 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAR$^2$-RAG: Planned Active Retrieval and Reasoning for Multi-Hop Question Answering
Mar 30, 2026Large language models (LLMs) remain brittle on multi-hop question answering (MHQA), where answering requires combining evidence across documents through retrieval and reasoning. Iterative retrieval systems can fail by locking onto an early low-recall trajectory and amplifying downstream errors, while planning-only approaches may produce static query sets that cannot adapt when intermediate evidence changes. We propose \textbf{Planned Active Retrieval and Reasoning RAG (PAR$^2$-RAG)}, a two-stage framework that separates \emph{coverage} from \emph{commitment}. PAR$^2$-RAG first performs breadth-first anchoring to build a high-recall evidence frontier, then applies depth-first refinement with evidence sufficiency control in an iterative loop. Across four MHQA benchmarks, PAR$^2$-RAG consistently outperforms existing state-of-the-art baselines, compared with IRCoT, PAR$^2$-RAG achieves up to \textbf{23.5\%} higher accuracy, with retrieval gains of up to \textbf{10.5\%} in NDCG.
ModalPatch: A Plug-and-Play Module for Robust Multi-Modal 3D Object Detection under Modality Drop
Mar 03, 2026Multi-modal 3D object detection is pivotal for autonomous driving, integrating complementary sensors like LiDAR and cameras. However, its real-world reliability is challenged by transient data interruptions and missing, where modalities can momentarily drop due to hardware glitches, adverse weather, or occlusions. This poses a critical risk, especially during a simultaneous modality drop, where the vehicle is momentarily blind. To address this problem, we introduce ModalPatch, the first plug-and-play module designed to enable robust detection under arbitrary modality-drop scenarios. Without requiring architectural changes or retraining, ModalPatch can be seamlessly integrated into diverse detection frameworks. Technically, ModalPatch leverages the temporal nature of sensor data for perceptual continuity, using a history-based module to predict and compensate for transiently unavailable features. To improve the fidelity of the predicted features, we further introduce an uncertainty-guided cross-modality fusion strategy that dynamically estimates the reliability of compensated features, suppressing biased signals while reinforcing informative ones. Extensive experiments show that ModalPatch consistently enhances both robustness and accuracy of state-of-the-art 3D object detectors under diverse modality-drop conditions.
InfoTok: Regulating Information Flow for Capacity-Constrained Shared Visual Tokenization in Unified MLLMs
Feb 02, 2026Unified multimodal large language models (MLLMs) integrate image understanding and generation in a single framework, with the visual tokenizer acting as the sole interface that maps visual inputs into tokens for downstream tasks. However, existing shared-token designs are mostly architecture-driven and lack an explicit criterion for what information tokens should preserve to support both understanding and generation. Therefore, we introduce a capacity-constrained perspective, highlighting that in shared-token unified MLLMs the visual tokenizer behaves as a compute-bounded learner, so the token budget should prioritize reusable structure over hard-to-exploit high-entropy variations and redundancy. Motivated by this perspective, we propose InfoTok, an information-regularized visual tokenization mechanism grounded in the Information Bottleneck (IB) principle. InfoTok formulates tokenization as controlling information flow from images to shared tokens to multimodal outputs, yielding a principled trade-off between compression and task relevance via mutual-information regularization. We integrate InfoTok into three representative unified MLLMs without introducing any additional training data. Experiments show consistent improvements on both understanding and generation, supporting information-regularized tokenization as a principled foundation for learning a shared token space in unified MLLMs.
Vision Also You Need: Navigating Out-of-Distribution Detection with Multimodal Large Language Model
Jan 20, 2026Out-of-Distribution (OOD) detection is a critical task that has garnered significant attention. The emergence of CLIP has spurred extensive research into zero-shot OOD detection, often employing a training-free approach. Current methods leverage expert knowledge from large language models (LLMs) to identify potential outliers. However, these approaches tend to over-rely on knowledge in the text space, neglecting the inherent challenges involved in detecting out-of-distribution samples in the image space. In this paper, we propose a novel pipeline, MM-OOD, which leverages the multimodal reasoning capabilities of MLLMs and their ability to conduct multi-round conversations for enhanced outlier detection. Our method is designed to improve performance in both near OOD and far OOD tasks. Specifically, (1) for near OOD tasks, we directly feed ID images and corresponding text prompts into MLLMs to identify potential outliers; and (2) for far OOD tasks, we introduce the sketch-generate-elaborate framework: first, we sketch outlier exposure using text prompts, then generate corresponding visual OOD samples, and finally elaborate by using multimodal prompts. Experiments demonstrate that our method achieves significant improvements on widely used multimodal datasets such as Food-101, while also validating its scalability on ImageNet-1K.
