 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Open Vocabulary: Multimodal Prompting for Object Detection in Remote Sensing Images
Feb 02, 2026Open-vocabulary object detection in remote sensing commonly relies on text-only prompting to specify target categories, implicitly assuming that inference-time category queries can be reliably grounded through pretraining-induced text-visual alignment. In practice, this assumption often breaks down in remote sensing scenarios due to task- and application-specific category semantics, resulting in unstable category specification under open-vocabulary settings. To address this limitation, we propose RS-MPOD, a multimodal open-vocabulary detection framework that reformulates category specification beyond text-only prompting by incorporating instance-grounded visual prompts, textual prompts, and their multimodal integration. RS-MPOD introduces a visual prompt encoder to extract appearance-based category cues from exemplar instances, enabling text-free category specification, and a multimodal fusion module to integrate visual and textual information when both modalities are available. Extensive experiments on standard, cross-dataset, and fine-grained remote sensing benchmarks show that visual prompting yields more reliable category specification under semantic ambiguity and distribution shifts, while multimodal prompting provides a flexible alternative that remains competitive when textual semantics are well aligned.
EntroCut: Entropy-Guided Adaptive Truncation for Efficient Chain-of-Thought Reasoning in Small-scale Large Reasoning Models
Jan 30, 2026Large Reasoning Models (LRMs) excel at complex reasoning tasks through extended chain-of-thought generation, but their reliance on lengthy intermediate steps incurs substantial computational cost. We find that the entropy of the model's output distribution in early reasoning steps reliably distinguishes correct from incorrect reasoning. Motivated by this observation, we propose EntroCut, a training-free method that dynamically truncates reasoning by identifying high-confidence states where reasoning can be safely terminated. To comprehensively evaluate the trade-off between efficiency and accuracy, we introduce the Efficiency-Performance Ratio (EPR), a unified metric that quantifies relative token savings per unit accuracy loss. Experiments on four benchmarks show that EntroCut reduces token usage by up to 40\% with minimal accuracy sacrifice, achieving superior efficiency-performance trade-offs compared with existing training-free methods. These results demonstrate that entropy-guided dynamic truncation provides a practical approach to mitigate the inefficiency of LRMs.
Probe and Skip: Self-Predictive Token Skipping for Efficient Long-Context LLM Inference
Jan 19, 2026Long-context inference enhances the reasoning capability of Large Language Models (LLMs) while incurring significant computational overhead. Token-oriented methods, such as pruning and skipping, have shown promise in reducing inference latency, but still suffer from inherently limited acceleration potential, outdated proxy signals, and redundancy interference, thus yielding suboptimal speed-accuracy trade-offs. To address these challenges, we propose SPTS (Self-Predictive Token Skipping), a training-free framework for efficient long-context LLM inference. Specifically, motivated by the thought of probing the influence of targeted skipping layers, we design two component-specific strategies for selective token skipping: Partial Attention Probing (PAP) for multi-head attention, which selects informative tokens by performing partial forward attention computation, and Low-rank Transformation Probing (LTP) for feed forward network, which constructs a low-rank proxy network to predict token transformations. Furthermore, a Multi-Stage Delayed Pruning (MSDP) strategy reallocates the skipping budget and progressively prunes redundant tokens across layers. Extensive experiments demonstrate the effectiveness of our method, achieving up to 2.46$\times$ and 2.29$\times$ speedups for prefilling and end-to-end generation, respectively, while maintaining state-of-the-art model performance. The source code will be publicly available upon paper acceptance.
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Dec 16, 2025This paper presents WorldPlay, a streaming video diffusion model that enables real-time, interactive world modeling with long-term geometric consistency, resolving the trade-off between speed and memory that limits current methods. WorldPlay draws power from three key innovations. 1) We use a Dual Action Representation to enable robust action control in response to the user's keyboard and mouse inputs. 2) To enforce long-term consistency, our Reconstituted Context Memory dynamically rebuilds context from past frames and uses temporal reframing to keep geometrically important but long-past frames accessible, effectively alleviating memory attenuation. 3) We also propose Context Forcing, a novel distillation method designed for memory-aware model. Aligning memory context between the teacher and student preserves the student's capacity to use long-range information, enabling real-time speeds while preventing error drift. Taken together, WorldPlay generates long-horizon streaming 720p video at 24 FPS with superior consistency, comparing favorably with existing techniques and showing strong generalization across diverse scenes. Project page and online demo can be found: https://3d-models.hunyuan.tencent.com/world/ and https://3d.hunyuan.tencent.com/sceneTo3D.
