 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D Gaussian Splatting SLAM
Mar 20, 2025Simultaneously localizing camera poses and constructing Gaussian radiance fields in dynamic scenes establish a crucial bridge between 2D images and the 4D real world. Instead of removing dynamic objects as distractors and reconstructing only static environments, this paper proposes an efficient architecture that incrementally tracks camera poses and establishes the 4D Gaussian radiance fields in unknown scenarios by using a sequence of RGB-D images. First, by generating motion masks, we obtain static and dynamic priors for each pixel. To eliminate the influence of static scenes and improve the efficiency on learning the motion of dynamic objects, we classify the Gaussian primitives into static and dynamic Gaussian sets, while the sparse control points along with an MLP is utilized to model the transformation fields of the dynamic Gaussians. To more accurately learn the motion of dynamic Gaussians, a novel 2D optical flow map reconstruction algorithm is designed to render optical flows of dynamic objects between neighbor images, which are further used to supervise the 4D Gaussian radiance fields along with traditional photometric and geometric constraints. In experiments, qualitative and quantitative evaluation results show that the proposed method achieves robust tracking and high-quality view synthesis performance in real-world environments.
Distilling High Diagnostic Value Patches for Whole Slide Image Classification Using Attention Mechanism
Jul 29, 2024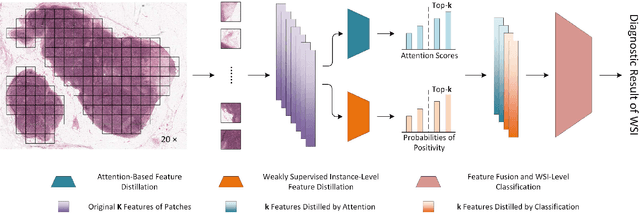
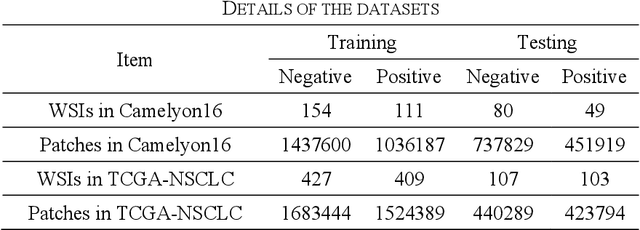
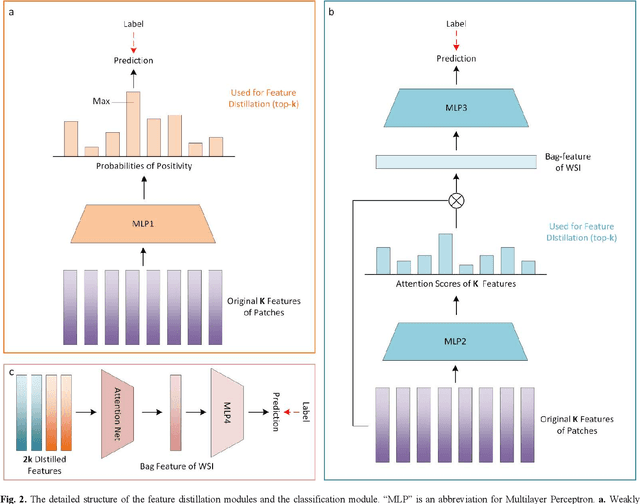
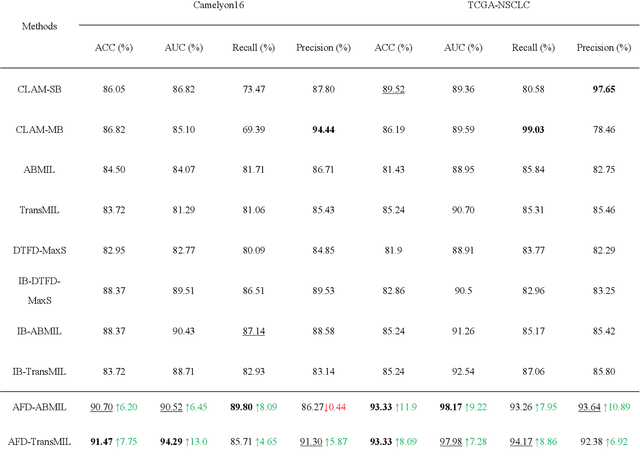
Multiple Instance Learning (MIL) has garnered widespread attention in the field of Whole Slide Image (WSI) classification as it replaces pixel-level manual annotation with diagnostic reports as labels, significantly reducing labor costs. Recent research has shown that bag-level MIL methods often yield better results because they can consider all patches of the WSI as a whole. However, a drawback of such methods is the incorporation of more redundant patches, leading to interference. To extract patches with high diagnostic value while excluding interfering patches to address this issue, we developed an attention-based feature distillation multi-instance learning (AFD-MIL) approach. This approach proposed the exclusion of redundant patches as a preprocessing operation in weakly supervised learning, directly mitigating interference from extensive noise. It also pioneers the use of attention mechanisms to distill features with high diagnostic value, as opposed to the traditional