 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Scenario-Aware Planning for Autonomous Driving
Jan 29, 2026Hybrid planner switching framework (HPSF) for autonomous driving needs to reconcile high-speed driving efficiency with safe maneuvering in dense traffic. Existing HPSF methods often fail to make reliable mode transitions or sustain efficient driving in congested environments, owing to heuristic scene recognition and low-frequency control updates. To address the limitation, this paper proposes LAP, a large language model (LLM) driven, adaptive planning method, which switches between high-speed driving in low-complexity scenes and precise driving in high-complexity scenes, enabling high qualities of trajectory generation through confined gaps. This is achieved by leveraging LLM for scene understanding and integrating its inference into the joint optimization of mode configuration and motion planning. The joint optimization is solved using tree-search model predictive control and alternating minimization. We implement LAP by Python in Robot Operating System (ROS). High-fidelity simulation results show that the proposed LAP outperforms other benchmarks in terms of both driving time and success rate.
Disentangled Multi-span Evolutionary Network against Temporal Knowledge Graph Reasoning
May 20, 2025Temporal Knowledge Graphs (TKGs), as an extension of static Knowledge Graphs (KGs), incorporate the temporal feature to express the transience of knowledge by describing when facts occur. TKG extrapolation aims to infer possible future facts based on known history, which has garnered significant attention in recent years. Some existing methods treat TKG as a sequence of independent subgraphs to model temporal evolution patterns, demonstrating impressive reasoning performance. However, they still have limitations: 1) In modeling subgraph semantic evolution, they usually neglect the internal structural interactions between subgraphs, which are actually crucial for encoding TKGs. 2) They overlook the potential smooth features that do not lead to semantic changes, which should be distinguished from the semantic evolution process. Therefore, we propose a novel Disentangled Multi-span Evolutionary Network (DiMNet) for TKG reasoning. Specifically, we design a multi-span evolution strategy that captures local neighbor features while perceiving historical neighbor semantic information, thus enabling internal interactions between subgraphs during the evolution process. To maximize the capture of semantic change patterns, we design a disentangle component that adaptively separates nodes' active and stable features, used to dynamically control the influence of historical semantics on future evolution. Extensive experiments conducted on four real-world TKG datasets show that DiMNet demonstrates substantial performance in TKG reasoning, and outperforms the state-of-the-art up to 22.7% in MRR.
Coop-WD: Cooperative Perception with Weighting and Denoising for Robust V2V Communication
May 06, 2025Cooperative perception, leveraging shared information from multiple vehicles via vehicle-to-vehicle (V2V) communication, plays a vital role in autonomous driving to alleviate the limitation of single-vehicle perception. Existing works have explored the effects of V2V communication impairments on perception precision, but they lack generalization to different levels of impairments. In this work, we propose a joint weighting and denoising framework, Coop-WD, to enhance cooperative perception subject to V2V channel impairments. In this framework, the self-supervised contrastive model and the conditional diffusion probabilistic model are adopted hierarchically for vehicle-level and pixel-level feature enhancement. An efficient variant model, Coop-WD-eco, is proposed to selectively deactivate denoising to reduce processing overhead. Rician fading, non-stationarity, and time-varying distortion are considered. Simulation results demonstrate that the proposed Coop-WD outperforms conventional benchmarks in all types of channels. Qualitative analysis with visual examples further proves the superiority of our proposed method. The proposed Coop-WD-eco achieves up to 50% reduction in computational cost under severe distortion while maintaining comparable accuracy as channel conditions improve.
