 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Paper-to-Paper: Structured Profiling and Rubric Scoring for Paper-Reviewer Matching
Apr 07, 2026As conference submission volumes continue to grow, accurately recommending suitable reviewers has become a challenge. Most existing methods follow a ``Paper-to-Paper'' matching paradigm, implicitly representing a reviewer by their publication history. However, effective reviewer matching requires capturing multi-dimensional expertise, and textual similarity to past papers alone is often insufficient. To address this gap, we propose P2R, a training-free framework that shifts from implicit paper-to-paper matching to explicit profile-based matching. P2R uses general-purpose LLMs to construct structured profiles for both submissions and reviewers, disentangling them into Topics, Methodologies, and Applications. Building on these profiles, P2R adopts a coarse-to-fine pipeline to balance efficiency and depth. It first performs hybrid retrieval that combines semantic and aspect-level signals to form a high-recall candidate pool, and then applies an LLM-based committee to evaluate candidates under strict rubrics, integrating both multi-dimensional expert views and a holistic Area Chair perspective. Experiments on NeurIPS, SIGIR, and SciRepEval show that P2R consistently outperforms state-of-the-art baselines. Ablation studies further verify the necessity of each component. Overall, P2R highlights the value of explicit, structured expertise modeling and offers practical guidance for applying LLMs to reviewer matching.
Graph-GRPO: Stabilizing Multi-Agent Topology Learning via Group Relative Policy Optimization
Mar 03, 2026Optimizing communication topology is fundamental to the efficiency and effectiveness of Large Language Model (LLM)-based Multi-Agent Systems (MAS). While recent approaches utilize reinforcement learning to dynamically construct task-specific graphs, they typically rely on single-sample policy gradients with absolute rewards (e.g., binary correctness). This paradigm suffers from severe gradient variance and the credit assignment problem: simple queries yield non-informative positive rewards for suboptimal structures, while difficult queries often result in failures that provide no learning signal. To address these challenges, we propose Graph-GRPO, a novel topology optimization framework that integrates Group Relative Policy Optimization. Instead of evaluating a single topology in isolation, Graph-GRPO samples a group of diverse communication graphs for each query and computes the advantage of specific edges based on their relative performance within the group. By normalizing rewards across the sampled group, our method effectively mitigates the noise derived from task difficulty variance and enables fine-grained credit assignment. Extensive experiments on reasoning and code generation benchmarks demonstrate that Graph-GRPO significantly outperforms state-of-the-art baselines, achieving superior training stability and identifying critical communication pathways previously obscured by reward noise.
MOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
Distilling Closed-Source LLM's Knowledge for Locally Stable and Economic Biomedical Entity Linking
May 26, 2025Biomedical entity linking aims to map nonstandard entities to standard entities in a knowledge base. Traditional supervised methods perform well but require extensive annotated data to transfer, limiting their usage in low-resource scenarios. Large language models (LLMs), especially closed-source LLMs, can address these but risk stability issues and high economic costs: using these models is restricted by commercial companies and brings significant economic costs when dealing with large amounts of data. To address this, we propose ``RPDR'', a framework combining closed-source LLMs and open-source LLMs for re-ranking candidates retrieved by a retriever fine-tuned with a small amount of data. By prompting a closed-source LLM to generate training data from unannotated data and fine-tuning an open-source LLM for re-ranking, we effectively distill the knowledge to the open-source LLM that can be deployed locally, thus avoiding the stability issues and the problem of high economic costs. We evaluate RPDR on two datasets, including one real-world dataset and one publicly available dataset involving two languages: Chinese and English. RPDR achieves 0.019 Acc@1 improvement and 0.036 Acc@1 improvement on the Aier dataset and the Ask A Patient dataset when the amount of training data is not enough. The results demonstrate the superiority and generalizability of the proposed framework.
