 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO-IOD: Towards Real Time Incremental Object Detection
Dec 28, 2025Current methods for incremental object detection (IOD) primarily rely on Faster R-CNN or DETR series detectors; however, these approaches do not accommodate the real-time YOLO detection frameworks. In this paper, we first identify three primary types of knowledge conflicts that contribute to catastrophic forgetting in YOLO-based incremental detectors: foreground-background confusion, parameter interference, and misaligned knowledge distillation. Subsequently, we introduce YOLO-IOD, a real-time Incremental Object Detection (IOD) framework that is constructed upon the pretrained YOLO-World model, facilitating incremental learning via a stage-wise parameter-efficient fine-tuning process. Specifically, YOLO-IOD encompasses three principal components: 1) Conflict-Aware Pseudo-Label Refinement (CPR), which mitigates the foreground-background confusion by leveraging the confidence levels of pseudo labels and identifying potential objects relevant to future tasks. 2) Importancebased Kernel Selection (IKS), which identifies and updates the pivotal convolution kernels pertinent to the current task during the current learning stage. 3) Cross-Stage Asymmetric Knowledge Distillation (CAKD), which addresses the misaligned knowledge distillation conflict by transmitting the features of the student target detector through the detection heads of both the previous and current teacher detectors, thereby facilitating asymmetric distillation between existing and newly introduced categories. We further introduce LoCo COCO, a more realistic benchmark that eliminates data leakage across stages. Experiments on both conventional and LoCo COCO benchmarks show that YOLO-IOD achieves superior performance with minimal forgetting.
AutoMetrics: Approximate Human Judgements with Automatically Generated Evaluators
Dec 19, 2025Evaluating user-facing AI applications remains a central challenge, especially in open-ended domains such as travel planning, clinical note generation, or dialogue. The gold standard is user feedback (e.g., thumbs up/down) or behavioral signals (e.g., retention), but these are often scarce in prototypes and research projects, or too-slow to use for system optimization. We present AutoMetrics, a framework for synthesizing evaluation metrics under low-data constraints. AutoMetrics combines retrieval from MetricBank, a collection of 48 metrics we curate, with automatically generated LLM-as-a-Judge criteria informed by