ClimateGS: Real-Time Climate Simulation with 3D Gaussian Style Transfer
Mar 19, 2025Adverse climate conditions pose significant challenges for autonomous systems, demanding reliable perception and decision-making across diverse environments. To better simulate these conditions, physically-based NeRF rendering methods have been explored for their ability to generate realistic scene representations. However, these methods suffer from slow rendering speeds and long preprocessing times, making them impractical for real-time testing and user interaction. This paper presents ClimateGS, a novel framework integrating 3D Gaussian representations with physical simulation to enable real-time climate effects rendering. The novelty of this work is threefold: 1) developing a linear transformation for 3D Gaussian photorealistic style transfer, enabling direct modification of spherical harmonics across bands for efficient and consistent style adaptation; 2) developing a joint training strategy for 3D style transfer, combining supervised and self-supervised learning to accelerate convergence while preserving original scene details; 3) developing a real-time rendering method for climate simulation, integrating physics-based effects with 3D Gaussian to achieve efficient and realistic rendering. We evaluate ClimateGS on MipNeRF360 and Tanks and Temples, demonstrating real-time rendering with comparable or superior visual quality to SOTA 2D/3D methods, making it suitable for interactive applications.
SemanticFlow: A Self-Supervised Framework for Joint Scene Flow Prediction and Instance Segmentation in Dynamic Environments
Mar 19, 2025Accurate perception of dynamic traffic scenes is crucial for high-level autonomous driving systems, requiring robust object motion estimation and instance segmentation. However, traditional methods often treat them as separate tasks, leading to suboptimal performance, spatio-temporal inconsistencies, and inefficiency in complex scenarios due to the absence of information sharing. This paper proposes a multi-task SemanticFlow framework to simultaneously predict scene flow and instance segmentation of full-resolution point clouds. The novelty of this work is threefold: 1) developing a coarse-to-fine prediction based multi-task scheme, where an initial coarse segmentation of static backgrounds and dynamic objects is used to provide contextual information for refining motion and semantic information through a shared feature processing module; 2) developing a set of loss functions to enhance the performance of scene flow estimation and instance segmentation, while can help ensure spatial and temporal consistency of both static and dynamic objects within traffic scenes; 3) developing a self-supervised learning scheme, which utilizes coarse segmentation to detect rigid objects and compute their transformation matrices between sequential frames, enabling the generation of self-supervised labels. The proposed framework is validated on the Argoverse and Waymo datasets, demonstrating superior performance in instance segmentation accuracy, scene flow estimation, and computational efficiency, establishing a new benchmark for self-supervised methods in dynamic scene understanding.
SSF-PAN: Semantic Scene Flow-Based Perception for Autonomous Navigation in Traffic Scenarios
Jan 28, 2025Vehicle detection and localization in complex traffic scenarios pose significant challenges due to the interference of moving objects. Traditional methods often rely on outlier exclusions or semantic segmentations, which suffer from low computational efficiency and accuracy. The proposed SSF-PAN can achieve the functionalities of LiDAR point cloud based object detection/localization and SLAM (Simultaneous Localization and Mapping) with high computational efficiency and accuracy, enabling map-free navigation frameworks. The novelty of this work is threefold: 1) developing a neural network which can achieve segmentation among static and dynamic objects within the scene flows with different motion features, that is, semantic scene flow (SSF); 2) developing an iterative framework which can further optimize the quality of input scene flows and output segmentation results; 3) developing a scene flow-based navigation platform which can test the performance of the SSF perception system in the simulation environment. The proposed SSF-PAN method is validated using the SUScape-CARLA and the KITTI datasets, as well as on the CARLA simulator. Experimental results demonstrate that the proposed approach outperforms traditional methods in terms of scene flow computation accuracy, moving object detection accuracy, computational efficiency, and autonomous navigation effectiveness.
