 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Day and Night: Unsupervised Cross-Domain Re-Identification with Synergistic Prompt and Prototype Learning
Jun 10, 2026Cross-domain day-night re-identification (ReID) is fundamentally challenged by the substantial visual appearance discrepancies between daytime and nighttime scenes. Existing fully supervised methods rely heavily on labor-intensive annotations, which are costly and exhibit limited generalization across domains. In this work, we investigate unsupervised day-night ReID and propose a novel framework that synergistically combines prompt learning and prototype-based representation learning to associate identities across domains without requiring manual labels. Our approach follows a progressive two-stage training strategy. In the first stage, we exploit the vision-language model to generate instance-specific textual prompts in an annotation-free manner. We employ an instance-level alignment mechanism to embed visual features and textual prompts into a unified semantic space, aligning unlabeled day/night images with learnable prompts via instance-aware dynamic-bias adaptation. In the second stage, we construct domain-specific prototype memory banks and introduce two complementary modules: i) an intra-domain identity association module to enhance feature discriminability within each domain, and ii) a cross-domain prototype matching module to reliably identify positive and negative prototype pairs, thereby establishing robust identity correspondences across day and night. Extensive experiments on public benchmarks validate the effectiveness of our method. Under the unsupervised setting, our framework attains Rank-1 accuracy comparable to state-of-the-art fully supervised methods.
FreeArtGS: Articulated Gaussian Splatting Under Free-moving Scenario
Mar 23, 2026The increasing demand for augmented reality and robotics is driving the need for articulated object reconstruction with high scalability. However, existing settings for reconstructing from discrete articulation states or casual monocular videos require non-trivial axis alignment or suffer from insufficient coverage, limiting their applicability. In this paper, we introduce FreeArtGS, a novel method for reconstructing articulated objects under free-moving scenario, a new setting with a simple setup and high scalability. FreeArtGS combines free-moving part segmentation with joint estimation and end-to-end optimization, taking only a monocular RGB-D video as input. By optimizing with the priors from off-the-shelf point-tracking and feature models, the free-moving part segmentation module identifies rigid parts from relative motion under unconstrained capture. The joint estimation module calibrates the unified object-to-camera poses and recovers joint type and axis robustly from part segmentation. Finally, 3DGS-based end-to-end optimization is implemented to jointly reconstruct visual textures, geometry, and joint angles of the articulated object. We conduct experiments on two benchmarks and real-world free-moving articulated objects. Experimental results demonstrate that FreeArtGS consistently excels in reconstructing free-moving articulated objects and remains highly competitive in previous reconstruction settings, proving itself a practical and effective solution for realistic asset generation. The project page is available at: https://freeartgs.github.io/
TwinAligner: Visual-Dynamic Alignment Empowers Physics-aware Real2Sim2Real for Robotic Manipulation
Dec 22, 2025The robotics field is evolving towards data-driven, end-to-end learning, inspired by multimodal large models. However, reliance on expensive real-world data limits progress. Simulators offer cost-effective alternatives, but the gap between simulation and reality challenges effective policy transfer. This paper introduces TwinAligner, a novel Real2Sim2Real system that addresses both visual and dynamic gaps. The visual alignment module achieves pixel-level alignment through SDF reconstruction and editable 3DGS rendering, while the dynamic alignment module ensures dynamic consistency by identifying rigid physics from robot-object interaction. TwinAligner improves robot learning by providing scalable data collection and establishing a trustworthy iterative cycle, accelerating algorithm development. Quantitative evaluations highlight TwinAligner's strong capabilities in visual and dynamic real-to-sim alignment. This system enables policies trained in simulation to achieve strong zero-shot generalization to the real world. The high consistency between real-world and simulated policy performance underscores TwinAligner's potential to advance scalable robot learning. Code and data will be released on https://twin-aligner.github.io
IGAF: Incremental Guided Attention Fusion for Depth Super-Resolution
Jan 03, 2025Accurate depth estimation is crucial for many fields, including robotics, navigation, and medical imaging. However, conventional depth sensors often produce low-resolution (LR) depth maps, making detailed scene perception challenging. To address this, enhancing LR depth maps to high-resolution (HR) ones has become essential, guided by HR-structured inputs like RGB or grayscale images. We propose a novel sensor fusion methodology for guided depth super-resolution (GDSR), a technique that combines LR depth maps with HR images to estimate detailed HR depth maps. Our key contribution is the Incremental guided attention fusion (IGAF) module, which effectively learns to fuse features from RGB images and LR depth maps, producing accurate HR depth maps. Using IGAF, we build a robust super-resolution model and evaluate it on multiple benchmark datasets. Our model achieves state-of-the-art results compared to all baseline models on the NYU v2 dataset for $\times 4$, $\times 8$, and $\times 16$ upsampling. It also outperforms all baselines in a zero-shot setting on the Middlebury, Lu, and RGB-D-D datasets. Code, environments, and models are available on GitHub.
