 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying and Correcting Label Noise for Robust GNNs via Influence Contradiction
Jan 24, 2026Graph Neural Networks (GNNs) have shown remarkable capabilities in learning from graph-structured data with various applications such as social analysis and bioinformatics. However, the presence of label noise in real scenarios poses a significant challenge in learning robust GNNs, and their effectiveness can be severely impacted when dealing with noisy labels on graphs, often stemming from annotation errors or inconsistencies. To address this, in this paper we propose a novel approach called ICGNN that harnesses the structure information of the graph to effectively alleviate the challenges posed by noisy labels. Specifically, we first design a novel noise indicator that measures the influence contradiction score (ICS) based on the graph diffusion matrix to quantify the credibility of nodes with clean labels, such that nodes with higher ICS values are more likely to be detected as having noisy labels. Then we leverage the Gaussian mixture model to precisely detect whether the label of a node is noisy or not. Additionally, we develop a soft strategy to combine the predictions from neighboring nodes on the graph to correct the detected noisy labels. At last, pseudo-labeling for abundant unlabeled nodes is incorporated to provide auxiliary supervision signals and guide the model optimization. Experiments on benchmark datasets show the superiority of our proposed approach.
GROVER: Graph-guided Representation of Omics and Vision with Expert Regulation for Adaptive Spatial Multi-omics Fusion
Nov 13, 2025Effectively modeling multimodal spatial omics data is critical for understanding tissue complexity and underlying biological mechanisms. While spatial transcriptomics, proteomics, and epigenomics capture molecular features, they lack pathological morphological context. Integrating these omics with histopathological images is therefore essential for comprehensive disease tissue analysis. However, substantial heterogeneity across omics, imaging, and spatial modalities poses significant challenges. Naive fusion of semantically distinct sources often leads to ambiguous representations. Additionally, the resolution mismatch between high-resolution histology images and lower-resolution sequencing spots complicates spatial alignment. Biological perturbations during sample preparation further distort modality-specific signals, hindering accurate integration. To address these challenges, we propose Graph-guided Representation of Omics and Vision with Expert Regulation for Adaptive Spatial Multi-omics Fusion (GROVER), a novel framework for adaptive integration of spatial multi-omics data. GROVER leverages a Graph Convolutional Network encoder based on Kolmogorov-Arnold Networks to capture the nonlinear dependencies between each modality and its associated spatial structure, thereby producing expressive, modality-specific embeddings. To align these representations, we introduce a spot-feature-pair contrastive learning strategy that explicitly optimizes the correspondence across modalities at each spot. Furthermore, we design a dynamic expert routing mechanism that adaptively selects informative modalities for each spot while suppressing noisy or low-quality inputs. Experiments on real-world spatial omics datasets demonstrate that GROVER outperforms state-of-the-art baselines, providing a robust and reliable solution for multimodal integration.
Gradient Short-Circuit: Efficient Out-of-Distribution Detection via Feature Intervention
Jul 02, 2025Out-of-Distribution (OOD) detection is critical for safely deploying deep models in open-world environments, where inputs may lie outside the training distribution. During inference on a model trained exclusively with In-Distribution (ID) data, we observe a salient gradient phenomenon: around an ID sample, the local gradient directions for "enhancing" that sample's predicted class remain relatively consistent, whereas OOD samples--unseen in training--exhibit disorganized or conflicting gradient directions in the same neighborhood. Motivated by this observation, we propose an inference-stage technique to short-circuit those feature coordinates that spurious gradients exploit to inflate OOD confidence, while leaving ID classification largely intact. To circumvent the expense of recomputing the logits after this gradient short-circuit, we further introduce a local first-order approximation that accurately captures the post-modification outputs without a second forward pass. Experiments on standard OOD benchmarks show our approach yields substantial improvements. Moreover, the method is lightweight and requires minimal changes to the standard inference pipeline, offering a practical path toward robust OOD detection in real-world applications.
SplitLoRA: Balancing Stability and Plasticity in Continual Learning Through Gradient Space Splitting
May 29, 2025Continual Learning requires a model to learn multiple tasks in sequence while maintaining both stability:preserving knowledge from previously learned tasks, and plasticity:effectively learning new tasks. Gradient projection has emerged as an effective and popular paradigm in CL, where it partitions the gradient space of previously learned tasks into two orthogonal subspaces: a primary subspace and a minor subspace. New tasks are learned effectively within the minor subspace, thereby reducing interference with previously acquired knowledge. However, existing Gradient Projection methods struggle to achieve an optimal balance between plasticity and stability, as it is hard to appropriately partition the gradient space. In this work, we consider a continual learning paradigm based on Low-Rank Adaptation, which has gained considerable attention due to its efficiency and wide applicability, and propose a novel approach for continual learning, called SplitLoRA. We first provide a theoretical analysis of how subspace partitioning affects model stability and plasticity. Informed by this analysis, we then introduce an effective method that derives the optimal partition of the gradient space for previously learned tasks. This approach effectively balances stability and plasticity in continual learning. Experimental results on multiple datasets demonstrate that the proposed method achieves state-of-the-art performance.
