 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment and multi-center evaluation of domain-adapted speech recognition for human-AI teaming in real-world gastrointestinal endoscopy
Apr 02, 2026Automatic speech recognition (ASR) is a critical interface for human-AI interaction in gastrointestinal endoscopy, yet its reliability in real-world clinical settings is limited by domain-specific terminology and complex acoustic conditions. Here, we present EndoASR, a domain-adapted ASR system designed for real-time deployment in endoscopic workflows. We develop a two-stage adaptation strategy based on synthetic endoscopy reports, targeting domain-specific language modeling and noise robustness. In retrospective evaluation across six endoscopists, EndoASR substantially improves both transcription accuracy and clinical usability, reducing character error rate (CER) from 20.52% to 14.14% and increasing medical term accuracy (Med ACC) from 54.30% to 87.59%. In a prospective multi-center study spanning five independent endoscopy centers, EndoASR demonstrates consistent generalization under heterogeneous real-world conditions. Compared with the baseline Paraformer model, CER is reduced from 16.20% to 14.97%, while Med ACC is improved from 61.63% to 84.16%, confirming its robustness in practical deployment scenarios. Notably, EndoASR achieves a real-time factor (RTF) of 0.005, significantly faster than Whisper-large-v3 (RTF 0.055), while maintaining a compact model size of 220M parameters, enabling efficient edge deployment. Furthermore, integration with large language models demonstrates that improved ASR quality directly enhances downstream structured information extraction and clinician-AI interaction. These results demonstrate that domain-adapted ASR can serve as a reliable interface for human-AI teaming in gastrointestinal endoscopy, with consistent performance validated across multi-center real-world clinical settings.
EndoFinder: Online Lesion Retrieval for Explainable Colorectal Polyp Diagnosis Leveraging Latent Scene Representations
Jul 23, 2025Colorectal cancer (CRC) remains a leading cause of cancer-related mortality, underscoring the importance of timely polyp detection and diagnosis. While deep learning models have improved optical-assisted diagnostics, they often demand extensive labeled datasets and yield "black-box" outputs with limited interpretability. In this paper, we propose EndoFinder, an online polyp retrieval framework that leverages multi-view scene representations for explainable and scalable CRC diagnosis. First, we develop a Polyp-aware Image Encoder by combining contrastive learning and a reconstruction task, guided by polyp segmentation masks. This self-supervised approach captures robust features without relying on large-scale annotated data. Next, we treat each polyp as a three-dimensional "scene" and introduce a Scene Representation Transformer, which fuses multiple views of the polyp into a single latent representation. By discretizing this representation through a hashing layer, EndoFinder enables real-time retrieval from a compiled database of historical polyp cases, where diagnostic information serves as interpretable references for new queries. We evaluate EndoFinder on both public and newly collected polyp datasets for re-identification and pathology classification. Results show that EndoFinder outperforms existing methods in accuracy while providing transparent, retrieval-based insights for clinical decision-making. By contributing a novel dataset and a scalable, explainable framework, our work addresses key challenges in polyp diagnosis and offers a promising direction for more efficient AI-driven colonoscopy workflows. The source code is available at https://github.com/ku262/EndoFinder-Scene.
Endo-CLIP: Progressive Self-Supervised Pre-training on Raw Colonoscopy Records
May 14, 2025



Pre-training on image-text colonoscopy records offers substantial potential for improving endoscopic image analysis, but faces challenges including non-informative background images, complex medical terminology, and ambiguous multi-lesion descriptions. We introduce Endo-CLIP, a novel self-supervised framework that enhances Contrastive Language-Image Pre-training (CLIP) for this domain. Endo-CLIP's three-stage framework--cleansing, attunement, and unification--addresses these challenges by (1) removing background frames, (2) leveraging large language models to extract clinical attributes for fine-grained contrastive learning, and (3) employing patient-level cross-attention to resolve multi-polyp ambiguities. Extensive experiments demonstrate that Endo-CLIP significantly outperforms state-of-the-art pre-training methods in zero-shot and few-shot polyp detection and classification, paving the way for more accurate and clinically relevant endoscopic analysis.
Generating Editable Head Avatars with 3D Gaussian GANs
Dec 26, 2024