Learning Semi-Supervised Medical Image Segmentation from Spatial Registration
Sep 16, 2024



Semi-supervised medical image segmentation has shown promise in training models with limited labeled data and abundant unlabeled data. However, state-of-the-art methods ignore a potentially valuable source of unsupervised semantic information -- spatial registration transforms between image volumes. To address this, we propose CCT-R, a contrastive cross-teaching framework incorporating registration information. To leverage the semantic information available in registrations between volume pairs, CCT-R incorporates two proposed modules: Registration Supervision Loss (RSL) and Registration-Enhanced Positive Sampling (REPS). The RSL leverages segmentation knowledge derived from transforms between labeled and unlabeled volume pairs, providing an additional source of pseudo-labels. REPS enhances contrastive learning by identifying anatomically-corresponding positives across volumes using registration transforms. Experimental results on two challenging medical segmentation benchmarks demonstrate the effectiveness and superiority of CCT-R across various semi-supervised settings, with as few as one labeled case. Our code is available at https://github.com/kathyliu579/ContrastiveCross-teachingWithRegistration.
GLFNET: Global-Local (frequency) Filter Networks for efficient medical image segmentation
Mar 01, 2024



We propose a novel transformer-style architecture called Global-Local Filter Network (GLFNet) for medical image segmentation and demonstrate its state-of-the-art performance. We replace the self-attention mechanism with a combination of global-local filter blocks to optimize model efficiency. The global filters extract features from the whole feature map whereas the local filters are being adaptively created as 4x4 patches of the same feature map and add restricted scale information. In particular, the feature extraction takes place in the frequency domain rather than the commonly used spatial (image) domain to facilitate faster computations. The fusion of information from both spatial and frequency spaces creates an efficient model with regards to complexity, required data and performance. We test GLFNet on three benchmark datasets achieving state-of-the-art performance on all of them while being almost twice as efficient in terms of GFLOP operations.
