 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Efficient Transfer Learning with Fading Side Networks via Masked Dual Path Distillation
Apr 10, 2026Memory-efficient transfer learning (METL) approaches have recently achieved promising performance in adapting pre-trained models to downstream tasks. They avoid applying gradient backpropagation in large backbones, thus significantly reducing the number of trainable parameters and high memory consumption during fine-tuning. However, since they typically employ a lightweight and learnable side network, these methods inevitably introduce additional memory and time overhead during inference, which contradicts the ultimate goal of efficient transfer learning. To address the above issue, we propose a novel approach dubbed Masked Dual Path Distillation (MDPD) to accelerate inference while retaining parameter and memory efficiency in fine-tuning with fading side networks. Specifically, MDPD develops a framework that enhances the performance by mutually distilling the frozen backbones and learnable side networks in fine-tuning, and discard the side network during inference without sacrificing accuracy. Moreover, we design a novel feature-based knowledge distillation method for the encoder structure with multiple layers. Extensive experiments on distinct backbones across vision/language-only and vision-and-language tasks demonstrate that our method not only accelerates inference by at least 25.2\% while keeping parameter and memory consumption comparable, but also remarkably promotes the accuracy compared to SOTA approaches. The source code is available at https://github.com/Zhang-VKk/MDPD.
Transforming Vision Transformer: Towards Efficient Multi-Task Asynchronous Learning
Jan 12, 2025



Multi-Task Learning (MTL) for Vision Transformer aims at enhancing the model capability by tackling multiple tasks simultaneously. Most recent works have predominantly focused on designing Mixture-of-Experts (MoE) structures and in tegrating Low-Rank Adaptation (LoRA) to efficiently perform multi-task learning. However, their rigid combination hampers both the optimization of MoE and the ef fectiveness of reparameterization of LoRA, leading to sub-optimal performance and low inference speed. In this work, we propose a novel approach dubbed Efficient Multi-Task Learning (EMTAL) by transforming a pre-trained Vision Transformer into an efficient multi-task learner during training, and reparameterizing the learned structure for efficient inference. Specifically, we firstly develop the MoEfied LoRA structure, which decomposes the pre-trained Transformer into a low-rank MoE structure and employ LoRA to fine-tune the parameters. Subsequently, we take into account the intrinsic asynchronous nature of multi-task learning and devise a learning Quality Retaining (QR) optimization mechanism, by leveraging the historical high-quality class logits to prevent a well-trained task from performance degradation. Finally, we design a router fading strategy to integrate the learned parameters into the original Transformer, archiving efficient inference. Extensive experiments on public benchmarks demonstrate the superiority of our method, compared to the state-of-the-art multi-task learning approaches.
EVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024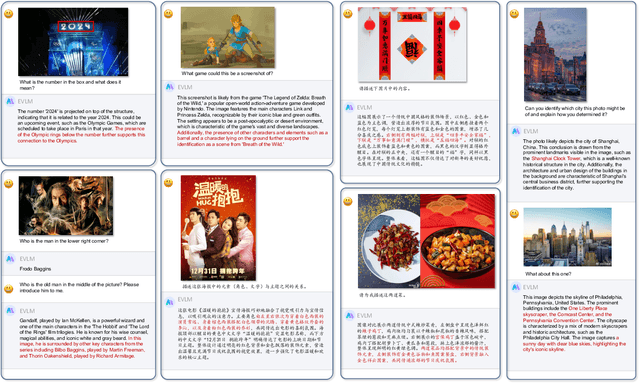
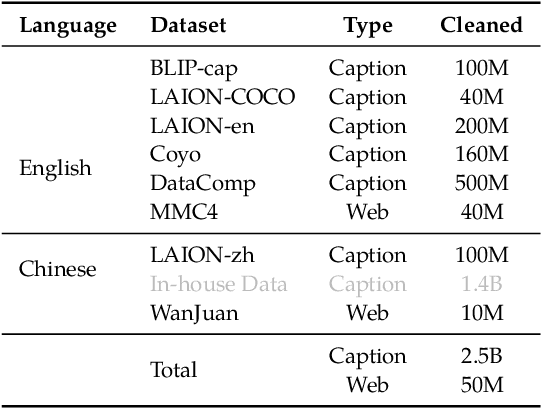
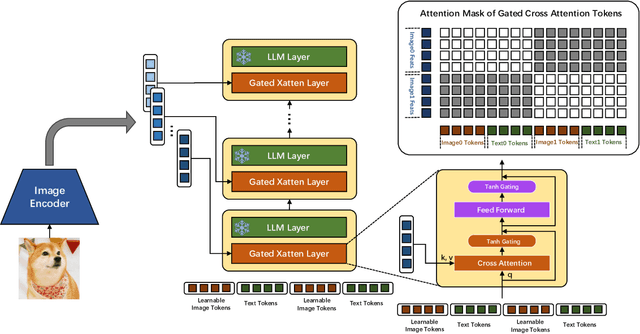

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.