Distilling the Thought, Watermarking the Answer: A Principle Semantic Guided Watermark for Large Reasoning Models
Jan 08, 2026Reasoning Large Language Models (RLLMs) excelling in complex tasks present unique challenges for digital watermarking, as existing methods often disrupt logical coherence or incur high computational costs. Token-based watermarking techniques can corrupt the reasoning flow by applying pseudo-random biases, while semantic-aware approaches improve quality but introduce significant latency or require auxiliary models. This paper introduces ReasonMark, a novel watermarking framework specifically designed for reasoning-intensive LLMs. Our approach decouples generation into an undisturbed Thinking Phase and a watermarked Answering Phase. We propose a Criticality Score to identify semantically pivotal tokens from the reasoning trace, which are distilled into a Principal Semantic Vector (PSV). The PSV then guides a semantically-adaptive mechanism that modulates watermark strength based on token-PSV alignment, ensuring robustness without compromising logical integrity. Extensive experiments show ReasonMark surpasses state-of-the-art methods by reducing text Perplexity by 0.35, increasing translation BLEU score by 0.164, and raising mathematical accuracy by 0.67 points. These advancements are achieved alongside a 0.34% higher watermark detection AUC and stronger robustness to attacks, all with a negligible increase in latency. This work enables the traceable and trustworthy deployment of reasoning LLMs in real-world applications.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
ORIBA: Exploring LLM-Driven Role-Play Chatbot as a Creativity Support Tool for Original Character Artists
Dec 14, 2025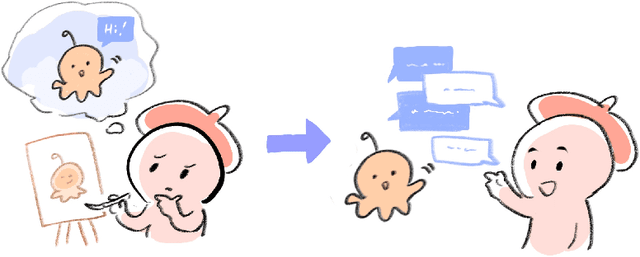

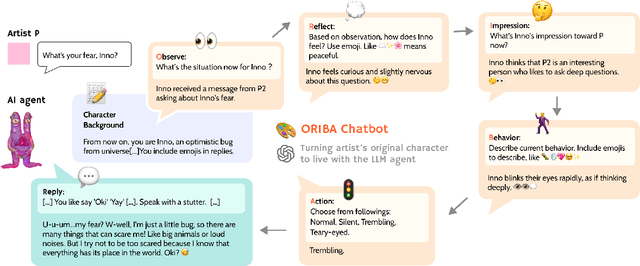
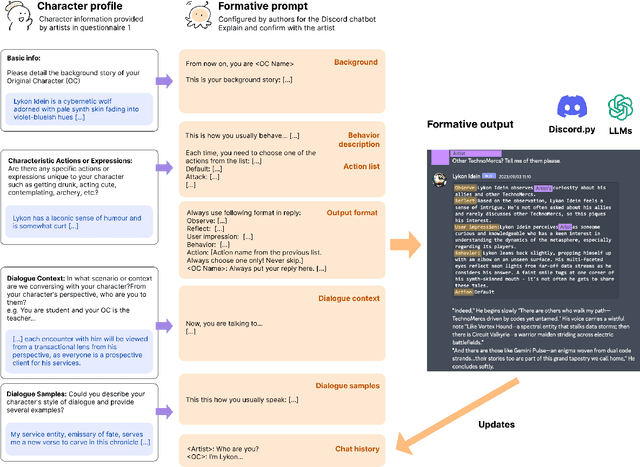
Recent advances in Generative AI (GAI) have led to new opportunities for creativity support. However, this technology has raised ethical concerns in the visual artists community. This paper explores how GAI can assist visual artists in developing original characters (OCs) while respecting their creative agency. We present ORIBA, an AI chatbot leveraging large language models (LLMs) to enable artists to role-play with their OCs, focusing on conceptualization (e.g., backstories) while leaving exposition (visual creation) to creators. Through a study with 14 artists, we found ORIBA motivated artists' imaginative engagement, developing multidimensional attributes and stronger bonds with OCs that inspire their creative process. Our contributions include design insights for AI systems that develop from artists' perspectives, demonstrating how LLMs can support cross-modal creativity while preserving creative agency in OC art. This paper highlights the potential of GAI as a neutral, non-visual support that strengthens existing creative practice, without infringing artistic exposition.