practice of indiscriminately and forcibly integrating all patches. Additionally, we introduced global loss optimization to finely control the feature distillation module. AFD-MIL is orthogonal to many existing MIL methods, leading to consistent performance improvements. This approach has surpassed the current state-of-the-art method, achieving 91.47% ACC (accuracy) and 94.29% AUC (area under the curve) on the Camelyon16 (Camelyon Challenge 2016, breast cancer), while 93.33% ACC and 98.17% AUC on the TCGA-NSCLC (The Cancer Genome Atlas Program: non-small cell lung cancer). Different feature distillation methods were used for the two datasets, tailored to the specific diseases, thereby improving performance and interpretability.
Establishing Truly Causal Relationship Between Whole Slide Image Predictions and Diagnostic Evidence Subregions in Deep Learning
Jul 24, 2024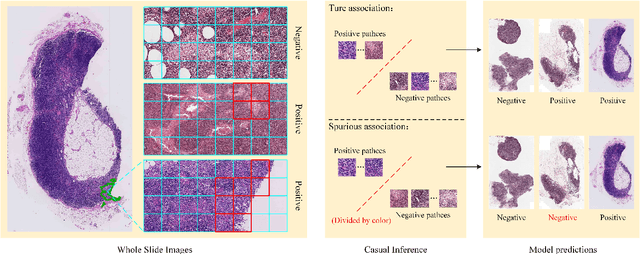

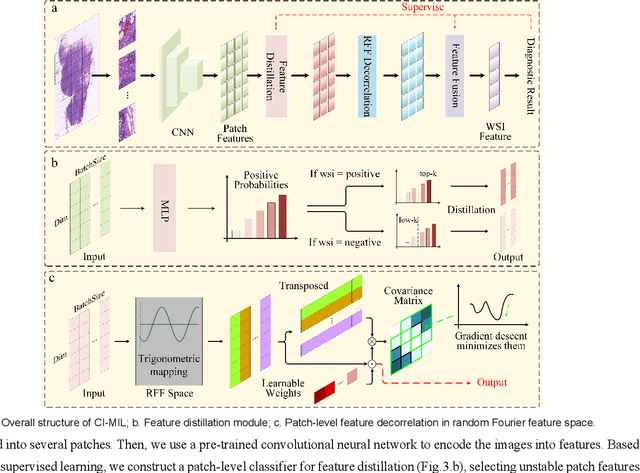
In the field of deep learning-driven Whole Slide Image (WSI) classification, Multiple Instance Learning (MIL) has gained significant attention due to its ability to be trained using only slide-level diagnostic labels. Previous MIL researches have primarily focused on enhancing feature aggregators for globally analyzing WSIs, but overlook a causal relationship in diagnosis: model's prediction should ideally stem solely from regions of the image that contain diagnostic evidence (such as tumor cells), which usually occupy relatively small areas. To address this limitation and establish the truly causal relationship between model predictions and diagnostic evidence regions, we propose Causal Inference Multiple Instance Learning (CI-MIL). CI-MIL integrates feature distillation with a novel patch decorrelation mechanism, employing a two-stage causal inference approach to distill and process patches with high diagnostic value. Initially, CI-MIL leverages feature distillation to identify patches likely containing tumor cells and extracts their corresponding feature representations. These features are then mapped to random Fourier feature space, where a learnable weighting scheme is employed to minimize inter-feature correlations, effectively reducing redundancy from homogenous patches and mitigating data bias. These processes strengthen the causal relationship between model predictions and diagnostically relevant regions, making the prediction more direct and reliable. Experimental results demonstrate that CI-MIL outperforms state-of-the-art methods. Additionally, CI-MIL exhibits superior interpretability, as its selected regions demonstrate high consistency with ground truth annotations, promising more reliable diagnostic assistance for pathologists.
