 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee More, Match Better: Multi-Source Feature Fusion for Two-View Correspondence Learning
Jun 08, 2026Two-view correspondence learning aims to distinguish true correspondences (inliers) from false ones (outliers) in image pairs by leveraging their underlying differences. Existing methods mainly rely on coordinate-based geometric consistency. However, they often struggle with pseudo-consistent outliers in scenes containing repetitive structures, textureless regions, or locally similar geometric patterns. To address this limitation, we propose TriMatch, a multi-source feature fusion framework for two-view correspondence learning, which consists of two parts: feature extraction and feature refinement. In feature extraction, TriMatch jointly extracts geometric, texture semantic, and structural semantic features to provide complementary evidence for correspondence discrimination. To bridge the gap between semantic and geometric features, texture and structural semantic features are aligned with geometric features through dedicated Texture-Geometric Alignment and Structural-Geometric Alignment modules, respectively. We further introduce a Semantic-Guided Correspondence Modulation module, which modulates geometric features using semantic information to suppress geometrically plausible but semantically inconsistent correspondences. In feature refinement, a Hierarchical Semantic-Enhanced Correspondence Refinement strategy progressively models correspondence dependencies and recalibrates multi-context feature responses, enabling more reliable inlier-outlier discrimination. Extensive experiments demonstrate the effectiveness, robustness, and generalization capability of TriMatch.
WaveFilter: Enhancing the Long-Context Capability of Diffusion LLMs via Wavelet-Guided KV Cache Filtering
May 30, 2026Diffusion Large Language Models (DLMs) have demonstrated significant advantages across various tasks. However, constrained by their multi-step iterative inference mechanism, their computational overhead and inference latency in long-context tasks have become core bottlenecks restricting their large-scale deployment. When processing long sequences, existing Key-Value (KV) caching mechanisms often face a dilemma where generation quality degrades drastically, where the core challenge lies in precisely and efficiently filtering critical tokens within ultra-long contexts. Inspired by the human reading process, we propose \textbf{WaveFilter}, a universal and training-free caching framework. This framework innovatively introduces the wavelet transform for decomposition of long sequences to achieve precise identification of key tokens, based on which a sparse KV Cache is constructed to compute the final contextual representation. Experimental results demonstrate that WaveFilter, as a plug-and-play generic framework, significantly enhances the performance of existing mainstream KV Cache methods in complex long-context tasks.
URA-Net: Uncertainty-Integrated Anomaly Perception and Restoration Attention Network for Unsupervised Anomaly Detection
Mar 24, 2026Unsupervised anomaly detection plays a pivotal role in industrial defect inspection and medical image analysis, with most methods relying on the reconstruction framework. However, these methods may suffer from over-generalization, enabling them to reconstruct anomalies well, which leads to poor detection performance. To address this issue, instead of focusing solely on normality reconstruction, we propose an innovative Uncertainty-Integrated Anomaly Perception and Restoration Attention Network (URA-Net), which explicitly restores abnormal patterns to their corresponding normality. First, unlike traditional image reconstruction methods, we utilize a pre-trained convolutional neural network to extract multi-level semantic features as the reconstruction target. To assist the URA-Net learning to restore anomalies, we introduce a novel feature-level artificial anomaly synthesis module to generate anomalous samples for training. Subsequently, a novel uncertainty-integrated anomaly perception module based on Bayesian neural networks is introduced to learn the distributions of anomalous and normal features. This facilitates the estimation of anomalous regions and ambiguous boundaries, laying the foundation for subsequent anomaly restoration. Then, we propose a novel restoration attention mechanism that leverages global normal semantic information to restore detected anomalous regions, thereby obtaining defect-free restored features. Finally, we employ residual maps between input features and restored features for anomaly detection and localization. The comprehensive experimental results on two industrial datasets, MVTec AD and BTAD, along with a medical image dataset, OCT-2017, unequivocally demonstrate the effectiveness and superiority of the proposed method.