lightweight human feedback. These metrics are composed via regression to maximize correlation with human signal. AutoMetrics takes you from expensive measures to interpretable automatic metrics. Across 5 diverse tasks, AutoMetrics improves Kendall correlation with human ratings by up to 33.4% over LLM-as-a-Judge while requiring fewer than 100 feedback points. We show that AutoMetrics can be used as a proxy reward to equal effect as a verifiable reward. We release the full AutoMetrics toolkit and MetricBank to accelerate adaptive evaluation of LLM applications.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
Artificial Intelligence Augmented Medical Imaging Reconstruction in Radiation Therapy
Apr 10, 2025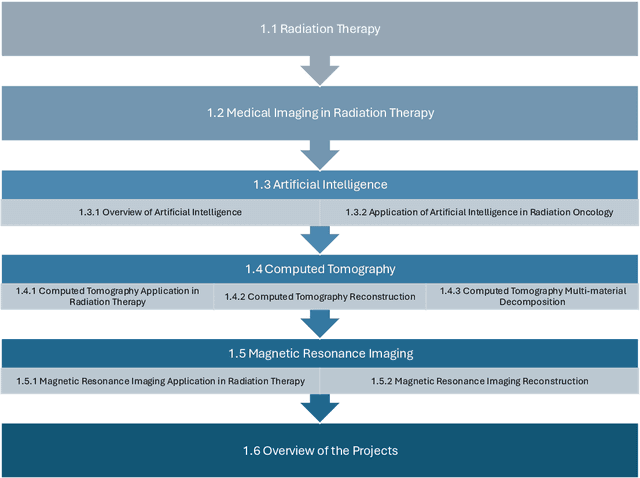

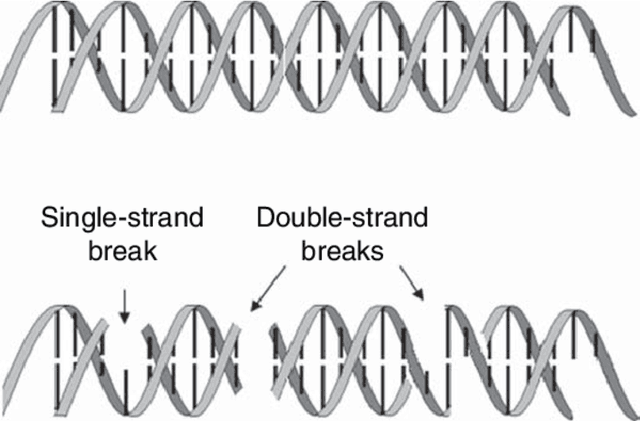
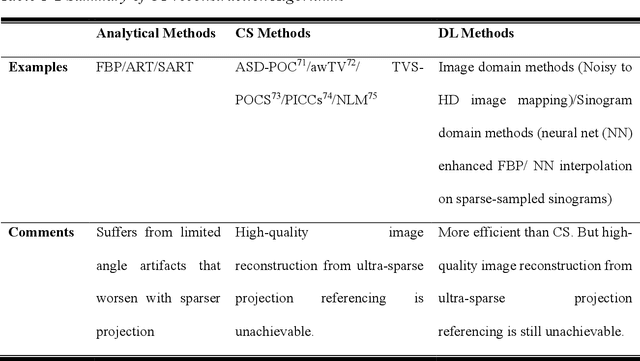
Efficiently acquired and precisely reconstructed imaging are crucial to the success of modern radiation therapy (RT). Computed tomography (CT) and magnetic resonance imaging (MRI) are two common modalities for providing RT treatment planning and delivery guidance/monitoring. In recent decades, artificial intelligence (AI) has emerged as a powerful and widely adopted technique across various fields, valued for its efficiency and convenience enabled by implicit function definition and data-driven feature representation learning. Here, we present a series of AI-driven medical imaging reconstruction frameworks for enhanced radiotherapy, designed to improve CT image reconstruction quality and speed, refine dual-energy CT (DECT) multi-material decomposition (MMD), and significantly accelerate 4D MRI acquisition.
Accelerated Patient-specific Non-Cartesian MRI Reconstruction using Implicit Neural Representations
Mar 07, 2025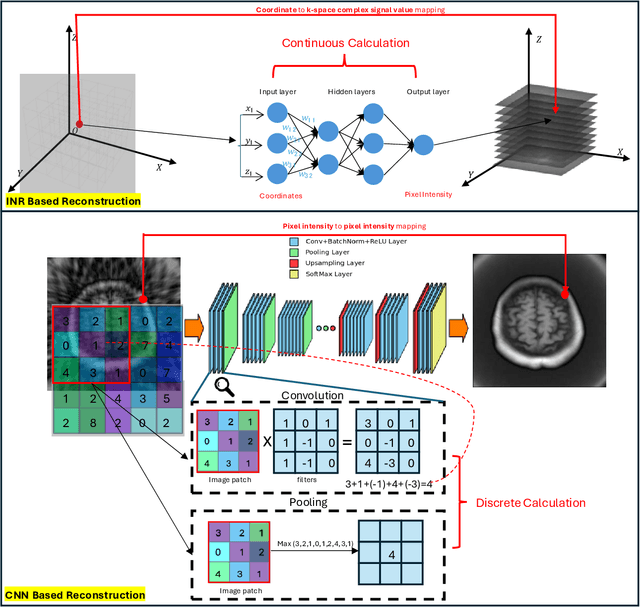
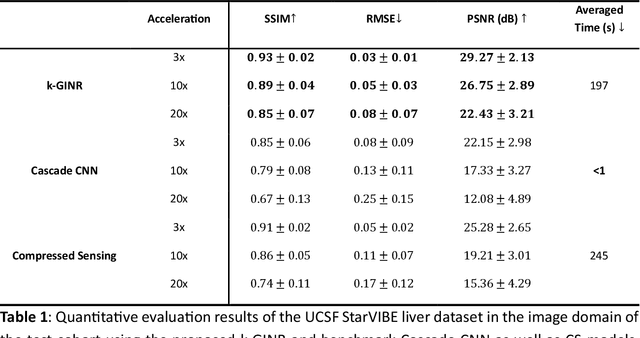
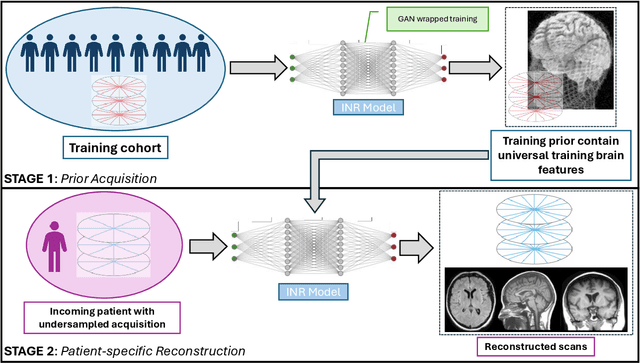
The scanning time for a fully sampled MRI can be undesirably lengthy. Compressed sensing has been developed to minimize image artifacts in accelerated scans, but the required iterative reconstruction is computationally complex and difficult to generalize on new cases. Image-domain-based deep learning methods (e.g., convolutional neural networks) emerged as a faster alternative but face challenges in modeling continuous k-space, a problem amplified with non-Cartesian sampling commonly used in accelerated acquisition. In comparison, implicit neural representations can model continuous signals in the frequency domain and thus are compatible with arbitrary k-space sampling