A Unified NOMA Framework in Beam-Hopping Satellite Communication Systems
Jan 17, 2024



This paper investigates the application of a unified non-orthogonal multiple access framework in beam hopping (U-NOMA-BH) based satellite communication systems. More specifically, the proposed U-NOMA-BH framework can be applied to code-domain NOMA based BH (CD-NOMA-BH) and power-domain NOMA based BH (PD-NOMA-BH) systems. To satisfy dynamic-uneven traffic demands, we formulate the optimization problem to minimize the square of discrete difference by jointly optimizing power allocation, carrier assignment and beam scheduling. The non-convexity of the objective function and the constraint condition is solved through Dinkelbach's transform and variable relaxation. As a further development, the closed-from and asymptotic expressions of outage probability are derived for CD/PD-NOMA-BH systems. Based on approximated results, the diversity orders of a pair of users are obtained in detail. In addition, the system throughput of U-NOMA-BH is discussed in delay-limited transmission mode. Numerical results verify that: i) The gap between traffic requests of CD/PD-NOMA-BH systems appears to be more closely compared with orthogonal multiple access based BH (OMA-BH); ii) The CD-NOMA-BH system is capable of providing the enhanced traffic request and capacity provision; and iii) The outage behaviors of CD/PD-NOMA-BH are better than that of OMA-BH.
UniVision: A Unified Framework for Vision-Centric 3D Perception
Jan 13, 2024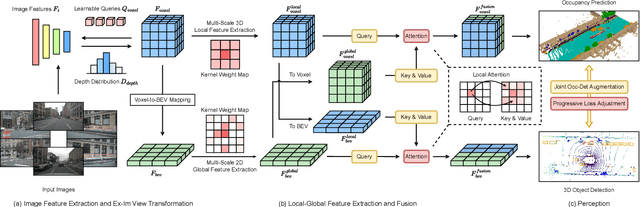
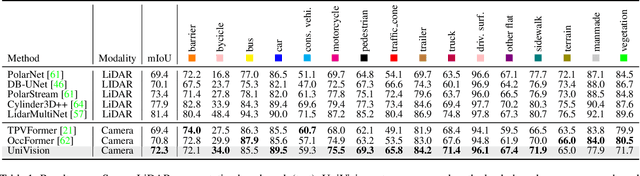
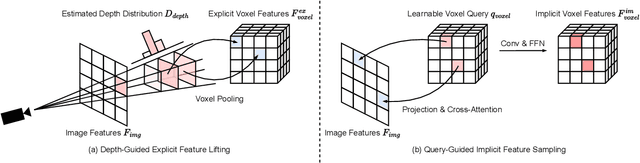
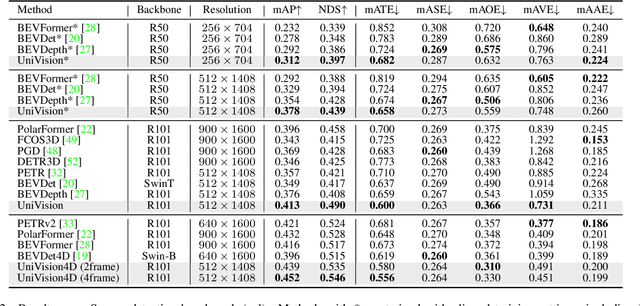
The past few years have witnessed the rapid development of vision-centric 3D perception in autonomous driving. Although the 3D perception models share many structural and conceptual similarities, there still exist gaps in their feature representations, data formats, and objectives, posing challenges for unified and efficient 3D perception framework design. In this paper, we present UniVision, a simple and efficient framework that unifies two major tasks in vision-centric 3D perception, \ie, occupancy prediction and object detection. Specifically, we propose an explicit-implicit view transform module for complementary 2D-3D feature transformation. We propose a local-global feature extraction and fusion module for efficient and adaptive voxel and BEV feature extraction, enhancement, and interaction. Further, we propose a joint occupancy-detection data augmentation strategy and a progressive loss weight adjustment strategy which enables the efficiency and stability of the multi-task framework training. We conduct extensive experiments for different perception tasks on four public benchmarks, including nuScenes LiDAR segmentation, nuScenes detection, OpenOccupancy, and Occ3D. UniVision achieves state-of-the-art results with +1.5 mIoU, +1.8 NDS, +1.5 mIoU, and +1.8 mIoU gains on each benchmark, respectively. We believe that the UniVision framework can serve as a high-performance baseline for the unified vision-centric 3D perception task. The code will be available at \url{https://github.com/Cc-Hy/UniVision}.