SSP-SAM: SAM with Semantic-Spatial Prompt for Referring Expression Segmentation
Mar 18, 2026The Segment Anything Model (SAM) excels at general image segmentation but has limited ability to understand natural language, which restricts its direct application in Referring Expression Segmentation (RES). Toward this end, we propose SSP-SAM, a framework that fully utilizes SAM's segmentation capabilities by integrating a Semantic-Spatial Prompt (SSP) encoder. Specifically, we incorporate both visual and linguistic attention adapters into the SSP encoder, which highlight salient objects within the visual features and discriminative phrases within the linguistic features. This design enhances the referent representation for the prompt generator, resulting in high-quality SSPs that enable SAM to generate precise masks guided by language. Although not specifically designed for Generalized RES (GRES), where the referent may correspond to zero, one, or multiple objects, SSP-SAM naturally supports this more flexible setting without additional modifications. Extensive experiments on widely used RES and GRES benchmarks confirm the superiority of our method. Notably, our approach generates segmentation masks of high quality, achieving strong precision even at strict thresholds such as Pr@0.9. Further evaluation on the PhraseCut dataset demonstrates improved performance in open-vocabulary scenarios compared to existing state-of-the-art RES methods. The code and checkpoints are available at: https://github.com/WayneTomas/SSP-SAM.
Zero-shot HOI Detection with MLLM-based Detector-agnostic Interaction Recognition
Feb 16, 2026Zero-shot Human-object interaction (HOI) detection aims to locate humans and objects in images and recognize their interactions. While advances in open-vocabulary object detection provide promising solutions for object localization, interaction recognition (IR) remains challenging due to the combinatorial diversity of interactions. Existing methods, including two-stage methods, tightly couple IR with a specific detector and rely on coarse-grained vision-language model (VLM) features, which limit generalization to unseen interactions. In this work, we propose a decoupled framework that separates object detection from IR and leverages multi-modal large language models (MLLMs) for zero-shot IR. We introduce a deterministic generation method that formulates IR as a visual question answering task and enforces deterministic outputs, enabling training-free zero-shot IR. To further enhance performance and efficiency by fine-tuning the model, we design a spatial-aware pooling module that integrates appearance and pairwise spatial cues, and a one-pass deterministic matching method that predicts all candidate interactions in a single forward pass. Extensive experiments on HICO-DET and V-COCO demonstrate that our method achieves superior zero-shot performance, strong cross-dataset generalization, and the flexibility to integrate with any object detectors without retraining. The codes are publicly available at https://github.com/SY-Xuan/DA-HOI.
DreamVAR: Taming Reinforced Visual Autoregressive Model for High-Fidelity Subject-Driven Image Generation
Jan 30, 2026Recent advances in subject-driven image generation using diffusion models have attracted considerable attention for their remarkable capabilities in producing high-quality images. Nevertheless, the potential of Visual Autoregressive (VAR) models, despite their unified architecture and efficient inference, remains underexplored. In this work, we present DreamVAR, a novel framework for subject-driven image synthesis built upon a VAR model that employs next-scale prediction. Technically, multi-scale features of the reference subject are first extracted by a visual tokenizer. Instead of interleaving these conditional features with target image tokens across scales, our DreamVAR pre-fills the full subject feature sequence prior to predicting target image tokens. This design simplifies autoregressive dependencies and mitigates the train-test discrepancy in multi-scale conditioning scenario within the VAR paradigm. DreamVAR further incorporates reinforcement learning to jointly enhance semantic alignment and subject consistency. Extensive experiments demonstrate that DreamVAR achieves superior appearance preservation compared to leading diffusion-based methods.
Combating Noisy Labels through Fostering Self- and Neighbor-Consistency
Jan 19, 2026Label noise is pervasive in various real-world scenarios, posing challenges in supervised deep learning. Deep networks are vulnerable to such label-corrupted samples due to the memorization effect. One major stream of previous methods concentrates on identifying clean data for training. However, these methods often neglect imbalances in label noise across different mini-batches and devote insufficient attention to out-of-distribution noisy data. To this end, we propose a noise-robust method named Jo-SNC (\textbf{Jo}int sample selection and model regularization based on \textbf{S}elf- and \textbf{N}eighbor-\textbf{C}onsistency). Specifically, we propose to employ the Jensen-Shannon divergence to measure the ``likelihood'' of a sample being clean or out-of-distribution. This process factors in the nearest neighbors of each sample to reinforce the reliability of clean sample identification. We design a self-adaptive, data-driven thresholding scheme to adjust per-class selection thresholds. While clean samples undergo conventional training, detected in-distribution and out-of-distribution noisy samples are trained following partial label learning and negative learning, respectively. Finally, we advance the model performance further by proposing a triplet consistency regularization that promotes self-prediction consistency, neighbor-prediction consistency, and feature consistency. Extensive experiments on various benchmark datasets and comprehensive ablation studies demonstrate the effectiveness and superiority of our approach over existing state-of-the-art methods.
