 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlug-and-Play Spiking Operators: Breaking the Nonlinearity Bottleneck in Spiking Transformers
May 19, 2026ANN-to-SNN conversion offers a practical, training-free route to spiking large language models. However, current pipelines primarily focus on spike-driven realizations for Transformer linear-algebra operations, while providing limited support for key nonlinear operators. This gap limits compatibility with neuromorphic-style execution constraints, where such nonlinearities typically require division, exponentiation, or norm computations that are not naturally supported by standard leaky integrate-and-fire dynamics. To solve this problem, we propose a plug-and-play framework that implements spike-friendly approximations for Transformer nonlinearities and integrates into existing ANN-to-SNN pipelines. Our method decomposes these nonlinear computations into three recurring primitives -- division, exponentiation, and $\ell_2$ norms -- and realizes them via population computation using LIF neuron groups, combined with lightweight bit-shift scaling to avoid floating-point arithmetic. By composing these primitives as modular operator blocks, our framework supports common Transformer nonlinearities (e.g., Softmax, SiLU, and normalization) without any fine-tuning. Experiments on a range of LLMs Transformers show that selectively replacing the targeted nonlinear operators incurs less than a $1\%$ accuracy drop across all evaluated tasks.
VideoExpert: Augmented LLM for Temporal-Sensitive Video Understanding
Apr 10, 2025
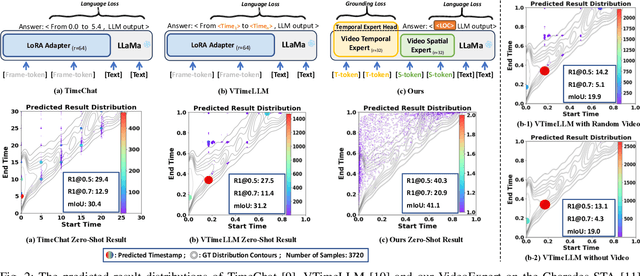
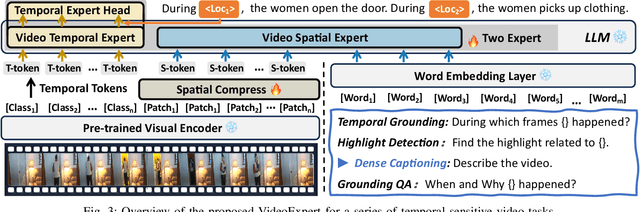
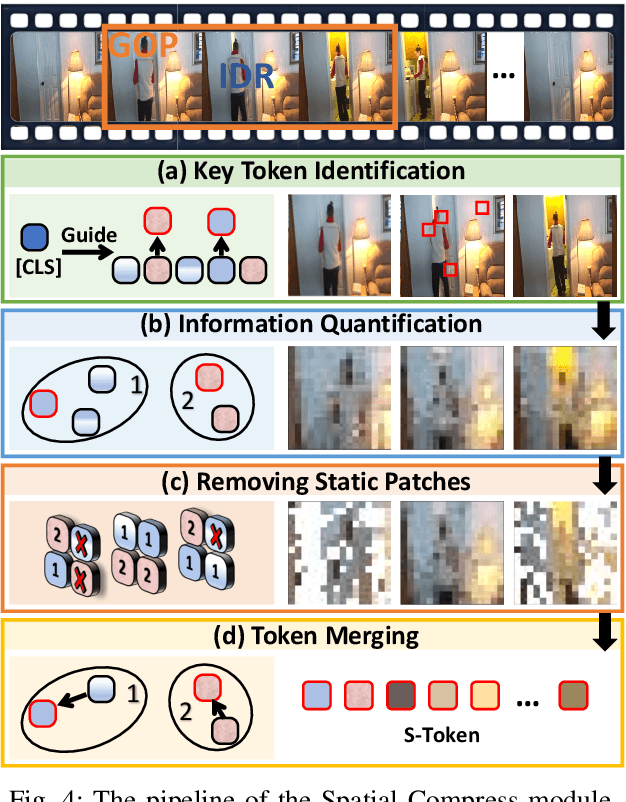
The core challenge in video understanding lies in perceiving dynamic content changes over time. However, multimodal large language models struggle with temporal-sensitive video tasks, which requires generating timestamps to mark the occurrence of specific events. Existing strategies require MLLMs to generate absolute or relative timestamps directly. We have observed that those MLLMs tend to rely more on language patterns than visual cues when generating timestamps, affecting their performance. To address this problem, we propose VideoExpert, a general-purpose MLLM suitable for several temporal-sensitive video tasks. Inspired by the expert concept, VideoExpert integrates two parallel modules: the Temporal Expert and the Spatial Expert. The Temporal Expert is responsible for modeling time sequences and performing temporal grounding. It processes high-frame-rate yet compressed tokens to capture dynamic variations in videos and