MSeg3D: Multi-modal 3D Semantic Segmentation for Autonomous Driving
Mar 15, 2023


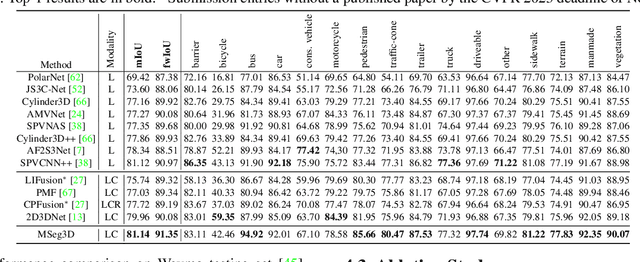
LiDAR and camera are two modalities available for 3D semantic segmentation in autonomous driving. The popular LiDAR-only methods severely suffer from inferior segmentation on small and distant objects due to insufficient laser points, while the robust multi-modal solution is under-explored, where we investigate three crucial inherent difficulties: modality heterogeneity, limited sensor field of view intersection, and multi-modal data augmentation. We propose a multi-modal 3D semantic segmentation model (MSeg3D) with joint intra-modal feature extraction and inter-modal feature fusion to mitigate the modality heterogeneity. The multi-modal fusion in MSeg3D consists of geometry-based feature fusion GF-Phase, cross-modal feature completion, and semantic-based feature fusion SF-Phase on all visible points. The multi-modal data augmentation is reinvigorated by applying asymmetric transformations on LiDAR point cloud and multi-camera images individually, which benefits the model training with diversified augmentation transformations. MSeg3D achieves state-of-the-art results on nuScenes, Waymo, and SemanticKITTI datasets. Under the malfunctioning multi-camera input and the multi-frame point clouds input, MSeg3D still shows robustness and improves the LiDAR-only baseline. Our code is publicly available at \url{https://github.com/jialeli1/lidarseg3d}.
Cross-Modality Knowledge Distillation Network for Monocular 3D Object Detection
Nov 14, 2022Leveraging LiDAR-based detectors or real LiDAR point data to guide monocular 3D detection has brought significant improvement, e.g., Pseudo-LiDAR methods. However, the existing methods usually apply non-end-to-end training strategies and insufficiently leverage the LiDAR information, where the rich potential of the LiDAR data has not been well exploited. In this paper, we propose the Cross-Modality Knowledge Distillation (CMKD) network for monocular 3D detection to efficiently and directly transfer the knowledge from LiDAR modality to image modality on both features and responses. Moreover, we further extend CMKD as a semi-supervised training framework by distilling knowledge from large-scale unlabeled data and significantly boost the performance. Until submission, CMKD ranks $1^{st}$ among the monocular 3D detectors with publications on both KITTI $test$ set and Waymo $val$ set with significant performance gains compared to previous state-of-the-art methods.