Disentangled Multi-span Evolutionary Network against Temporal Knowledge Graph Reasoning
May 20, 2025Temporal Knowledge Graphs (TKGs), as an extension of static Knowledge Graphs (KGs), incorporate the temporal feature to express the transience of knowledge by describing when facts occur. TKG extrapolation aims to infer possible future facts based on known history, which has garnered significant attention in recent years. Some existing methods treat TKG as a sequence of independent subgraphs to model temporal evolution patterns, demonstrating impressive reasoning performance. However, they still have limitations: 1) In modeling subgraph semantic evolution, they usually neglect the internal structural interactions between subgraphs, which are actually crucial for encoding TKGs. 2) They overlook the potential smooth features that do not lead to semantic changes, which should be distinguished from the semantic evolution process. Therefore, we propose a novel Disentangled Multi-span Evolutionary Network (DiMNet) for TKG reasoning. Specifically, we design a multi-span evolution strategy that captures local neighbor features while perceiving historical neighbor semantic information, thus enabling internal interactions between subgraphs during the evolution process. To maximize the capture of semantic change patterns, we design a disentangle component that adaptively separates nodes' active and stable features, used to dynamically control the influence of historical semantics on future evolution. Extensive experiments conducted on four real-world TKG datasets show that DiMNet demonstrates substantial performance in TKG reasoning, and outperforms the state-of-the-art up to 22.7% in MRR.
scSiameseClu: A Siamese Clustering Framework for Interpreting single-cell RNA Sequencing Data
May 19, 2025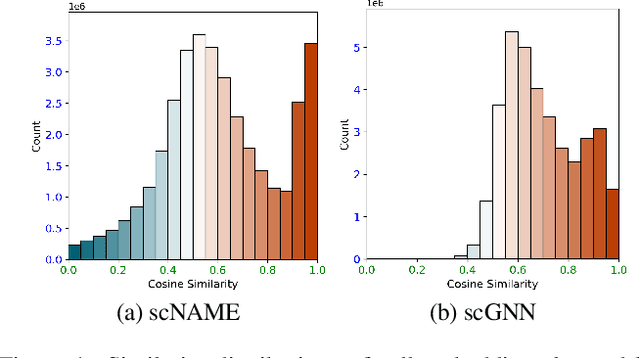
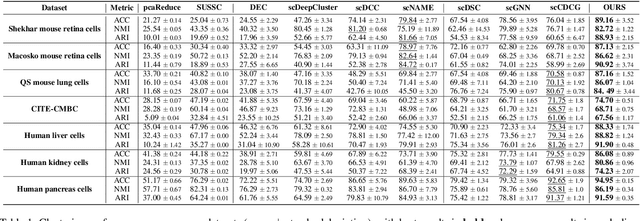
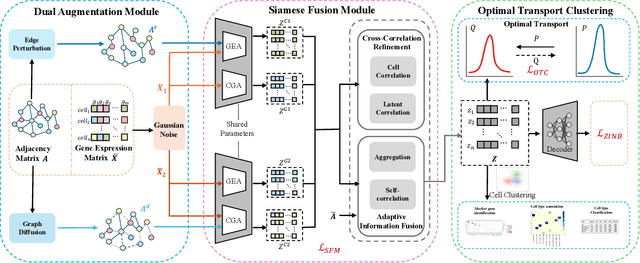
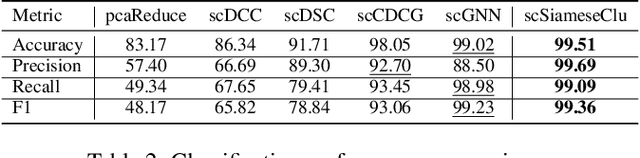
Single-cell RNA sequencing (scRNA-seq) reveals cell heterogeneity, with cell clustering playing a key role in identifying cell types and marker genes. Recent advances, especially graph neural networks (GNNs)-based methods, have significantly improved clustering performance. However, the analysis of scRNA-seq data remains challenging due to noise, sparsity, and high dimensionality. Compounding these challenges, GNNs often suffer from over-smoothing, limiting their ability to capture complex biological information. In response, we propose scSiameseClu, a novel Siamese Clustering framework for interpreting single-cell RNA-seq data, comprising of 3 key steps: (1) Dual Augmentation Module, which applies biologically informed perturbations to the gene expression matrix and cell graph relationships to enhance representation robustness; (2) Siamese Fusion Module, which combines cross-correlation refinement and adaptive information fusion to capture complex cellular relationships while mitigating over-smoothing; and (3) Optimal Transport Clustering, which utilizes Sinkhorn distance to efficiently align cluster assignments with predefined proportions while maintaining balance. Comprehensive evaluations on seven real-world datasets demonstrate that~\methodname~outperforms state-of-the-art methods in single-cell clustering, cell type annotation, and cell type classification, providing a powerful tool for scRNA-seq data interpretation.