includes a lightweight prediction head for precise event localization. The Spatial Expert focuses on content detail analysis and instruction following. It handles specially designed spatial tokens and language input, aiming to generate content-related responses. These two experts collaborate seamlessly via a special token, ensuring coordinated temporal grounding and content generation. Notably, the Temporal and Spatial Experts maintain independent parameter sets. By offloading temporal grounding from content generation, VideoExpert prevents text pattern biases in timestamp predictions. Moreover, we introduce a Spatial Compress module to obtain spatial tokens. This module filters and compresses patch tokens while preserving key information, delivering compact yet detail-rich input for the Spatial Expert. Extensive experiments demonstrate the effectiveness and versatility of the VideoExpert.
Diffusion-Enhanced Test-time Adaptation with Text and Image Augmentation
Dec 12, 2024Existing test-time prompt tuning (TPT) methods focus on single-modality data, primarily enhancing images and using confidence ratings to filter out inaccurate images. However, while image generation models can produce visually diverse images, single-modality data enhancement techniques still fail to capture the comprehensive knowledge provided by different modalities. Additionally, we note that the performance of TPT-based methods drops significantly when the number of augmented images is limited, which is not unusual given the computational expense of generative augmentation. To address these issues, we introduce IT3A, a novel test-time adaptation method that utilizes a pre-trained generative model for multi-modal augmentation of each test sample from unknown new domains. By combining augmented data from pre-trained vision and language models, we enhance the ability of the model to adapt to unknown new test data. Additionally, to ensure that key semantics are accurately retained when generating various visual and text enhancements, we employ cosine similarity filtering between the logits of the enhanced images and text with the original test data. This process allows us to filter out some spurious augmentation and inadequate combinations. To leverage the diverse enhancements provided by the generation model across different modals, we have replaced prompt tuning with an adapter for greater flexibility in utilizing text templates. Our experiments on the test datasets with distribution shifts and domain gaps show that in a zero-shot setting, IT3A outperforms state-of-the-art test-time prompt tuning methods with a 5.50% increase in accuracy.