Pseudo-Stereo for Monocular 3D Object Detection in Autonomous Driving
Mar 04, 2022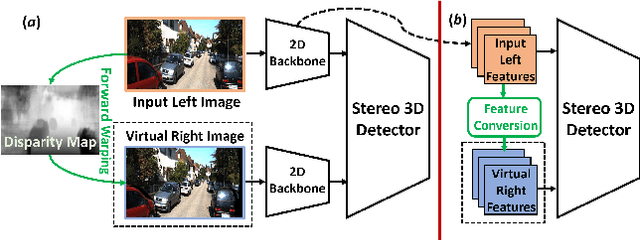
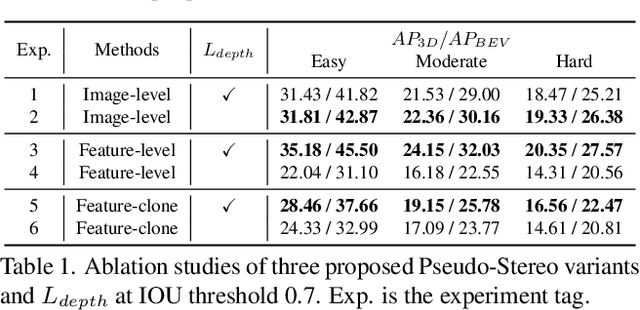
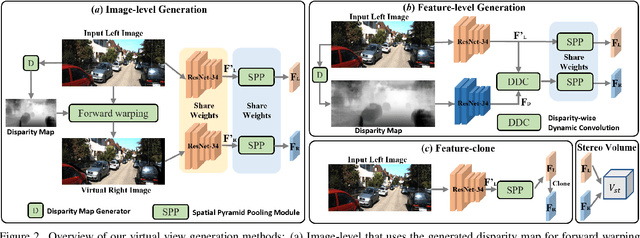
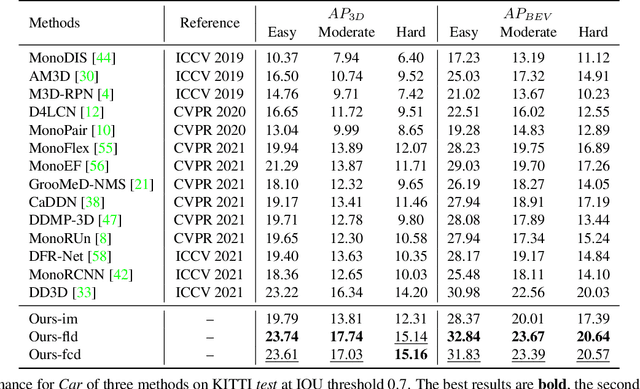
Pseudo-LiDAR 3D detectors have made remarkable progress in monocular 3D detection by enhancing the capability of perceiving depth with depth estimation networks, and using LiDAR-based 3D detection architectures. The advanced stereo 3D detectors can also accurately localize 3D objects. The gap in image-to-image generation for stereo views is much smaller than that in image-to-LiDAR generation. Motivated by this, we propose a Pseudo-Stereo 3D detection framework with three novel virtual view generation methods, including image-level generation, feature-level generation, and feature-clone, for detecting 3D objects from a single image. Our analysis of depth-aware learning shows that the depth loss is effective in only feature-level virtual view generation and the estimated depth map is effective in both image-level and feature-level in our framework. We propose a disparity-wise dynamic convolution with dynamic kernels sampled from the disparity feature map to filter the features adaptively from a single image for generating virtual image features, which eases the feature degradation caused by the depth estimation errors. Till submission (November 18, 2021), our Pseudo-Stereo 3D detection framework ranks 1st on car, pedestrian, and cyclist among the monocular 3D detectors with publications on the KITTI-3D benchmark. The code is released at https://github.com/revisitq/Pseudo-Stereo-3D.