patterns. The current study develops a novel generative-adversarially trained implicit neural representations (k-GINR) for de novo undersampled non-Cartesian k-space reconstruction. k-GINR consists of two stages: 1) supervised training on an existing patient cohort; 2) self-supervised patient-specific optimization. In stage 1, the network is trained with the generative-adversarial network on diverse patients of the same anatomical region supervised by fully sampled acquisition. In stage 2, undersampled k-space data of individual patients is used to tailor the prior-embedded network for patient-specific optimization. The UCSF StarVIBE T1-weighted liver dataset was evaluated on the proposed framework. k-GINR is compared with an image-domain deep learning method, Deep Cascade CNN, and a compressed sensing method. k-GINR consistently outperformed the baselines with a larger performance advantage observed at very high accelerations (e.g., 20 times). k-GINR offers great value for direct non-Cartesian k-space reconstruction for new incoming patients across a wide range of accelerations liver anatomy.
Demystifying Catastrophic Forgetting in Two-Stage Incremental Object Detector
Feb 08, 2025Catastrophic forgetting is a critical chanllenge for incremental object detection (IOD). Most existing methods treat the detector monolithically, relying on instance replay or knowledge distillation without analyzing component-specific forgetting. Through dissection of Faster R-CNN, we reveal a key insight: Catastrophic forgetting is predominantly localized to the RoI Head classifier, while regressors retain robustness across incremental stages. This finding challenges conventional assumptions, motivating us to develop a framework termed NSGP-RePRE. Regional Prototype Replay (RePRE) mitigates classifier forgetting via replay of two types of prototypes: coarse prototypes represent class-wise semantic centers of RoI features, while fine-grained prototypes model intra-class variations. Null Space Gradient Projection (NSGP) is further introduced to eliminate prototype-feature misalignment by updating the feature extractor in directions orthogonal to subspace of old inputs via gradient projection, aligning RePRE with incremental learning dynamics. Our simple yet effective design allows NSGP-RePRE to achieve state-of-the-art performance on the Pascal VOC and MS COCO datasets under various settings. Our work not only advances IOD methodology but also provide pivotal insights for catastrophic forgetting mitigation in IOD. Code will be available soon.