AdaLog: Post-Training Quantization for Vision Transformers with Adaptive Logarithm Quantizer
Jul 17, 2024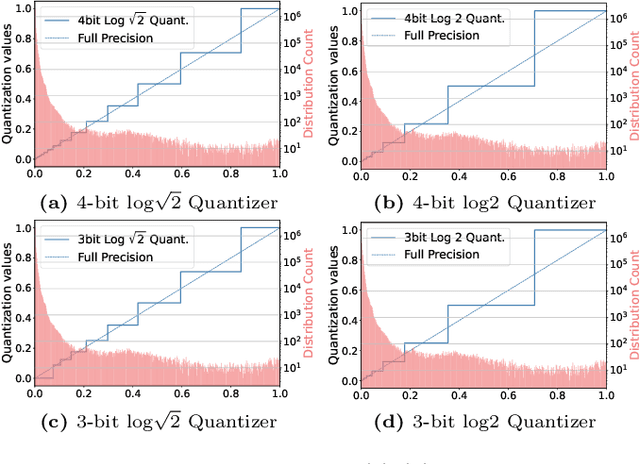
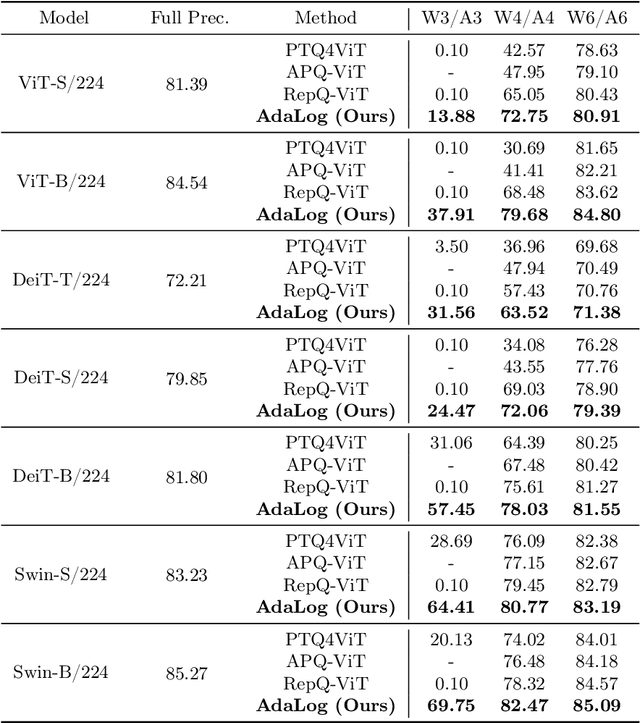
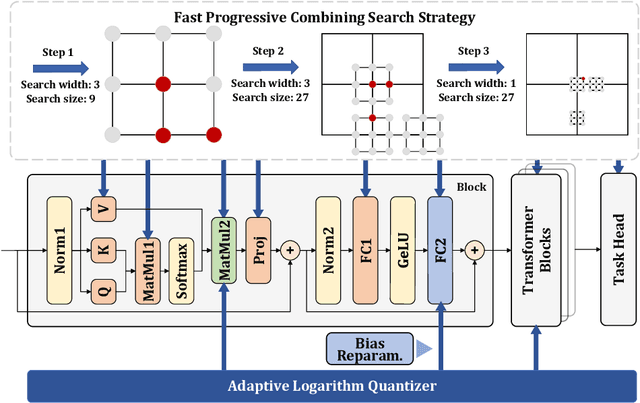
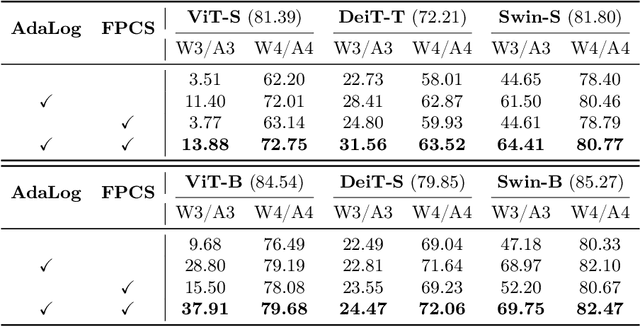
Vision Transformer (ViT) has become one of the most prevailing fundamental backbone networks in the computer vision community. Despite the high accuracy, deploying it in real applications raises critical challenges including the high computational cost and inference latency. Recently, the post-training quantization (PTQ) technique has emerged as a promising way to enhance ViT's efficiency. Nevertheless, existing PTQ approaches for ViT suffer from the inflexible quantization on the post-Softmax and post-GELU activations that obey the power-law-like distributions. To address these issues, we propose a novel non-uniform quantizer, dubbed the Adaptive Logarithm AdaLog (AdaLog) quantizer. It optimizes the logarithmic base to accommodate the power-law-like distribution of activations, while simultaneously allowing for hardware-friendly quantization and de-quantization. By employing the bias reparameterization, the AdaLog quantizer is applicable to both the post-Softmax and post-GELU activations. Moreover, we develop an efficient Fast Progressive Combining Search (FPCS) strategy to determine the optimal logarithm base for AdaLog, as well as the scaling factors and zero points for the uniform quantizers. Extensive experimental results on public benchmarks demonstrate the effectiveness of our approach for various ViT-based architectures and vision tasks including classification, object detection, and instance segmentation. Code is available at https://github.com/GoatWu/AdaLog.