Generating animatable and editable 3D head avatars is essential for various applications in computer vision and graphics. Traditional 3D-aware generative adversarial networks (GANs), often using implicit fields like Neural Radiance Fields (NeRF), achieve photorealistic and view-consistent 3D head synthesis. However, these methods face limitations in deformation flexibility and editability, hindering the creation of lifelike and easily modifiable 3D heads. We propose a novel approach that enhances the editability and animation control of 3D head avatars by incorporating 3D Gaussian Splatting (3DGS) as an explicit 3D representation. This method enables easier illumination control and improved editability. Central to our approach is the Editable Gaussian Head (EG-Head) model, which combines a 3D Morphable Model (3DMM) with texture maps, allowing precise expression control and flexible texture editing for accurate animation while preserving identity. To capture complex non-facial geometries like hair, we use an auxiliary set of 3DGS and tri-plane features. Extensive experiments demonstrate that our approach delivers high-quality 3D-aware synthesis with state-of-the-art controllability. Our code and models are available at https://github.com/liguohao96/EGG3D.
Multi-modal Relation Distillation for Unified 3D Representation Learning
Jul 19, 2024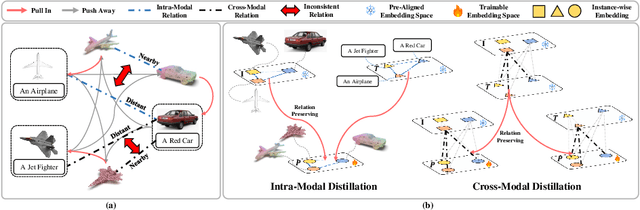

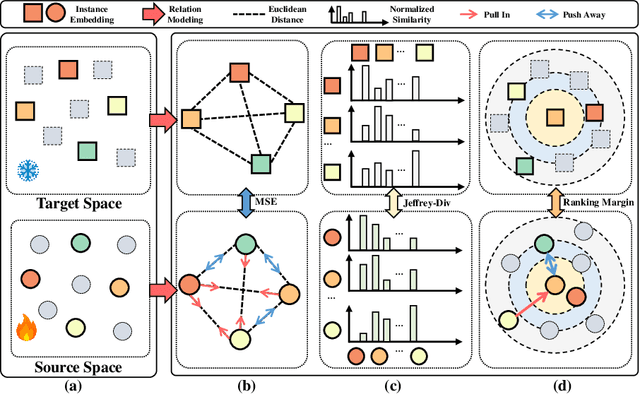

Recent advancements in multi-modal pre-training for 3D point clouds have demonstrated promising results by aligning heterogeneous features across 3D shapes and their corresponding 2D images and language descriptions. However, current straightforward solutions often overlook intricate structural relations among samples, potentially limiting the full capabilities of multi-modal learning. To address this issue, we introduce Multi-modal Relation Distillation (MRD), a tri-modal pre-training framework, which is designed to effectively distill reputable large Vision-Language Models (VLM) into 3D backbones. MRD aims to capture both intra-relations within each modality as well as cross-relations between different modalities and produce more discriminative 3D shape representations. Notably, MRD achieves significant improvements in downstream zero-shot classification tasks and cross-modality retrieval tasks, delivering new state-of-the-art performance.
EndoFinder: Online Image Retrieval for Explainable Colorectal Polyp Diagnosis
Jul 16, 2024Determining the necessity of resecting malignant polyps during colonoscopy screen is crucial for patient outcomes, yet challenging due to the time-consuming and costly nature of histopathology examination. While deep learning-based classification models have shown promise in achieving optical biopsy with endoscopic images, they often suffer from a lack of explainability. To overcome this limitation, we introduce EndoFinder, a content-based image retrieval framework to find the 'digital twin' polyp in the reference database given a newly detected polyp. The clinical semantics of the new polyp can be inferred referring to the matched ones. EndoFinder pioneers a polyp-aware image encoder that is pre-trained on a large polyp dataset in a self-supervised way, merging masked image modeling with contrastive learning. This results in a generic embedding space ready for different downstream clinical tasks based on image retrieval. We validate the framework on polyp re-identification and optical biopsy tasks, with extensive experiments demonstrating that EndoFinder not only achieves explainable diagnostics but also matches the performance of supervised classification models. EndoFinder's reliance on image retrieval has the potential to support diverse downstream decision-making tasks during real-time colonoscopy procedures.
Leveraging Predicate and Triplet Learning for Scene Graph Generation
Jun 04, 2024