* Accepted by International Journal of Computer Vision
Continuous Spiking Graph Neural Networks
Apr 02, 2024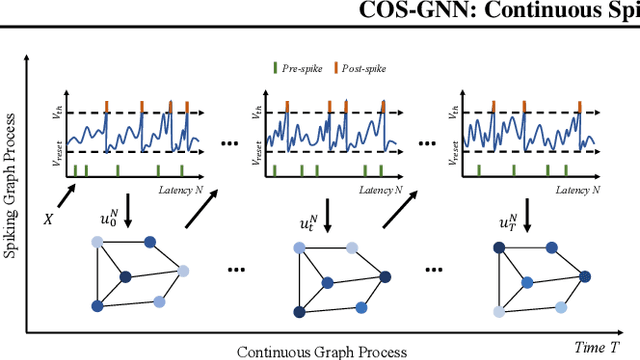
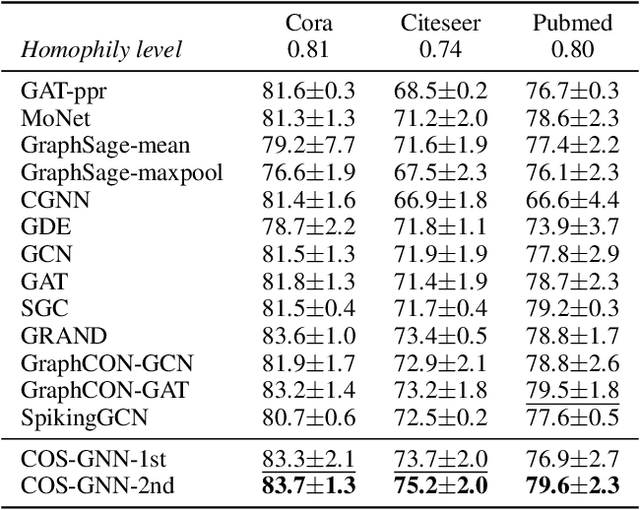
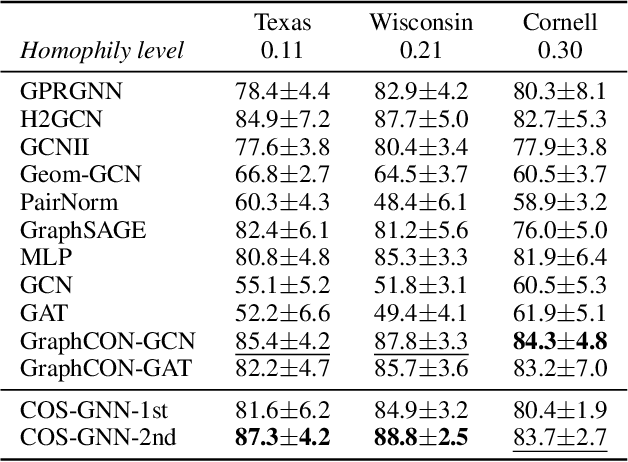
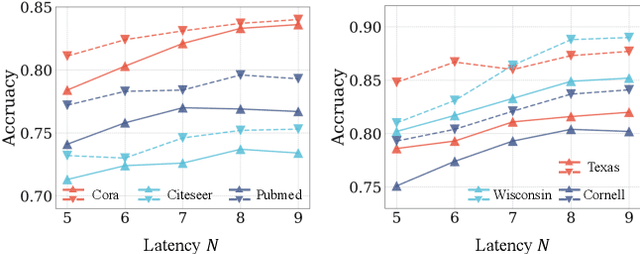
Continuous graph neural networks (CGNNs) have garnered significant attention due to their ability to generalize existing discrete graph neural networks (GNNs) by introducing continuous dynamics. They typically draw inspiration from diffusion-based methods to introduce a novel propagation scheme, which is analyzed using ordinary differential equations (ODE). However, the implementation of CGNNs requires significant computational power, making them challenging to deploy on battery-powered devices. Inspired by recent spiking neural networks (SNNs), which emulate a biological inference process and provide an energy-efficient neural architecture, we incorporate the SNNs with CGNNs in a unified framework, named Continuous Spiking Graph Neural Networks (COS-GNN). We employ SNNs for graph node representation at each time step, which are further integrated into the ODE process along with time. To enhance information preservation and mitigate information loss in SNNs, we introduce the high-order structure of COS-GNN, which utilizes the second-order ODE for spiking representation and continuous propagation. Moreover, we provide the theoretical proof that COS-GNN effectively mitigates the issues of exploding and vanishing gradients, enabling us to capture long-range dependencies between nodes. Experimental results on graph-based learning tasks demonstrate the effectiveness of the proposed COS-GNN over competitive baselines.