MSGNav: Unleashing the Power of Multi-modal 3D Scene Graph for Zero-Shot Embodied Navigation
Nov 14, 2025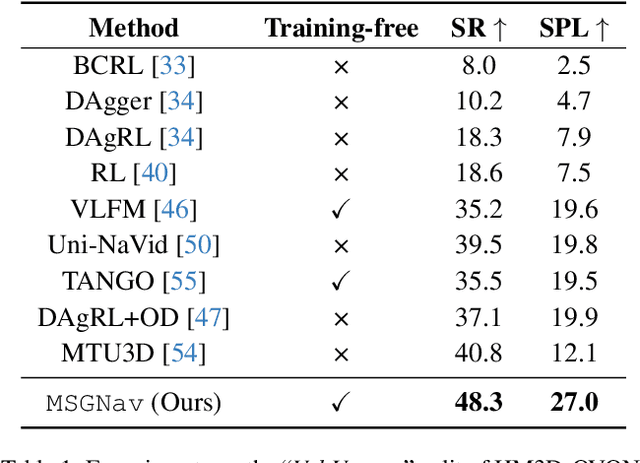
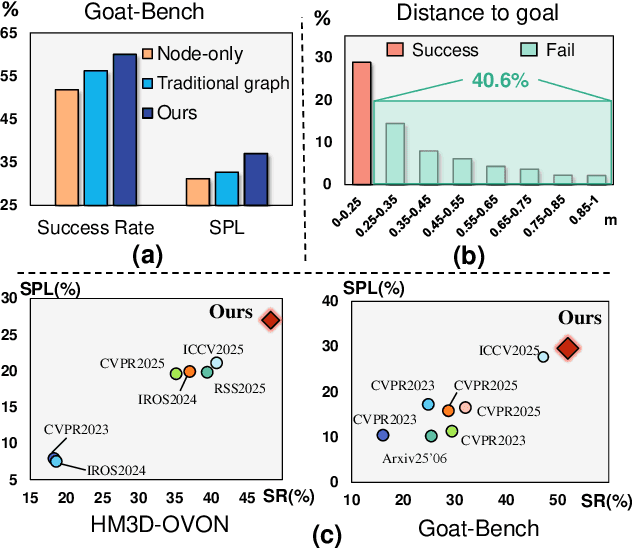
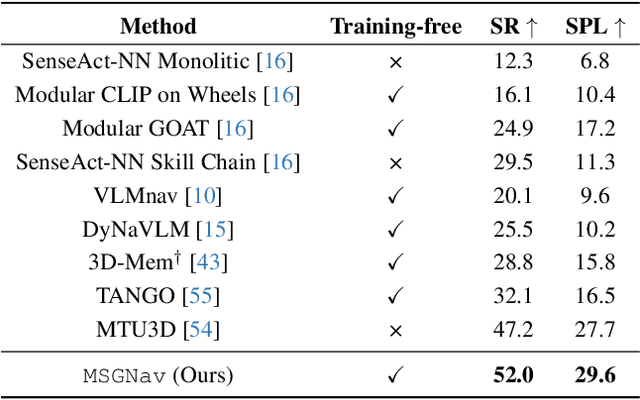
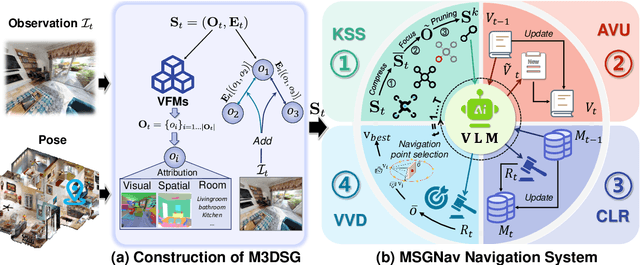
Embodied navigation is a fundamental capability for robotic agents operating. Real-world deployment requires open vocabulary generalization and low training overhead, motivating zero-shot methods rather than task-specific RL training. However, existing zero-shot methods that build explicit 3D scene graphs often compress rich visual observations into text-only relations, leading to high construction cost, irreversible loss of visual evidence, and constrained vocabularies. To address these limitations, we introduce the Multi-modal 3D Scene Graph (M3DSG), which preserves visual cues by replacing textual relation
TCM-Eval: An Expert-Level Dynamic and Extensible Benchmark for Traditional Chinese Medicine
Nov 10, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in modern medicine, yet their application in Traditional Chinese Medicine (TCM) remains severely limited by the absence of standardized benchmarks and the scarcity of high-quality training data. To address these challenges, we introduce TCM-Eval, the first dynamic and extensible benchmark for TCM, meticulously curated from national medical licensing examinations and validated by TCM experts. Furthermore, we construct a large-scale training corpus and propose Self-Iterative Chain-of-Thought Enhancement (SI-CoTE) to autonomously enrich question-answer pairs with validated reasoning chains through rejection sampling, establishing a virtuous cycle of data and model co-evolution. Using this enriched training data, we develop ZhiMingTang (ZMT), a state-of-the-art LLM specifically designed for TCM, which significantly exceeds the passing threshold for human practitioners. To encourage future research and development, we release a public leaderboard, fostering community engagement and continuous improvement.
