distance by 49.2% on appearance and mesh reconstruction tasks.
FlashMesh: Faster and Better Autoregressive Mesh Synthesis via Structured Speculation
Nov 19, 2025Autoregressive models can generate high-quality 3D meshes by sequentially producing vertices and faces, but their token-by-token decoding results in slow inference, limiting practical use in interactive and large-scale applications. We present FlashMesh, a fast and high-fidelity mesh generation framework that rethinks autoregressive decoding through a predict-correct-verify paradigm. The key insight is that mesh tokens exhibit strong structural and geometric correlations that enable confident multi-token speculation. FlashMesh leverages this by introducing a speculative decoding scheme tailored to the commonly used hourglass transformer architecture, enabling parallel prediction across face, point, and coordinate levels. Extensive experiments show that FlashMesh achieves up to a 2 x speedup over standard autoregressive models while also improving generation fidelity. Our results demonstrate that structural priors in mesh data can be systematically harnessed to accelerate and enhance autoregressive generation.
LSS3D: Learnable Spatial Shifting for Consistent and High-Quality 3D Generation from Single-Image
Nov 15, 2025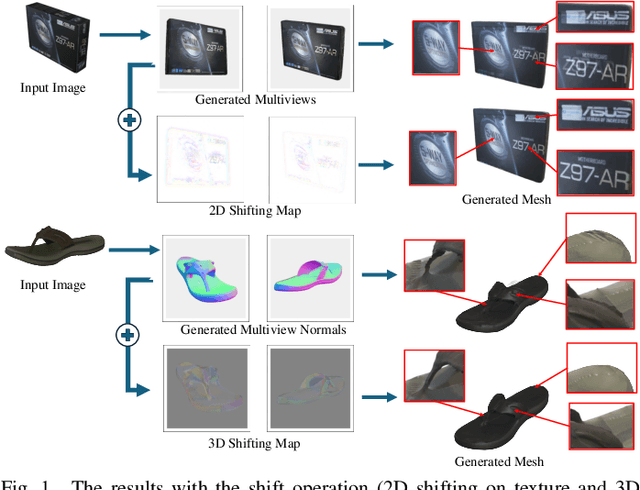
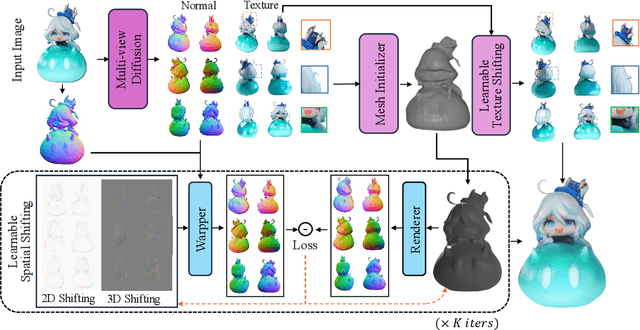

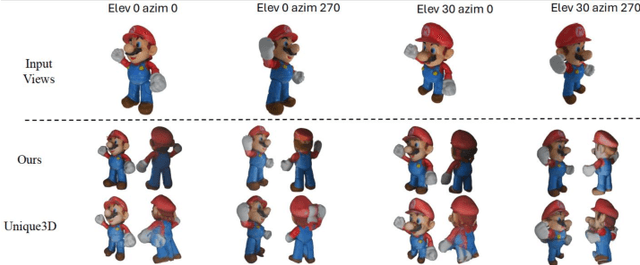
Recently, multi-view diffusion-based 3D generation methods have gained significant attention. However, these methods often suffer from shape and texture misalignment across generated multi-view images, leading to low-quality 3D generation results, such as incomplete geometric details and textural ghosting. Some methods are mainly optimized for the frontal perspective and exhibit poor robustness to oblique perspective inputs. In this paper, to tackle the above challenges, we propose a high-quality image-to-3D approach, named LSS3D, with learnable spatial shifting to explicitly and effectively handle the multiview inconsistencies and non-frontal input view. Specifically, we assign learnable spatial shifting parameters to each view, and adjust each view towards a spatially consistent target, guided by the reconstructed mesh, resulting in high-quality 3D generation with more complete geometric details and clean textures. Besides, we include the input view as an extra constraint for the optimization, further enhancing robustness to non-frontal input angles, especially for elevated viewpoint inputs. We also provide a comprehensive quantitative evaluation pipeline that can contribute to the community in performance comparisons. Extensive experiments demonstrate that our method consistently achieves leading results in both geometric and texture evaluation metrics across more flexible input viewpoints.
Incremental Residual Concept Bottleneck Models
Apr 13, 2024



Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
Context-aware Talking Face Video Generation
Feb 28, 2024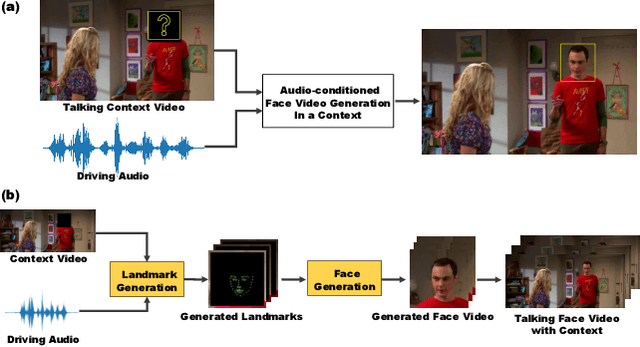
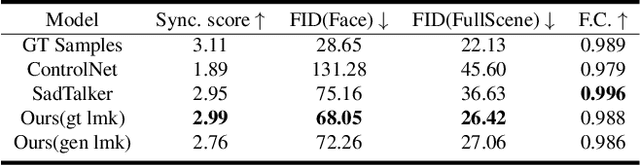
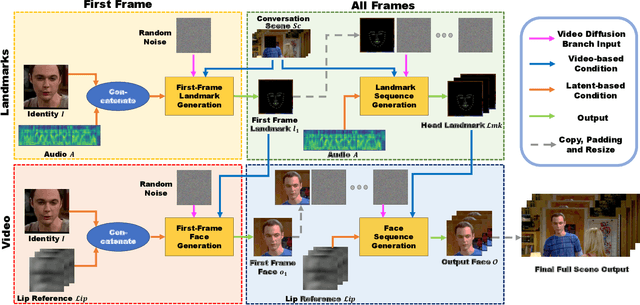
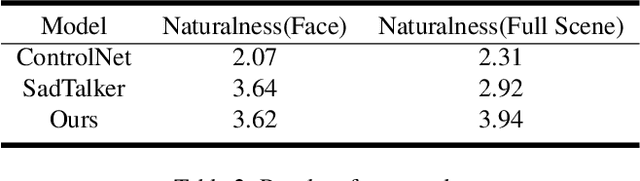
In this paper, we consider a novel and practical case for talking face video generation. Specifically, we focus on the scenarios involving multi-people interactions, where the talking context, such as audience or surroundings, is present. In these situations, the video generation should take the context into consideration in order to generate video content naturally aligned with driving audios and spatially coherent to the context. To achieve this, we provide a two-stage and cross-modal controllable video generation pipeline, taking facial landmarks as an explicit and compact control signal to bridge the driving audio, talking context and generated videos. Inside this pipeline, we devise a 3D video diffusion model, allowing for efficient contort of both spatial conditions (landmarks and context video), as well as audio condition for temporally coherent generation. The experimental results verify the advantage of the proposed method over other baselines in terms of audio-video synchronization, video fidelity and frame consistency.
DisControlFace: Disentangled Control for Personalized Facial Image Editing
Dec 11, 2023



In this work, we focus on exploring explicit fine-grained control of generative facial image editing, all while generating faithful and consistent personalized facial appearances. We identify the key challenge of this task as the exploration of disentangled conditional control in the generation process, and accordingly propose a novel diffusion-based framework, named DisControlFace, comprising two decoupled components. Specifically, we leverage an off-the-shelf diffusion reconstruction model as the backbone and freeze its pre-trained weights, which helps to reduce identity shift and recover editing-unrelated details of the input image. Furthermore, we construct a parallel control network that is compatible with the reconstruction backbone to generate spatial control conditions based on estimated explicit face parameters. Finally, we further reformulate the training pipeline into a masked-autoencoding form to effectively achieve disentangled training of our DisControlFace. Our DisControlNet can perform robust editing on any facial image through training on large-scale 2D in-the-wild portraits and also supports low-cost fine-tuning with few additional images to further learn diverse personalized priors of a specific person. Extensive experiments demonstrate that DisControlFace can generate realistic facial images corresponding to various face control conditions, while significantly improving the preservation of the personalized facial details.
How does representation impact in-context learning: A exploration on a synthetic task
Sep 12, 2023