UniVision: A Unified Framework for Vision-Centric 3D Perception
Jan 13, 2024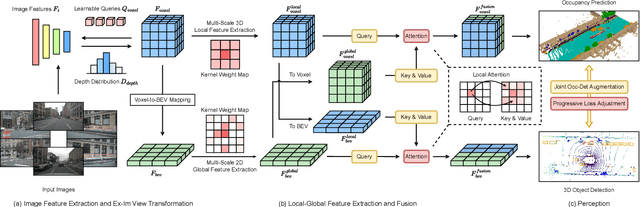
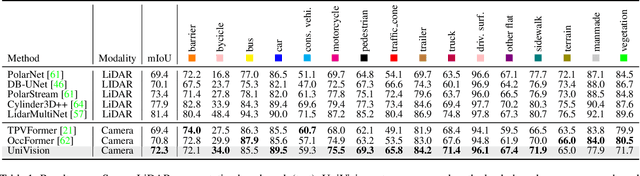
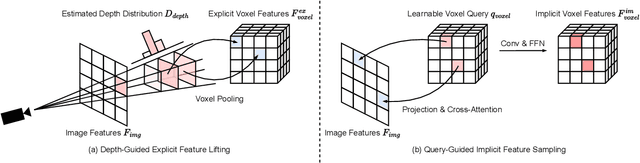
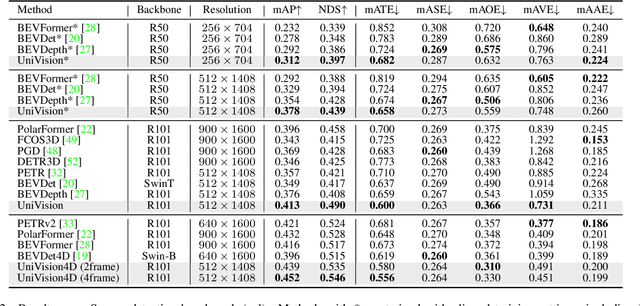
The past few years have witnessed the rapid development of vision-centric 3D perception in autonomous driving. Although the 3D perception models share many structural and conceptual similarities, there still exist gaps in their feature representations, data formats, and objectives, posing challenges for unified and efficient 3D perception framework design. In this paper, we present UniVision, a simple and efficient framework that unifies two major tasks in vision-centric 3D perception, \ie, occupancy prediction and object detection. Specifically, we propose an explicit-implicit view transform module for complementary 2D-3D feature transformation. We propose a local-global feature extraction and fusion module for efficient and adaptive voxel and BEV feature extraction, enhancement, and interaction. Further, we propose a joint occupancy-detection data augmentation strategy and a progressive loss weight adjustment strategy which enables the efficiency and stability of the multi-task framework training. We conduct extensive experiments for different perception tasks on four public benchmarks, including nuScenes LiDAR segmentation, nuScenes detection, OpenOccupancy, and Occ3D. UniVision achieves state-of-the-art results with +1.5 mIoU, +1.8 NDS, +1.5 mIoU, and +1.8 mIoU gains on each benchmark, respectively. We believe that the UniVision framework can serve as a high-performance baseline for the unified vision-centric 3D perception task. The code will be available at \url{https://github.com/Cc-Hy/UniVision}.
Feature Shrinkage Pyramid for Camouflaged Object Detection with Transformers
Mar 26, 2023



Vision transformers have recently shown strong global context modeling capabilities in camouflaged object detection. However, they suffer from two major limitations: less effective locality modeling and insufficient feature aggregation in decoders, which are not conducive to camouflaged object detection that explores subtle cues from indistinguishable backgrounds. To address these issues, in this paper, we propose a novel transformer-based Feature Shrinkage Pyramid Network (FSPNet), which aims to hierarchically decode locality-enhanced neighboring transformer features through progressive shrinking for camouflaged object detection. Specifically, we propose a nonlocal token enhancement module (NL-TEM) that employs the non-local mechanism to interact neighboring tokens and explore graph-based high-order relations within tokens to enhance local representations of transformers. Moreover, we design a feature shrinkage decoder (FSD) with adjacent interaction modules (AIM), which progressively aggregates adjacent transformer features through a layer-bylayer shrinkage pyramid to accumulate imperceptible but effective cues as much as possible for object information decoding. Extensive quantitative and qualitative experiments demonstrate that the proposed model significantly outperforms the existing 24 competitors on three challenging COD benchmark datasets under six widely-used evaluation metrics. Our code is publicly available at https://github.com/ZhouHuang23/FSPNet.