Learn More, Forget Less: A Gradient-Aware Data Selection Approach for LLM
Nov 07, 2025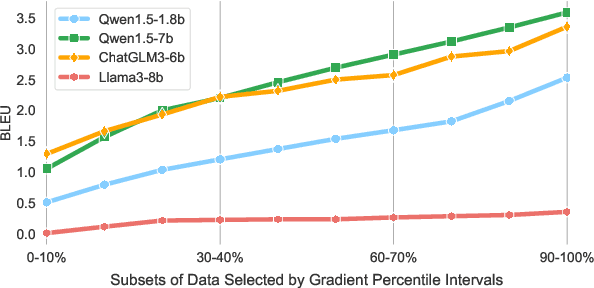
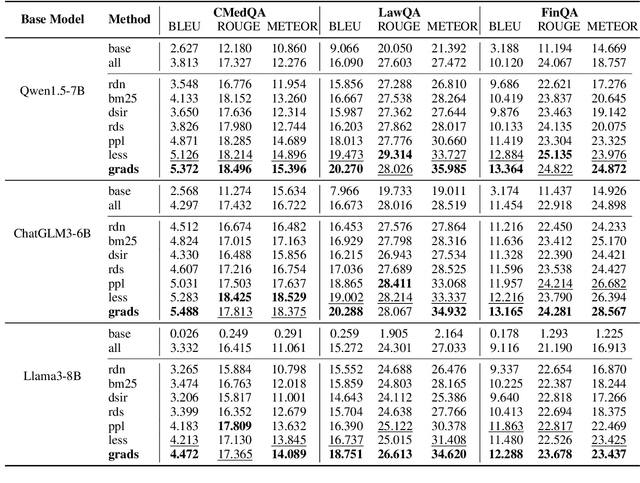
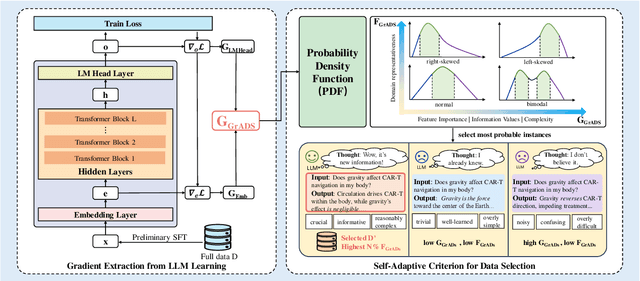
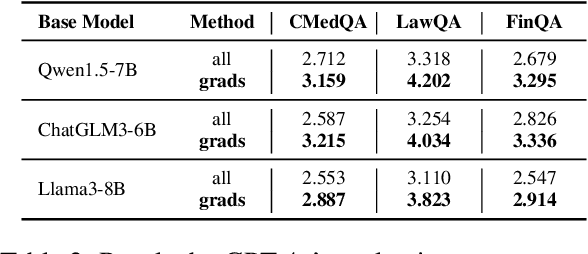
Despite large language models (LLMs) have achieved impressive achievements across numerous tasks, supervised fine-tuning (SFT) remains essential for adapting these models to specialized domains. However, SFT for domain specialization can be resource-intensive and sometimes leads to a deterioration in performance over general capabilities due to catastrophic forgetting (CF). To address these issues, we propose a self-adaptive gradient-aware data selection approach (GrADS) for supervised fine-tuning of LLMs, which identifies effective subsets of training data by analyzing gradients obtained from a preliminary training phase. Specifically, we design self-guided criteria that leverage the magnitude and statistical distribution of gradients to prioritize examples that contribute the most to the model's learning process. This approach enables the acquisition of representative samples that enhance LLMs understanding of domain-specific tasks. Through extensive experimentation with various LLMs across diverse domains such as medicine, law, and finance, GrADS has demonstrated significant efficiency and cost-effectiveness. Remarkably, utilizing merely 5% of the selected GrADS data, LLMs already surpass the performance of those fine-tuned on the entire dataset, and increasing to 50% of the data results in significant improvements! With catastrophic forgetting substantially mitigated simultaneously. We will release our code for GrADS later.
PolySim: Bridging the Sim-to-Real Gap for Humanoid Control via Multi-Simulator Dynamics Randomization
Oct 02, 2025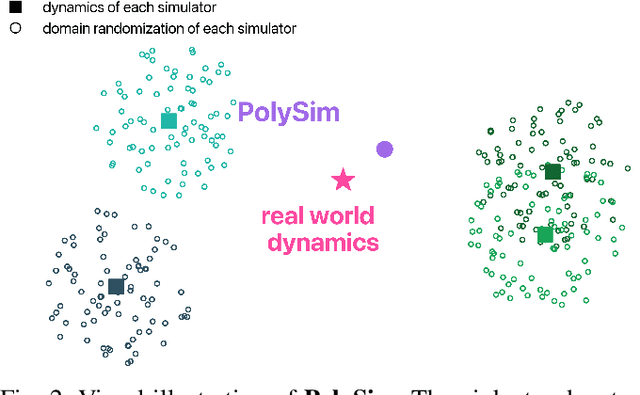
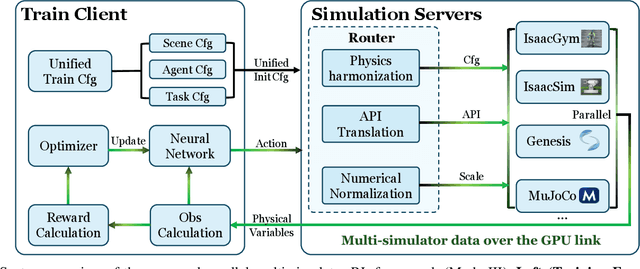
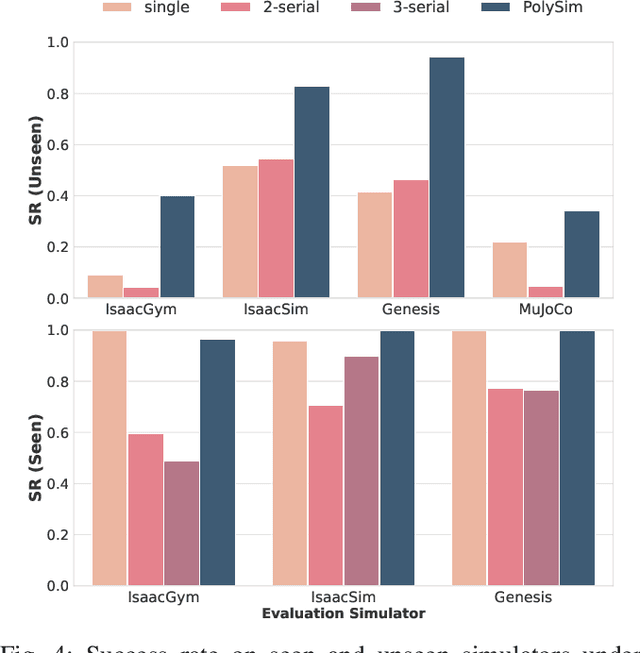