Train with Perturbation, Infer after Merging: A Two-Stage Framework for Continual Learning
May 29, 2025Continual Learning (CL) aims to enable models to continuously acquire new knowledge from a sequence of tasks with avoiding the forgetting of learned information. However, existing CL methods only rely on the parameters of the most recent task for inference, which makes them susceptible to catastrophic forgetting. Inspired by the recent success of model merging techniques, we propose \textbf{Perturb-and-Merge (P\&M)}, a novel continual learning framework that integrates model merging into the CL paradigm to mitigate forgetting. Specifically, after training on each task, P\&M constructs a new model by forming a convex combination of the previous model and the newly trained task-specific model. Through theoretical analysis, we minimize the total loss increase across all tasks and derive an analytical solution for the optimal merging coefficient. To further improve the performance of the merged model, we observe that the degradation introduced during merging can be alleviated by a regularization term composed of the task vector and the Hessian matrix of the loss function. Interestingly, we show that this term can be efficiently approximated using second-order symmetric finite differences, and a stochastic perturbation strategy along the task vector direction is accordingly devised which incurs no additional forward or backward passes while providing an effective approximation of the regularization term. Finally, we combine P\&M with LoRA, a parameter-efficient fine-tuning method, to reduce memory overhead. Our proposed approach achieves state-of-the-art performance on several continual learning benchmark datasets.
GCAL: Adapting Graph Models to Evolving Domain Shifts
May 22, 2025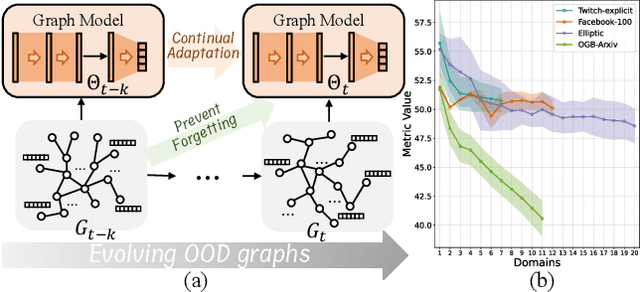
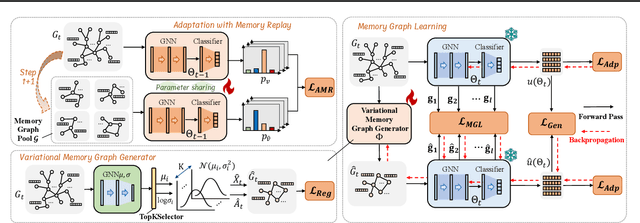
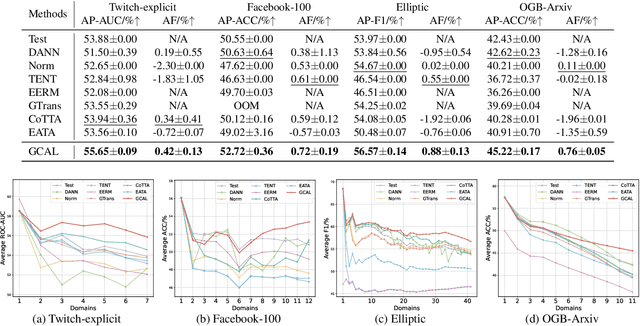
This paper addresses the challenge of graph domain adaptation on evolving, multiple out-of-distribution (OOD) graphs. Conventional graph domain adaptation methods are confined to single-step adaptation, making them ineffective in handling continuous domain shifts and prone to catastrophic forgetting. This paper introduces the Graph Continual Adaptive Learning (GCAL) method, designed to enhance model sustainability and adaptability across various graph domains. GCAL employs a bilevel optimization strategy. The "adapt" phase uses an information maximization approach to fine-tune the model with new graph domains while re-adapting past memories to mitigate forgetting. Concurrently, the "generate memory" phase, guided by a theoretical lower bound derived from information bottleneck theory, involves a variational memory graph generation module to condense original graphs into memories. Extensive experimental evaluations demonstrate that GCAL substantially outperforms existing methods in terms of adaptability and knowledge retention.