In-context learning, i.e., learning from in-context samples, is an impressive ability of Transformer. However, the mechanism driving the in-context learning is not yet fully understood. In this study, we aim to investigate from an underexplored perspective of representation learning. The representation is more complex for in-context learning senario, where the representation can be impacted by both model weights and in-context samples. We refer the above two conceptually aspects of representation as in-weight component and in-context component, respectively. To study how the two components affect in-context learning capabilities, we construct a novel synthetic task, making it possible to device two probes, in-weights probe and in-context probe, to evaluate the two components, respectively. We demonstrate that the goodness of in-context component is highly related to the in-context learning performance, which indicates the entanglement between in-context learning and representation learning. Furthermore, we find that a good in-weights component can actually benefit the learning of the in-context component, indicating that in-weights learning should be the foundation of in-context learning. To further understand the the in-context learning mechanism and importance of the in-weights component, we proof by construction that a simple Transformer, which uses pattern matching and copy-past mechanism to perform in-context learning, can match the in-context learning performance with more complex, best tuned Transformer under the perfect in-weights component assumption. In short, those discoveries from representation learning perspective shed light on new approaches to improve the in-context capacity.
Shape Guided Gradient Voting for Domain Generalization
Jun 19, 2023



Domain generalization aims to address the domain shift between training and testing data. To learn the domain invariant representations, the model is usually trained on multiple domains. It has been found that the gradients of network weight relative to a specific task loss can characterize the task itself. In this work, with the assumption that the gradients of a specific domain samples under the classification task could also reflect the property of the domain, we propose a Shape Guided Gradient Voting (SGGV) method for domain generalization. Firstly, we introduce shape prior via extra inputs of the network to guide gradient descending towards a shape-biased direction for better generalization. Secondly, we propose a new gradient voting strategy to remove the outliers for robust optimization in the presence of shape guidance. To provide shape guidance, we add edge/sketch extracted from the training data as an explicit way, and also use texture augmented images as an implicit way. We conduct experiments on several popular domain generalization datasets in image classification task, and show that our shape guided gradient updating strategy brings significant improvement of the generalization.
Vector-based Representation is the Key: A Study on Disentanglement and Compositional Generalization
May 29, 2023



Recognizing elementary underlying concepts from observations (disentanglement) and generating novel combinations of these concepts (compositional generalization) are fundamental abilities for humans to support rapid knowledge learning and generalize to new tasks, with which the deep learning models struggle. Towards human-like intelligence, various works on disentangled representation learning have been proposed, and recently some studies on compositional generalization have been presented. However, few works study the relationship between disentanglement and compositional generalization, and the observed results are inconsistent. In this paper, we study several typical disentangled representation learning works in terms of both disentanglement and compositional generalization abilities, and we provide an important insight: vector-based representation (using a vector instead of a scalar to represent a concept) is the key to empower both good disentanglement and strong compositional generalization. This insight also resonates the neuroscience research that the brain encodes information in neuron population activity rather than individual neurons. Motivated by this observation, we further propose a method to reform the scalar-based disentanglement works ($\beta$-TCVAE and FactorVAE) to be vector-based to increase both capabilities. We investigate the impact of the dimensions of vector-based representation and one important question: whether better disentanglement indicates higher compositional generalization. In summary, our study demonstrates that it is possible to achieve both good concept recognition and novel concept composition, contributing an important step towards human-like intelligence.
Super-NeRF: View-consistent Detail Generation for NeRF super-resolution
Apr 26, 2023



The neural radiance field (NeRF) achieved remarkable success in modeling 3D scenes and synthesizing high-fidelity novel views. However, existing NeRF-based methods focus more on the make full use of the image resolution to generate novel views, but less considering the generation of details under the limited input resolution. In analogy to the extensive usage of image super-resolution, NeRF super-resolution is an effective way to generate the high-resolution implicit representation of 3D scenes and holds great potential applications. Up to now, such an important topic is still under-explored. In this paper, we propose a NeRF super-resolution method, named Super-NeRF, to generate high-resolution NeRF from only low-resolution inputs. Given multi-view low-resolution images, Super-NeRF constructs a consistency-controlling super-resolution module to generate view-consistent high-resolution details for NeRF. Specifically, an optimizable latent code is introduced for each low-resolution input image to control the 2D super-resolution images to converge to the view-consistent output. The latent codes of each low-resolution image are optimized synergistically with the target Super-NeRF representation to fully utilize the view consistency constraint inherent in NeRF construction. We verify the effectiveness of Super-NeRF on synthetic, real-world, and AI-generated NeRF datasets. Super-NeRF achieves state-of-the-art NeRF super-resolution performance on high-resolution detail generation and cross-view consistency.