Humanoid whole-body control (WBC) policies trained in simulation often suffer from the sim-to-real gap, which fundamentally arises from simulator inductive bias, the inherent assumptions and limitations of any single simulator. These biases lead to nontrivial discrepancies both across simulators and between simulation and the real world. To mitigate the effect of simulator inductive bias, the key idea is to train policies jointly across multiple simulators, encouraging the learned controller to capture dynamics that generalize beyond any single simulator's assumptions. We thus introduce PolySim, a WBC training platform that integrates multiple heterogeneous simulators. PolySim can launch parallel environments from different engines simultaneously within a single training run, thereby realizing dynamics-level domain randomization. Theoretically, we show that PolySim yields a tighter upper bound on simulator inductive bias than single-simulator training. In experiments, PolySim substantially reduces motion-tracking error in sim-to-sim evaluations; for example, on MuJoCo, it improves execution success by 52.8 over an IsaacSim baseline. PolySim further enables zero-shot deployment on a real Unitree G1 without additional fine-tuning, showing effective transfer from simulation to the real world. We will release the PolySim code upon acceptance of this work.
RepoDebug: Repository-Level Multi-Task and Multi-Language Debugging Evaluation of Large Language Models
Sep 04, 2025Large Language Models (LLMs) have exhibited significant proficiency in code debugging, especially in automatic program repair, which may substantially reduce the time consumption of developers and enhance their efficiency. Significant advancements in debugging datasets have been made to promote the development of code debugging. However, these datasets primarily focus on assessing the LLM's function-level code repair capabilities, neglecting the more complex and realistic repository-level scenarios, which leads to an incomplete understanding of the LLM's