NeuBM: Mitigating Model Bias in Graph Neural Networks through Neutral Input Calibration
May 21, 2025Graph Neural Networks (GNNs) have shown remarkable performance across various domains, yet they often struggle with model bias, particularly in the presence of class imbalance. This bias can lead to suboptimal performance and unfair predictions, especially for underrepresented classes. We introduce NeuBM (Neutral Bias Mitigation), a novel approach to mitigate model bias in GNNs through neutral input calibration. NeuBM leverages a dynamically updated neutral graph to estimate and correct the inherent biases of the model. By subtracting the logits obtained from the neutral graph from those of the input graph, NeuBM effectively recalibrates the model's predictions, reducing bias across different classes. Our method integrates seamlessly into existing GNN architectures and training procedures, requiring minimal computational overhead. Extensive experiments on multiple benchmark datasets demonstrate that NeuBM significantly improves the balanced accuracy and recall of minority classes, while maintaining strong overall performance. The effectiveness of NeuBM is particularly pronounced in scenarios with severe class imbalance and limited labeled data, where traditional methods often struggle. We provide theoretical insights into how NeuBM achieves bias mitigation, relating it to the concept of representation balancing. Our analysis reveals that NeuBM not only adjusts the final predictions but also influences the learning of balanced feature representations throughout the network.
SpectralGap: Graph-Level Out-of-Distribution Detection via Laplacian Eigenvalue Gaps
May 21, 2025The task of graph-level out-of-distribution (OOD) detection is crucial for deploying graph neural networks in real-world settings. In this paper, we observe a significant difference in the relationship between the largest and second-largest eigenvalues of the Laplacian matrix for in-distribution (ID) and OOD graph samples: \textit{OOD samples often exhibit anomalous spectral gaps (the difference between the largest and second-largest eigenvalues)}. This observation motivates us to propose SpecGap, an effective post-hoc approach for OOD detection on graphs. SpecGap adjusts features by subtracting the component associated with the second-largest eigenvalue, scaled by the spectral gap, from the high-level features (i.e., $\mathbf{X}-\left(\lambda_n-\lambda_{n-1}\right) \mathbf{u}_{n-1} \mathbf{v}_{n-1}^T$). SpecGap achieves state-of-the-art performance across multiple benchmark datasets. We present extensive ablation studies and comprehensive theoretical analyses to support our empirical results. As a parameter-free post-hoc method, SpecGap can be easily integrated into existing graph neural network models without requiring any additional training or model modification.
Disentangled Multi-span Evolutionary Network against Temporal Knowledge Graph Reasoning
May 20, 2025Temporal Knowledge Graphs (TKGs), as an extension of static Knowledge Graphs (KGs), incorporate the temporal feature to express the transience of knowledge by describing when facts occur. TKG extrapolation aims to infer possible future facts based on known history, which has garnered significant attention in recent years. Some existing methods treat TKG as a sequence of independent subgraphs to model temporal evolution patterns, demonstrating impressive reasoning performance. However, they still have limitations: 1) In modeling subgraph semantic evolution, they usually neglect the internal structural interactions between subgraphs, which are actually crucial for encoding TKGs. 2) They overlook the potential smooth features that do not lead to semantic changes, which should be distinguished from the semantic evolution process. Therefore, we propose a novel Disentangled Multi-span Evolutionary Network (DiMNet) for TKG reasoning. Specifically, we design a multi-span evolution strategy that captures local neighbor features while perceiving historical neighbor semantic information, thus enabling internal interactions between subgraphs during the evolution process. To maximize the capture of semantic change patterns, we design a disentangle component that adaptively separates nodes' active and stable features, used to dynamically control the influence of historical semantics on future evolution. Extensive experiments conducted on four real-world TKG datasets show that DiMNet demonstrates substantial performance in TKG reasoning, and outperforms the state-of-the-art up to 22.7% in MRR.
Rethinking Graph Contrastive Learning through Relative Similarity Preservation
May 08, 2025Graph contrastive learning (GCL) has achieved remarkable success by following the computer vision paradigm of preserving absolute similarity between augmented views. However, this approach faces fundamental challenges in graphs due to their discrete, non-Euclidean nature -- view generation often breaks semantic validity and similarity verification becomes unreliable. Through analyzing 11 real-world graphs, we discover a universal pattern transcending the homophily-heterophily dichotomy: label consistency systematically diminishes as structural distance increases, manifesting as smooth decay in homophily graphs and oscillatory decay in heterophily graphs. We establish theoretical guarantees for this pattern through random walk theory, proving label distribution convergence and characterizing the mechanisms behind different decay behaviors. This discovery reveals that graphs naturally encode relative similarity patterns, where structurally closer nodes exhibit collectively stronger semantic relationships. Leveraging this insight, we propose RELGCL, a novel GCL framework with complementary pairwise and listwise implementations that preserve these inherent patterns through collective similarity objectives. Extensive experiments demonstrate that our method consistently outperforms 20 existing approaches across both homophily and heterophily graphs, validating the effectiveness of leveraging natural relative similarity over artificial absolute similarity.