TSceneJAL: Joint Active Learning of Traffic Scenes for 3D Object Detection
Dec 25, 2024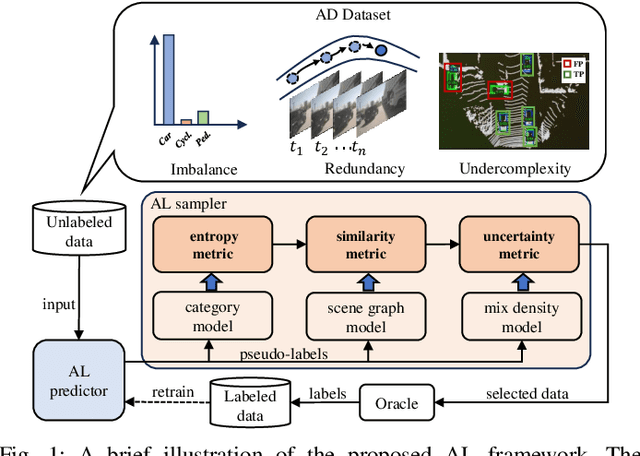
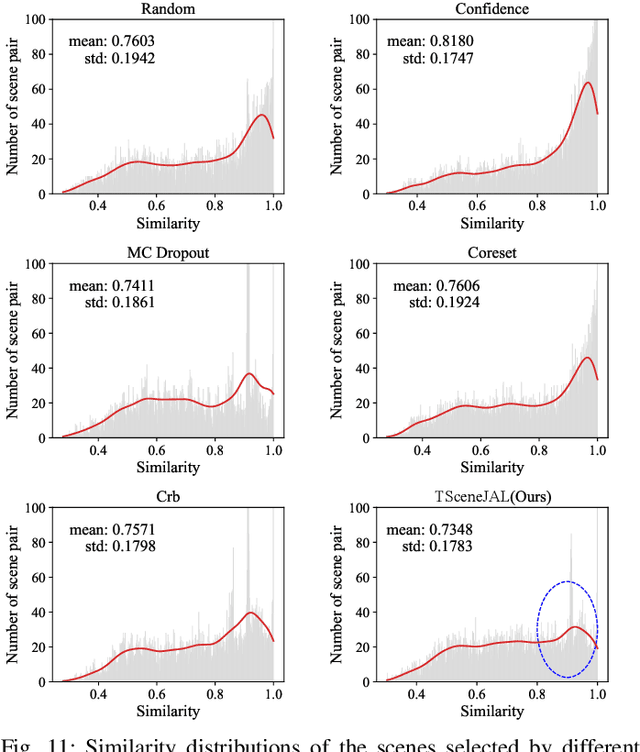
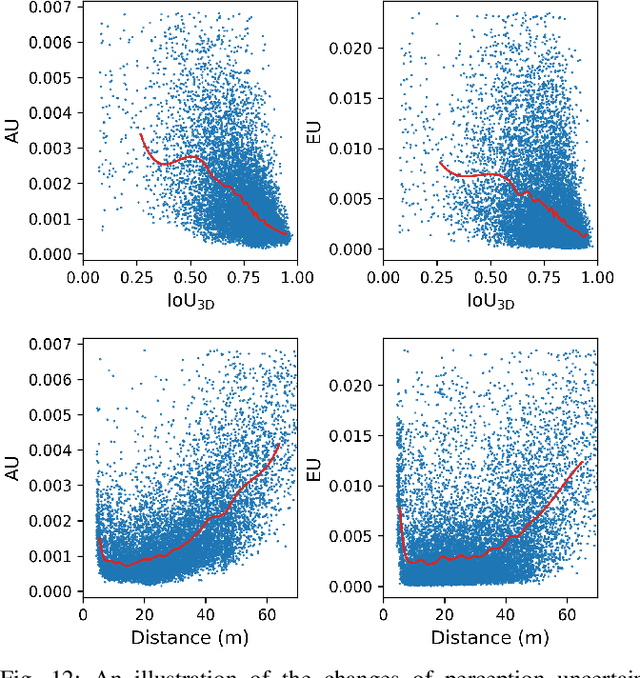
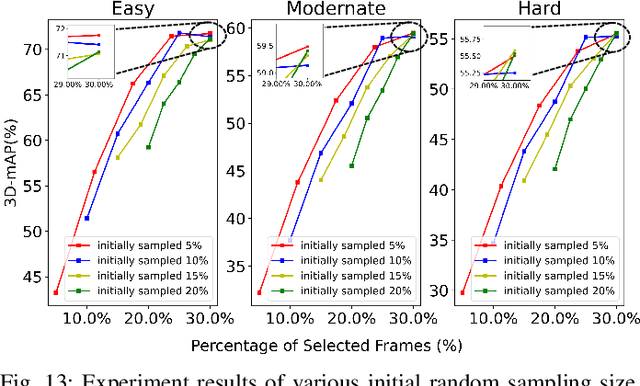
Most autonomous driving (AD) datasets incur substantial costs for collection and labeling, inevitably yielding a plethora of low-quality and redundant data instances, thereby compromising performance and efficiency. Many applications in AD systems necessitate high-quality training datasets using both existing datasets and newly collected data. In this paper, we propose a traffic scene joint active learning (TSceneJAL) framework that can efficiently sample the balanced, diverse, and complex traffic scenes from both labeled and unlabeled data. The novelty of this framework is threefold: 1) a scene sampling scheme based on a category entropy, to identify scenes containing multiple object classes, thus mitigating class imbalance for the active learner; 2) a similarity sampling scheme, estimated through the directed graph representation and a marginalize kernel algorithm, to pick sparse and diverse scenes; 3) an uncertainty sampling scheme, predicted by a mixture density network, to select instances with the most unclear or complex regression outcomes for the learner. Finally, the integration of these three schemes in a joint selection strategy yields an optimal and valuable subdataset. Experiments on the KITTI, Lyft, nuScenes and SUScape datasets demonstrate that our approach outperforms existing state-of-the-art methods on 3D object detection tasks with up to 12% improvements.
Is Precise Recovery Necessary? A Task-Oriented Imputation Approach for Time Series Forecasting on Variable Subset
Nov 15, 2024



Variable Subset Forecasting (VSF) refers to a unique scenario in multivariate time series forecasting, where available variables in the inference phase are only a subset of the variables in the training phase. VSF presents significant challenges as the entire time series may be missing, and neither inter- nor intra-variable correlations persist. Such conditions impede the effectiveness of traditional imputation methods, primarily focusing on filling in individual missing data points. Inspired by the principle of feature