Rapid Reconstruction of Extremely Accelerated Liver 4D MRI via Chained Iterative Refinement
Dec 14, 2024



Abstract Purpose: High-quality 4D MRI requires an impractically long scanning time for dense k-space signal acquisition covering all respiratory phases. Accelerated sparse sampling followed by reconstruction enhancement is desired but often results in degraded image quality and long reconstruction time. We hereby propose the chained iterative reconstruction network (CIRNet) for efficient sparse-sampling reconstruction while maintaining clinically deployable quality. Methods: CIRNet adopts the denoising diffusion probabilistic framework to condition the image reconstruction through a stochastic iterative denoising process. During training, a forward Markovian diffusion process is designed to gradually add Gaussian noise to the densely sampled ground truth (GT), while CIRNet is optimized to iteratively reverse the Markovian process from the forward outputs. At the inference stage, CIRNet performs the reverse process solely to recover signals from noise, conditioned upon the undersampled input. CIRNet processed the 4D data (3D+t) as temporal slices (2D+t). The proposed framework is evaluated on a data cohort consisting of 48 patients (12332 temporal slices) who underwent free-breathing liver 4D MRI. 3-, 6-, 10-, 20- and 30-times acceleration were examined with a retrospective random undersampling scheme. Compressed sensing (CS) reconstruction with a spatiotemporal constraint and a recently proposed deep network, Re-Con-GAN, are selected as baselines. Results: CIRNet consistently achieved superior performance compared to CS and Re-Con-GAN. The inference time of CIRNet, CS, and Re-Con-GAN are 11s, 120s, and 0.15s. Conclusion: A novel framework, CIRNet, is presented. CIRNet maintains useable image quality for acceleration up to 30 times, significantly reducing the burden of 4DMRI.
TomoGRAF: A Robust and Generalizable Reconstruction Network for Single-View Computed Tomography
Nov 12, 2024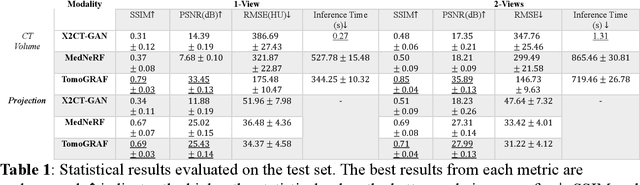

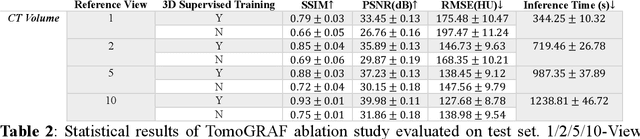

Computed tomography (CT) provides high spatial resolution visualization of 3D structures for scientific and clinical applications. Traditional analytical/iterative CT reconstruction algorithms require hundreds of angular data samplings, a condition that may not be met in practice due to physical and mechanical limitations. Sparse view CT reconstruction has been proposed using constrained optimization and machine learning methods with varying success, less so for ultra-sparse view CT reconstruction with one to two views. Neural radiance field (NeRF) is a powerful tool for reconstructing and rendering 3D natural scenes from sparse views, but its direct application to 3D medical image reconstruction has been minimally successful due to the differences between optical and X-ray photon transportation. Here, we develop a novel TomoGRAF framework incorporating the unique X-ray transportation physics to reconstruct high-quality 3D volumes using ultra-sparse projections without prior. TomoGRAF captures the CT imaging geometry, simulates the X-ray casting and tracing process, and penalizes the difference between simulated and ground truth CT sub-volume during training. We evaluated the performance of TomoGRAF on an unseen dataset of distinct imaging characteristics from the training data and demonstrated a vast leap in performance compared with state-of-the-art deep learning and NeRF methods. TomoGRAF provides the first generalizable solution for image-guided radiotherapy and interventional radiology applications, where only one or a few X-ray views are available, but 3D volumetric information is desired.
EVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024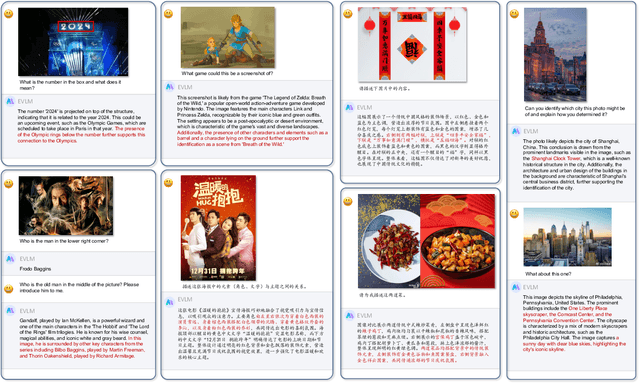
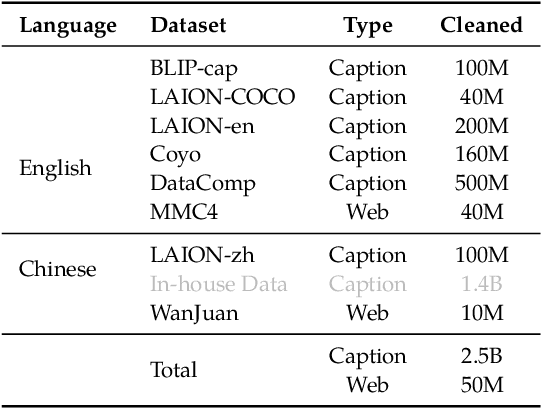
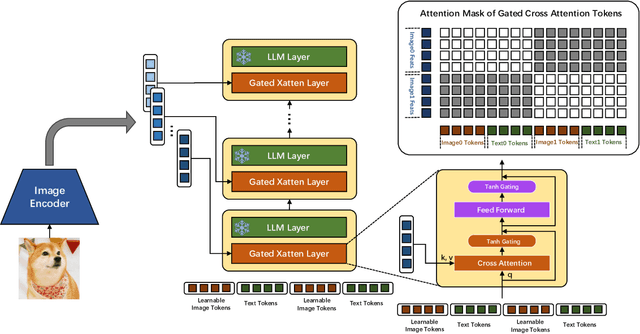

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.
Paired Conditional Generative Adversarial Network for Highly Accelerated Liver 4D MRI
May 20, 2024Purpose: 4D MRI with high spatiotemporal resolution is desired for image-guided liver radiotherapy. Acquiring densely sampling k-space data is time-consuming. Accelerated acquisition with sparse samples is desirable but often causes degraded image quality or long reconstruction time. We propose the Reconstruct Paired Conditional Generative Adversarial Network (Re-Con-GAN) to shorten the 4D MRI reconstruction time while maintaining the reconstruction quality. Methods: Patients who underwent free-breathing liver 4D MRI were included in the study. Fully- and retrospectively under-sampled data at 3, 6 and 10 times (3x, 6x and 10x) were first reconstructed using the nuFFT algorithm. Re-Con-GAN then trained input and output in pairs. Three types of networks, ResNet9, UNet and reconstruction swin transformer, were explored as generators. PatchGAN was selected as the discriminator. Re-Con-GAN processed the data (3D+t) as temporal slices (2D+t). A total of 48 patients with 12332 temporal slices were split into training (37 patients with 10721 slices) and test (11 patients with 1611 slices). Results: Re-Con-GAN consistently achieved comparable/better PSNR, SSIM, and RMSE scores compared to CS/UNet models. The inference time of Re-Con-GAN, UNet and CS are 0.15s, 0.16s, and 120s. The GTV detection task showed that Re-Con-GAN and CS, compared to UNet, better improved the dice score (3x Re-Con-GAN 80.98%; 3x CS 80.74%; 3x UNet 79.88%) of unprocessed under-sampled images (3x 69.61%). Conclusion: A generative network with adversarial training is proposed with promising and efficient reconstruction results demonstrated on an in-house dataset. The rapid and qualitative reconstruction of 4D liver MR has the potential to facilitate online adaptive MR-guided radiotherapy for liver cancer.