Perlin Noise Improve Adversarial Robustness
Dec 26, 2021

Adversarial examples are some special input that can perturb the output of a deep neural network, in order to make produce intentional errors in the learning algorithms in the production environment. Most of the present methods for generating adversarial examples require gradient information. Even universal perturbations that are not relevant to the generative model rely to some extent on gradient information. Procedural noise adversarial examples is a new way of adversarial example generation, which uses computer graphics noise to generate universal adversarial perturbations quickly while not relying on gradient information. Combined with the defensive idea of adversarial training, we use Perlin noise to train the neural network to obtain a model that can defend against procedural noise adversarial examples. In combination with the use of model fine-tuning methods based on pre-trained models, we obtain faster training as well as higher accuracy. Our study shows that procedural noise adversarial examples are defensible, but why procedural noise can generate adversarial examples and how to defend against other kinds of procedural noise adversarial examples that may emerge in the future remain to be investigated.
From Voxel to Point: IoU-guided 3D Object Detection for Point Cloud with Voxel-to-Point Decoder
Aug 08, 2021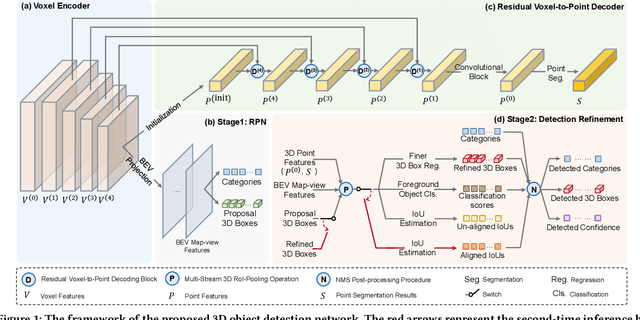
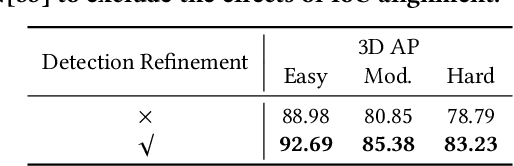
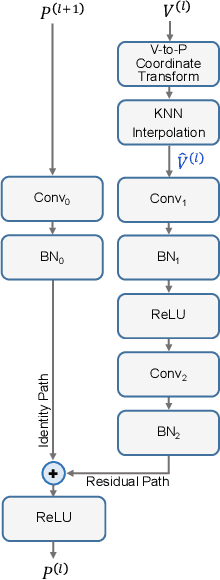
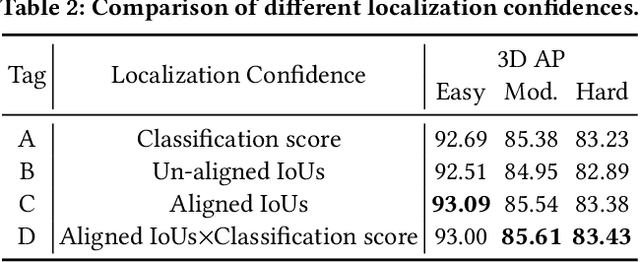
In this paper, we present an Intersection-over-Union (IoU) guided two-stage 3D object detector with a voxel-to-point decoder. To preserve the necessary information from all raw points and maintain the high box recall in voxel based Region Proposal Network (RPN), we propose a residual voxel-to-point decoder to extract the point features in addition to the map-view features from the voxel based RPN. We use a 3D Region of Interest (RoI) alignment to crop and align the features with the proposal boxes for accurately perceiving the object position. The RoI-Aligned features are finally aggregated with the corner geometry embeddings that can provide the potentially missing corner information in the box refinement stage. We propose a simple and efficient method to align the estimated IoUs to the refined proposal boxes as a more relevant localization confidence. The comprehensive experiments on KITTI and Waymo Open Dataset demonstrate that our method achieves significant improvements with novel architectures against the existing methods. The code is available on Github URL\footnote{\url{https://github.com/jialeli1/From-Voxel-to-Point}}.