engineering that not all variables contribute positively to forecasting, we propose Task-Oriented Imputation for VSF (TOI-VSF), a novel framework shifts the focus from accurate data recovery to directly support the downstream forecasting task. TOI-VSF incorporates a self-supervised imputation module, agnostic to the forecasting model, designed to fill in missing variables while preserving the vital characteristics and temporal patterns of time series data. Additionally, we implement a joint learning strategy for imputation and forecasting, ensuring that the imputation process is directly aligned with and beneficial to the forecasting objective. Extensive experiments across four datasets demonstrate the superiority of TOI-VSF, outperforming baseline methods by $15\%$ on average.
SUSTechGAN: Image Generation for Object Recognition in Adverse Conditions of Autonomous Driving
Jul 18, 2024



Autonomous driving significantly benefits from data-driven deep neural networks. However, the data in autonomous driving typically fits the long-tailed distribution, in which the critical driving data in adverse conditions is hard to collect. Although generative adversarial networks (GANs) have been applied to augment data for autonomous driving, generating driving images in adverse conditions is still challenging. In this work, we propose a novel SUSTechGAN with dual attention modules and multi-scale generators to generate driving images for improving object recognition of autonomous driving in adverse conditions. We test the SUSTechGAN and the existing well-known GANs to generate driving images in adverse conditions of rain and night and apply the generated images to retrain object recognition networks. Specifically, we add generated images into the training datasets to retrain the well-known YOLOv5 and evaluate the improvement of the retrained YOLOv5 for object recognition in adverse conditions. The experimental results show that the generated driving images by our SUSTechGAN significantly improved the performance of retrained YOLOv5 in rain and night conditions, which outperforms the well-known GANs. The open-source code, video description and datasets are available on the page 1 to facilitate image generation development in autonomous driving under adverse conditions.