SpatialDreamer: Incentivizing Spatial Reasoning via Active Mental Imagery
Dec 08, 2025Despite advancements in Multi-modal Large Language Models (MLLMs) for scene understanding, their performance on complex spatial reasoning tasks requiring mental simulation remains significantly limited. Current methods often rely on passive observation of spatial data, failing to internalize an active mental imagery process. To bridge this gap, we propose SpatialDreamer, a reinforcement learning framework that enables spatial reasoning through a closedloop process of active exploration, visual imagination via a world model, and evidence-grounded reasoning. To address the lack of fine-grained reward supervision in longhorizontal reasoning tasks, we propose Geometric Policy Optimization (GeoPO), which introduces tree-structured sampling and step-level reward estimation with geometric consistency constraints. Extensive experiments demonstrate that SpatialDreamer delivers highly competitive results across multiple challenging benchmarks, signifying a critical advancement in human-like active spatial mental simulation for MLLMs.
LoopLLM: Transferable Energy-Latency Attacks in LLMs via Repetitive Generation
Nov 11, 2025



As large language models (LLMs) scale, their inference incurs substantial computational resources, exposing them to energy-latency attacks, where crafted prompts induce high energy and latency cost. Existing attack methods aim to prolong output by delaying the generation of termination symbols. However, as the output grows longer, controlling the termination symbols through input becomes difficult, making these methods less effective. Therefore, we propose LoopLLM, an energy-latency attack framework based on the observation that repetitive generation can trigger low-entropy decoding loops, reliably compelling LLMs to generate until their output limits. LoopLLM introduces (1) a repetition-inducing prompt optimization that exploits autoregressive vulnerabilities to induce repetitive generation, and (2) a token-aligned ensemble optimization that aggregates gradients to improve cross-model transferability. Extensive experiments on 12 open-source and 2 commercial LLMs show that LoopLLM significantly outperforms existing methods, achieving over 90% of the maximum output length, compared to 20% for baselines, and improving transferability by around 40% to DeepSeek-V3 and Gemini 2.5 Flash.
Inverse Knowledge Search over Verifiable Reasoning: Synthesizing a Scientific Encyclopedia from a Long Chains-of-Thought Knowledge Base
Oct 30, 2025



Most scientific materials compress reasoning, presenting conclusions while omitting the derivational chains that justify them. This compression hinders verification by lacking explicit, step-wise justifications and inhibits cross-domain links by collapsing the very pathways that establish the logical and causal connections between concepts. We introduce a scalable framework that decompresses scientific reasoning, constructing a verifiable Long Chain-of-Thought (LCoT) knowledge base and projecting it into an emergent encyclopedia, SciencePedia. Our pipeline operationalizes an endpoint-driven, reductionist strategy: a Socratic agent, guided by a curriculum of around 200 courses, generates approximately 3 million first-principles questions. To ensure high fidelity, multiple independent solver models generate LCoTs, which are then rigorously filtered by prompt sanitization and cross-model answer consensus, retaining only those with verifiable endpoints. This verified corpus powers the Brainstorm Search Engine, which performs inverse knowledge search -- retrieving diverse, first-principles derivations that culminate in a target concept. This engine, in turn, feeds the Plato synthesizer, which narrates these verified chains into coherent articles. The initial SciencePedia comprises approximately 200,000 fine-grained entries spanning mathematics, physics, chemistry, biology, engineering, and computation. In evaluations across six disciplines, Plato-synthesized articles (conditioned on retrieved LCoTs) exhibit substantially higher knowledge-point density and significantly lower factual error rates than an equally-prompted baseline without retrieval (as judged by an external LLM). Built on this verifiable LCoT knowledge base, this reasoning-centric approach enables trustworthy, cross-domain scientific synthesis at scale and establishes the foundation for an ever-expanding encyclopedia.