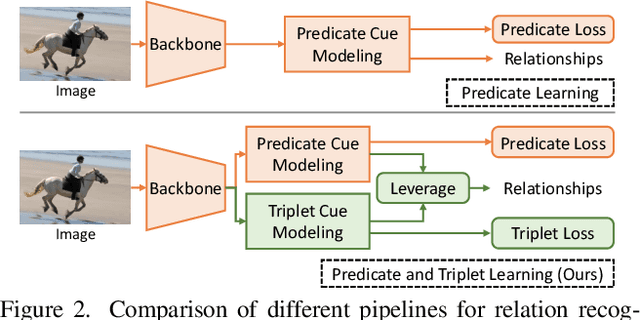

Scene Graph Generation (SGG) aims to identify entities and predict the relationship triplets \textit{\textless subject, predicate, object\textgreater } in visual scenes. Given the prevalence of large visual variations of subject-object pairs even in the same predicate, it can be quite challenging to model and refine predicate representations directly across such pairs, which is however a common strategy adopted by most existing SGG methods. We observe that visual variations within the identical triplet are relatively small and certain relation cues are shared in the same type of triplet, which can potentially facilitate the relation learning in SGG. Moreover, for the long-tail problem widely studied in SGG task, it is also crucial to deal with the limited types and quantity of triplets in tail predicates. Accordingly, in this paper, we propose a Dual-granularity Relation Modeling (DRM) network to leverage fine-grained triplet cues besides the coarse-grained predicate ones. DRM utilizes contexts and semantics of predicate and triplet with Dual-granularity Constraints, generating compact and balanced representations from two perspectives to facilitate relation recognition. Furthermore, a Dual-granularity Knowledge Transfer (DKT) strategy is introduced to transfer variation from head predicates/triplets to tail ones, aiming to enrich the pattern diversity of tail classes to alleviate the long-tail problem. Extensive experiments demonstrate the effectiveness of our method, which establishes new state-of-the-art performance on Visual Genome, Open Image, and GQA datasets. Our code is available at \url{https://github.com/jkli1998/DRM}
AED-PADA:Improving Generalizability of Adversarial Example Detection via Principal Adversarial Domain Adaptation
Apr 19, 2024Adversarial example detection, which can be conveniently applied in many scenarios, is important in the area of adversarial defense. Unfortunately, existing detection methods suffer from poor generalization performance, because their training process usually relies on the examples generated from a single known adversarial attack and there exists a large discrepancy between the training and unseen testing adversarial examples. To address this issue, we propose a novel method, named Adversarial Example Detection via Principal Adversarial Domain Adaptation (AED-PADA). Specifically, our approach identifies the Principal Adversarial Domains (PADs), i.e., a combination of features of the adversarial examples from different attacks, which possesses large coverage of the entire adversarial feature space. Then, we pioneer to exploit multi-source domain adaptation in adversarial example detection with PADs as source domains. Experiments demonstrate the superior generalization ability of our proposed AED-PADA. Note that this superiority is particularly achieved in challenging scenarios characterized by employing the minimal magnitude constraint for the perturbations.