Effectiveness Assessment of Recent Large Vision-Language Models
Mar 07, 2024The advent of large vision-language models (LVLMs) represents a noteworthy advancement towards the pursuit of artificial general intelligence. However, the extent of their efficacy across both specialized and general tasks warrants further investigation. This article endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive comprehension of these innovative methodologies. To gauge their efficacy in specialized tasks, we tailor a comprehensive testbed comprising three distinct scenarios: natural, healthcare, and industrial, encompassing six challenging tasks. These tasks include salient, camouflaged, and transparent object detection, as well as polyp and skin lesion detection, alongside industrial anomaly detection. We examine the performance of three recent open-source LVLMs -- MiniGPT-v2, LLaVA-1.5, and Shikra -- in the realm of visual recognition and localization. Moreover, we conduct empirical investigations utilizing the aforementioned models alongside GPT-4V, assessing their multi-modal understanding capacities in general tasks such as object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these models demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deeper into this inadequacy and suggest several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope this study would provide valuable insights for the future development of LVLMs, augmenting their power in coping with both general and specialized applications.
MAST: Video Polyp Segmentation with a Mixture-Attention Siamese Transformer
Jan 23, 2024Accurate segmentation of polyps from colonoscopy videos is of great significance to polyp treatment and early prevention of colorectal cancer. However, it is challenging due to the difficulties associated with modelling long-range spatio-temporal relationships within a colonoscopy video. In this paper, we address this challenging task with a novel Mixture-Attention Siamese Transformer (MAST), which explicitly models the long-range spatio-temporal relationships with a mixture-attention mechanism for accurate polyp segmentation. Specifically, we first construct a Siamese transformer architecture to jointly encode paired video frames for their feature representations. We then design a mixture-attention module to exploit the intra-frame and inter-frame correlations, enhancing the features with rich spatio-temporal relationships. Finally, the enhanced features are fed to two parallel decoders for predicting the segmentation maps. To the best of our knowledge, our MAST is the first transformer model dedicated to video polyp segmentation. Extensive experiments on the large-scale SUN-SEG benchmark demonstrate the superior performance of MAST in comparison with the cutting-edge competitors. Our code is publicly available at https://github.com/Junqing-Yang/MAST.
A Unified Query-based Paradigm for Camouflaged Instance Segmentation
Aug 29, 2023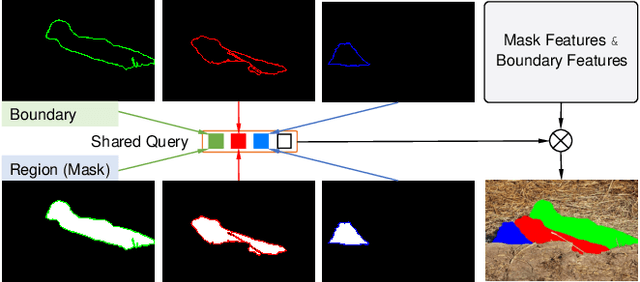
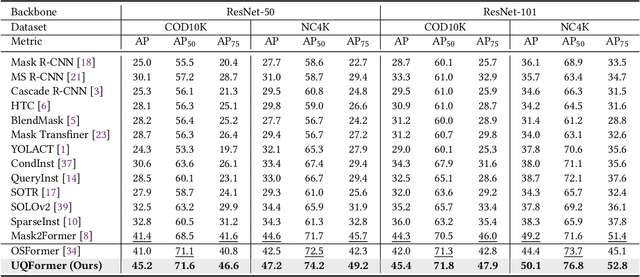
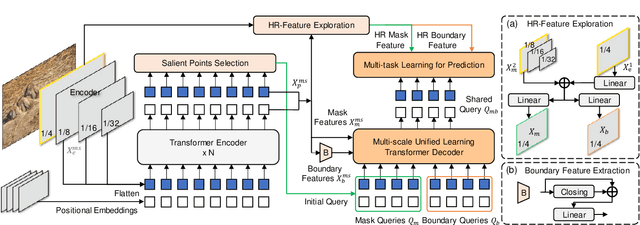

Due to the high similarity between camouflaged instances and the background, the recently proposed camouflaged instance segmentation (CIS) faces challenges in accurate localization and instance segmentation. To this end, inspired by query-based transformers, we propose a unified query-based multi-task learning framework for camouflaged instance segmentation, termed UQFormer, which builds a set of mask queries and a set of boundary queries to learn a shared composed query representation and efficiently integrates global camouflaged object region and boundary cues, for simultaneous instance segmentation and instance boundary detection in camouflaged scenarios. Specifically, we design a composed query learning paradigm that learns a shared representation to capture object region and boundary features by the cross-attention interaction of mask queries and boundary queries in the designed multi-scale unified learning transformer decoder. Then, we present a transformer-based multi-task learning framework for simultaneous camouflaged instance segmentation and camouflaged instance boundary detection based on the learned composed query representation, which also forces the model to learn a strong instance-level query representation. Notably, our model views the instance segmentation as a query-based direct set prediction problem, without other post-processing such as non-maximal suppression. Compared with 14 state-of-the-art approaches, our UQFormer significantly improves the performance of camouflaged instance segmentation. Our code will be available at https://github.com/dongbo811/UQFormer.