Contrastive Graph Modeling for Cross-Domain Few-Shot Medical Image Segmentation
Dec 25, 2025Cross-domain few-shot medical image segmentation (CD-FSMIS) offers a promising and data-efficient solution for medical applications where annotations are severely scarce and multimodal analysis is required. However, existing methods typically filter out domain-specific information to improve generalization, which inadvertently limits cross-domain performance and degrades source-domain accuracy. To address this, we present Contrastive Graph Modeling (C-Graph), a framework that leverages the structural consistency of medical images as a reliable domain-transferable prior. We represent image features as graphs, with pixels as nodes and semantic affinities as edges. A Structural Prior Graph (SPG) layer is proposed to capture and transfer target-category node dependencies and enable global structure modeling through explicit node interactions. Building upon SPG layers, we introduce a Subgraph Matching Decoding (SMD) mechanism that exploits semantic relations among nodes to guide prediction. Furthermore, we design a Confusion-minimizing Node Contrast (CNC) loss to mitigate node ambiguity and subgraph heterogeneity by contrastively enhancing node discriminability in the graph space. Our method significantly outperforms prior CD-FSMIS approaches across multiple cross-domain benchmarks, achieving state-of-the-art performance while simultaneously preserving strong segmentation accuracy on the source domain.
See the Text: From Tokenization to Visual Reading
Oct 21, 2025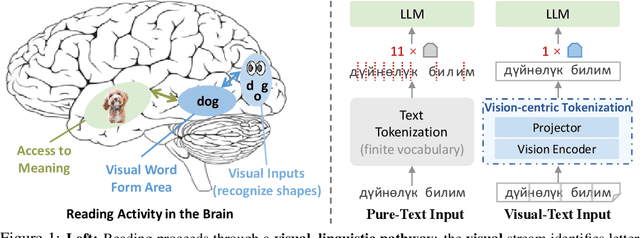

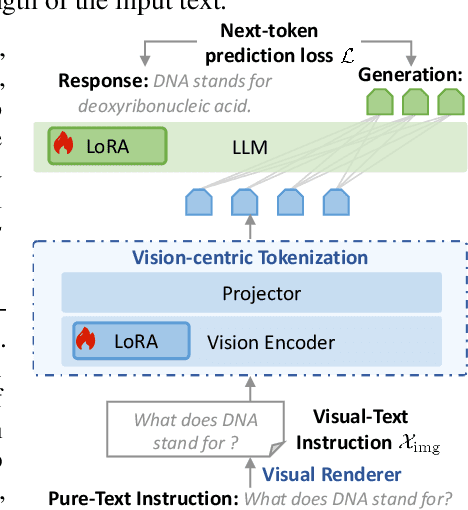

People see text. Humans read by recognizing words as visual objects, including their shapes, layouts, and patterns, before connecting them to meaning, which enables us to handle typos, distorted fonts, and various scripts effectively. Modern large language models (LLMs), however, rely on subword tokenization, fragmenting text into pieces from a fixed vocabulary. While effective for high-resource languages, this approach over-segments low-resource languages, yielding long, linguistically meaningless sequences and inflating computation. In this work, we challenge this entrenched paradigm and move toward a vision-centric alternative. Our method, SeeTok, renders text as images (visual-text) and leverages pretrained multimodal LLMs to interpret them, reusing strong OCR and text-vision alignment abilities learned from large-scale multimodal training. Across three different language tasks, SeeTok matches or surpasses subword tokenizers while requiring 4.43 times fewer tokens and reducing FLOPs by 70.5%, with additional gains in cross-lingual generalization, robustness to typographic noise, and linguistic hierarchy. SeeTok signals a shift from symbolic tokenization to human-like visual reading, and takes a step toward more natural and cognitively inspired language models.
Gradient Short-Circuit: Efficient Out-of-Distribution Detection via Feature Intervention
Jul 02, 2025Out-of-Distribution (OOD) detection is critical for safely deploying deep models in open-world environments, where inputs may lie outside the training distribution. During inference on a model trained exclusively with In-Distribution (ID) data, we observe a salient gradient phenomenon: around an ID sample, the local gradient directions for "enhancing" that sample's predicted class remain relatively consistent, whereas OOD samples--unseen in training--exhibit disorganized or conflicting gradient directions in the same neighborhood. Motivated by this observation, we propose an inference-stage technique to short-circuit those feature coordinates that spurious gradients exploit to inflate OOD confidence, while leaving ID classification largely intact. To circumvent the expense of recomputing the logits after this gradient short-circuit, we further introduce a local first-order approximation that accurately captures the post-modification outputs without a second forward pass. Experiments on standard OOD benchmarks show our approach yields substantial improvements. Moreover, the method is lightweight and requires minimal changes to the standard inference pipeline, offering a practical path toward robust OOD detection in real-world applications.