Common Knowledge Learning for Generating Transferable Adversarial Examples
Jul 01, 2023This paper focuses on an important type of black-box attacks, i.e., transfer-based adversarial attacks, where the adversary generates adversarial examples by a substitute (source) model and utilize them to attack an unseen target model, without knowing its information. Existing methods tend to give unsatisfactory adversarial transferability when the source and target models are from different types of DNN architectures (e.g. ResNet-18 and Swin Transformer). In this paper, we observe that the above phenomenon is induced by the output inconsistency problem. To alleviate this problem while effectively utilizing the existing DNN models, we propose a common knowledge learning (CKL) framework to learn better network weights to generate adversarial examples with better transferability, under fixed network architectures. Specifically, to reduce the model-specific features and obtain better output distributions, we construct a multi-teacher framework, where the knowledge is distilled from different teacher architectures into one student network. By considering that the gradient of input is usually utilized to generated adversarial examples, we impose constraints on the gradients between the student and teacher models, to further alleviate the output inconsistency problem and enhance the adversarial transferability. Extensive experiments demonstrate that our proposed work can significantly improve the adversarial transferability.
Global Contrast Masked Autoencoders Are Powerful Pathological Representation Learners
May 21, 2022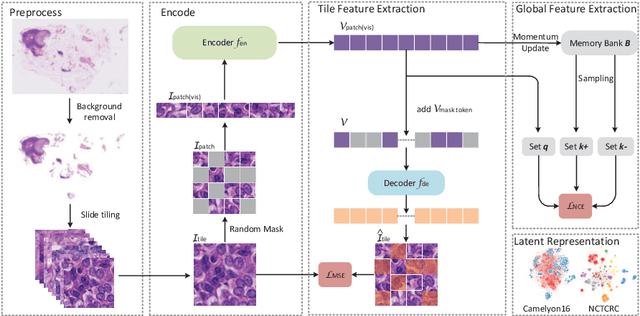
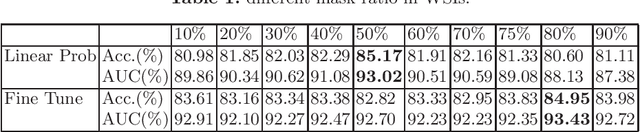

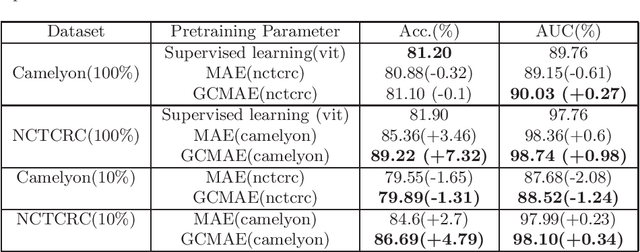
Based on digital whole slide scanning technique, artificial intelligence algorithms represented by deep learning have achieved remarkable results in the field of computational pathology. Compared with other medical images such as Computed Tomography (CT) or Magnetic Resonance Imaging (MRI), pathological images are more difficult to annotate, thus there is an extreme lack of data sets that can be used for supervised learning. In this study, a self-supervised learning (SSL) model, Global Contrast Masked Autoencoders (GCMAE), is proposed, which has the ability to represent both global and local domain-specific features of whole slide image (WSI), as well as excellent cross-data transfer ability. The Camelyon16 and NCTCRC datasets are used to evaluate the performance of our model. When dealing with transfer learning tasks with different data sets, the experimental results show that GCMAE has better linear classification accuracy than MAE, which can reach 81.10% and 89.22% respectively. Our method outperforms the previous state-of-the-art algorithm and even surpass supervised learning (improved by 3.86% on NCTCRC data sets). The source code of this paper is publicly available at https://github.com/StarUniversus/gcmae