MSeg3D: Multi-modal 3D Semantic Segmentation for Autonomous Driving
Mar 15, 2023


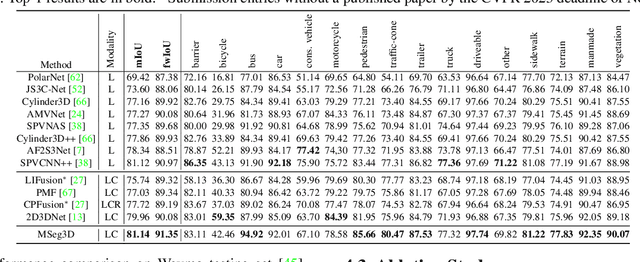
LiDAR and camera are two modalities available for 3D semantic segmentation in autonomous driving. The popular LiDAR-only methods severely suffer from inferior segmentation on small and distant objects due to insufficient laser points, while the robust multi-modal solution is under-explored, where we investigate three crucial inherent difficulties: modality heterogeneity, limited sensor field of view intersection, and multi-modal data augmentation. We propose a multi-modal 3D semantic segmentation model (MSeg3D) with joint intra-modal feature extraction and inter-modal feature fusion to mitigate the modality heterogeneity. The multi-modal fusion in MSeg3D consists of geometry-based feature fusion GF-Phase, cross-modal feature completion, and semantic-based feature fusion SF-Phase on all visible points. The multi-modal data augmentation is reinvigorated by applying asymmetric transformations on LiDAR point cloud and multi-camera images individually, which benefits the model training with diversified augmentation transformations. MSeg3D achieves state-of-the-art results on nuScenes, Waymo, and SemanticKITTI datasets. Under the malfunctioning multi-camera input and the multi-frame point clouds input, MSeg3D still shows robustness and improves the LiDAR-only baseline. Our code is publicly available at \url{https://github.com/jialeli1/lidarseg3d}.
Laplacian ICP for Progressive Registration of 3D Human Head Meshes
Feb 04, 2023
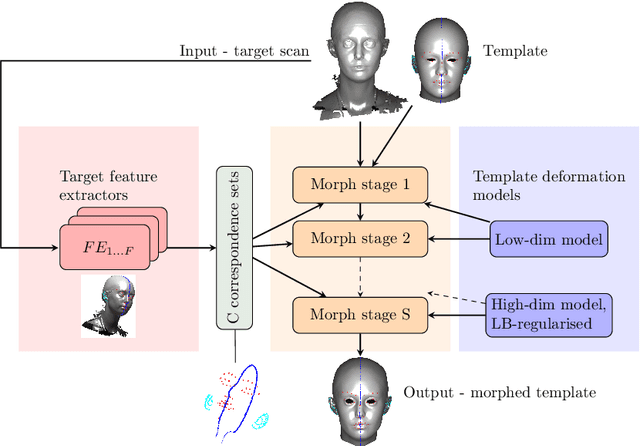

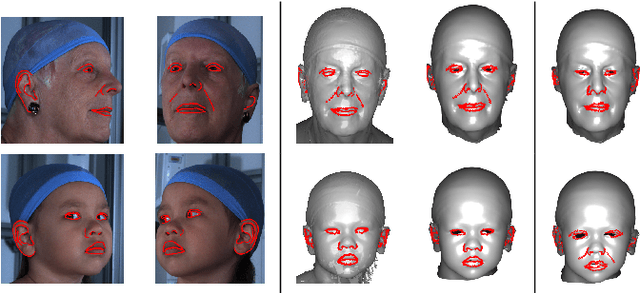
We present a progressive 3D registration framework that is a highly-efficient variant of classical non-rigid Iterative Closest Points (N-ICP). Since it uses the Laplace-Beltrami operator for deformation regularisation, we view the overall process as Laplacian ICP (L-ICP). This exploits a `small deformation per iteration' assumption and is progressively coarse-to-fine, employing an increasingly flexible deformation model, an increasing number of correspondence sets, and increasingly sophisticated correspondence estimation. Correspondence matching is only permitted within predefined vertex subsets derived from domain-specific feature extractors. Additionally, we present a new benchmark and a pair of evaluation metrics for 3D non-rigid registration, based on annotation transfer. We use this to evaluate our framework on a publicly-available dataset of 3D human head scans (Headspace). The method is robust and only requires a small fraction of the computation time compared to the most popular classical approach, yet has comparable registration performance.
* 7 pages, 6 figures