challenges in repository-level debugging. While several repository-level datasets have been proposed, they often suffer from limitations such as limited diversity of tasks, languages, and error types. To mitigate this challenge, this paper introduces RepoDebug, a multi-task and multi-language repository-level code debugging dataset with 22 subtypes of errors that supports 8 commonly used programming languages and 3 debugging tasks. Furthermore, we conduct evaluation experiments on 10 LLMs, where Claude 3.5 Sonnect, the best-performing model, still cannot perform well in repository-level debugging.
FIMA-Q: Post-Training Quantization for Vision Transformers by Fisher Information Matrix Approximation
Jun 13, 2025Post-training quantization (PTQ) has stood out as a cost-effective and promising model compression paradigm in recent years, as it avoids computationally intensive model retraining. Nevertheless, current PTQ methods for Vision Transformers (ViTs) still suffer from significant accuracy degradation, especially under low-bit quantization. To address these shortcomings, we analyze the prevailing Hessian-guided quantization loss, and uncover certain limitations of conventional Hessian approximations. By following the block-wise reconstruction framework, we propose a novel PTQ method for ViTs, dubbed FIMA-Q. Specifically, we firstly establish the connection between KL divergence and FIM, which enables fast computation of the quantization loss during reconstruction. We further propose an efficient FIM approximation method, namely DPLR-FIM, by employing the diagonal plus low-rank principle, and formulate the ultimate quantization loss. Our extensive experiments, conducted across various vision tasks with representative ViT-based architectures on public datasets, demonstrate that our method substantially promotes the accuracy compared to the state-of-the-art approaches, especially in the case of low-bit quantization. The source code is available at https://github.com/ShiheWang/FIMA-Q.