CTS: Sim-to-Real Unsupervised Domain Adaptation on 3D Detection
Jun 26, 2024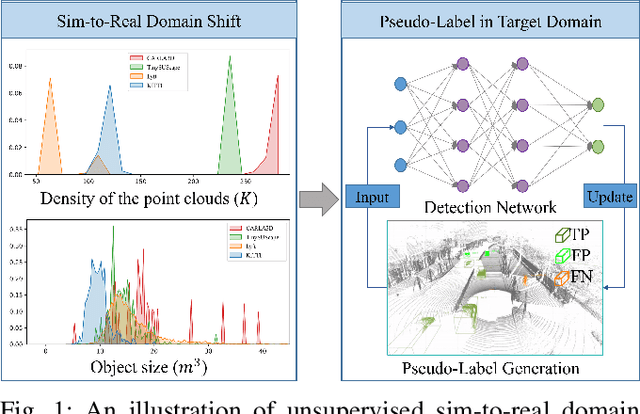
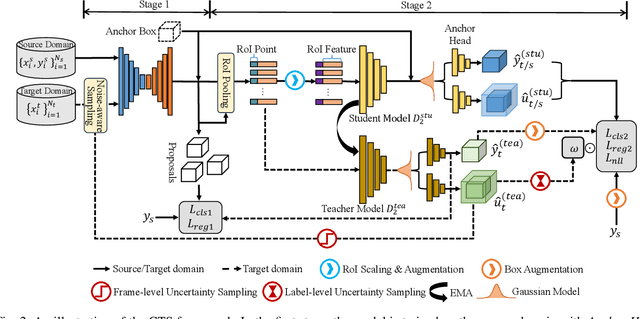
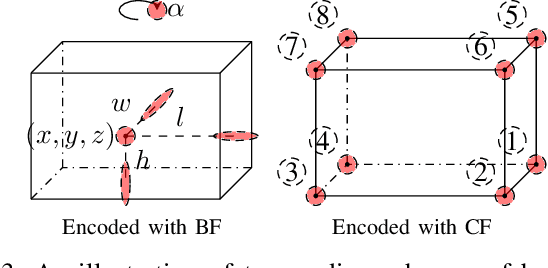
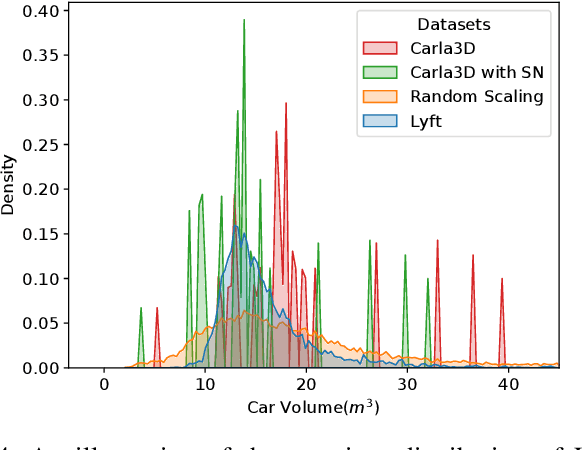
Simulation data can be accurately labeled and have been expected to improve the performance of data-driven algorithms, including object detection. However, due to the various domain inconsistencies from simulation to reality (sim-to-real), cross-domain object detection algorithms usually suffer from dramatic performance drops. While numerous unsupervised domain adaptation (UDA) methods have been developed to address cross-domain tasks between real-world datasets, progress in sim-to-real remains limited. This paper presents a novel Complex-to-Simple (CTS) framework to transfer models from labeled simulation (source) to unlabeled reality (target) domains. Based on a two-stage detector, the novelty of this work is threefold: 1) developing fixed-size anchor heads and RoI augmentation to address size bias and feature diversity between two domains, thereby improving the quality of pseudo-label; 2) developing a novel corner-format representation of aleatoric uncertainty (AU) for the bounding box, to uniformly quantify pseudo-label quality; 3) developing a noise-aware mean teacher domain adaptation method based on AU, as well as object-level and frame-level sampling strategies, to migrate the impact of noisy labels. Experimental results demonstrate that our proposed approach significantly enhances the sim-to-real domain adaptation capability of 3D object detection models, outperforming state-of-the-art cross-domain algorithms, which are usually developed for real-to-real UDA tasks.