Rethinking Graph Contrastive Learning through Relative Similarity Preservation
May 08, 2025Graph contrastive learning (GCL) has achieved remarkable success by following the computer vision paradigm of preserving absolute similarity between augmented views. However, this approach faces fundamental challenges in graphs due to their discrete, non-Euclidean nature -- view generation often breaks semantic validity and similarity verification becomes unreliable. Through analyzing 11 real-world graphs, we discover a universal pattern transcending the homophily-heterophily dichotomy: label consistency systematically diminishes as structural distance increases, manifesting as smooth decay in homophily graphs and oscillatory decay in heterophily graphs. We establish theoretical guarantees for this pattern through random walk theory, proving label distribution convergence and characterizing the mechanisms behind different decay behaviors. This discovery reveals that graphs naturally encode relative similarity patterns, where structurally closer nodes exhibit collectively stronger semantic relationships. Leveraging this insight, we propose RELGCL, a novel GCL framework with complementary pairwise and listwise implementations that preserve these inherent patterns through collective similarity objectives. Extensive experiments demonstrate that our method consistently outperforms 20 existing approaches across both homophily and heterophily graphs, validating the effectiveness of leveraging natural relative similarity over artificial absolute similarity.
Collaborative Multi-Agent Reinforcement Learning for Automated Feature Transformation with Graph-Driven Path Optimization
Apr 24, 2025



Feature transformation methods aim to find an optimal mathematical feature-feature crossing process that generates high-value features and improves the performance of downstream machine learning tasks. Existing frameworks, though designed to mitigate manual costs, often treat feature transformations as isolated operations, ignoring dynamic dependencies between transformation steps. To address the limitations, we propose TCTO, a collaborative multi-agent reinforcement learning framework that automates feature engineering through graph-driven path optimization. The framework's core innovation lies in an evolving interaction graph that models features as nodes and transformations as edges. Through graph pruning and backtracking, it dynamically eliminates low-impact edges, reduces redundant operations, and enhances exploration stability. This graph also provides full traceability to empower TCTO to reuse high-utility subgraphs from historical transformations. To demonstrate the efficacy and adaptability of our approach, we conduct comprehensive experiments and case studies, which show superior performance across a range of datasets.
Deep Cut-informed Graph Embedding and Clustering
Mar 09, 2025Graph clustering aims to divide the graph into different clusters. The recently emerging deep graph clustering approaches are largely built on graph neural networks (GNN). However, GNN is designed for general graph encoding and there is a common issue of representation collapse in existing GNN-based deep graph clustering algorithms. We attribute two main reasons for such issue: (i) the inductive bias of GNN models: GNNs tend to generate similar representations for proximal nodes. Since graphs often contain a non-negligible amount of inter-cluster links, the bias results in error message passing and leads to biased clustering; (ii) the clustering guided loss function: most traditional approaches strive to make all samples closer to pre-learned cluster centers, which cause a degenerate solution assigning all data points to a single label thus make all samples and less discriminative. To address these challenges, we investigate graph clustering from a graph cut perspective and propose an innovative and non-GNN-based Deep Cut-informed Graph embedding and Clustering framework, namely DCGC. This framework includes two modules: (i) cut-informed graph encoding; (ii) self-supervised graph clustering via optimal transport. For the encoding module, we derive a cut-informed graph embedding objective to fuse graph structure and attributes by minimizing their joint normalized cut. For the clustering module, we utilize the optimal transport theory to obtain the clustering assignments, which can balance the guidance of proximity to the pre-learned cluster center. With the above two tailored designs, DCGC is more suitable for the graph clustering task, which can effectively alleviate the problem of representation collapse and achieve better performance. We conduct extensive experiments to demonstrate that our method is simple but effective compared with benchmarks.
Stealthy Voice Eavesdropping with Acoustic Metamaterials: Unraveling a New Privacy Threat
Jan 25, 2025



We present SuperEar, a novel privacy threat based on acoustic metamaterials. Unlike previous research, SuperEar can surreptitiously track and eavesdrop on the phone calls of a moving outdoor target from a safe distance. To design this attack, SuperEar overcomes the challenges faced by traditional acoustic metamaterials, including low low-frequency gain and audio distortion during reconstruction. It successfully magnifies the speech signal by approximately 20 times, allowing the sound to be captured from the earpiece of the target phone. In addition, SuperEar optimizes the trade-off between the number and size of acoustic metamaterials, improving the portability and concealability of the interceptor while ensuring effective interception performance. This makes it highly suitable for outdoor tracking and eavesdropping scenarios. Through extensive experimentation, we have evaluated SuperEar and our results show that it can achieve an eavesdropping accuracy of over 80% within a range of 4.5 meters in the aforementioned scenario, thus validating its great potential in real-world applications.