Rethinking Polyp Segmentation from an Out-of-Distribution Perspective
Jun 13, 2023Unlike existing fully-supervised approaches, we rethink colorectal polyp segmentation from an out-of-distribution perspective with a simple but effective self-supervised learning approach. We leverage the ability of masked autoencoders -- self-supervised vision transformers trained on a reconstruction task -- to learn in-distribution representations; here, the distribution of healthy colon images. We then perform out-of-distribution reconstruction and inference, with feature space standardisation to align the latent distribution of the diverse abnormal samples with the statistics of the healthy samples. We generate per-pixel anomaly scores for each image by calculating the difference between the input and reconstructed images and use this signal for out-of-distribution (ie, polyp) segmentation. Experimental results on six benchmarks show that our model has excellent segmentation performance and generalises across datasets. Our code is publicly available at https://github.com/GewelsJI/Polyp-OOD.
Deep ReLU Networks Have Surprisingly Simple Polytopes
May 16, 2023A ReLU network is a piecewise linear function over polytopes. Figuring out the properties of such polytopes is of fundamental importance for the research and development of neural networks. So far, either theoretical or empirical studies on polytopes only stay at the level of counting their number, which is far from a complete characterization of polytopes. To upgrade the characterization to a new level, here we propose to study the shapes of polytopes via the number of simplices obtained by triangulating the polytope. Then, by computing and analyzing the histogram of simplices across polytopes, we find that a ReLU network has relatively simple polytopes under both initialization and gradient descent, although these polytopes theoretically can be rather diverse and complicated. This finding can be appreciated as a novel implicit bias. Next, we use nontrivial combinatorial derivation to theoretically explain why adding depth does not create a more complicated polytope by bounding the average number of faces of polytopes with a function of the dimensionality. Our results concretely reveal what kind of simple functions a network learns and its space partition property. Also, by characterizing the shape of polytopes, the number of simplices be a leverage for other problems, \textit{e.g.}, serving as a generic functional complexity measure to explain the power of popular shortcut networks such as ResNet and analyzing the impact of different regularization strategies on a network's space partition.
Rethink Depth Separation with Intra-layer Links
May 11, 2023



The depth separation theory is nowadays widely accepted as an effective explanation for the power of depth, which consists of two parts: i) there exists a function representable by a deep network; ii) such a function cannot be represented by a shallow network whose width is lower than a threshold. However, this theory is established for feedforward networks. Few studies, if not none, considered the depth separation theory in the context of shortcuts which are the most common network types in solving real-world problems. Here, we find that adding intra-layer links can modify the depth separation theory. First, we report that adding intra-layer links can greatly improve a network's representation capability through bound estimation, explicit construction, and functional space analysis. Then, we modify the depth separation theory by showing that a shallow network with intra-layer links does not need to go as wide as before to express some hard functions constructed by a deep network. Such functions include the renowned "sawtooth" functions. Moreover, the saving of width is up to linear. Our results supplement the existing depth separation theory by examining its limit in the shortcut domain. Also, the mechanism we identify can be translated into analyzing the expressivity of popular shortcut networks such as ResNet and DenseNet, \textit{e.g.}, residual connections empower a network to represent a sawtooth function efficiently.