 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Distributional Temporal Difference Learning with Linear Function Approximation
Nov 16, 2025
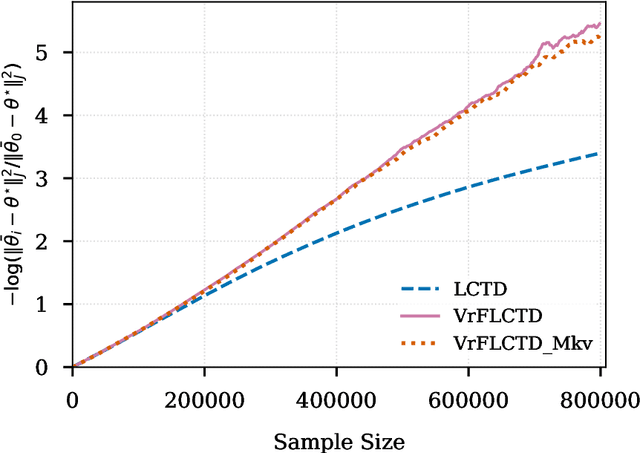
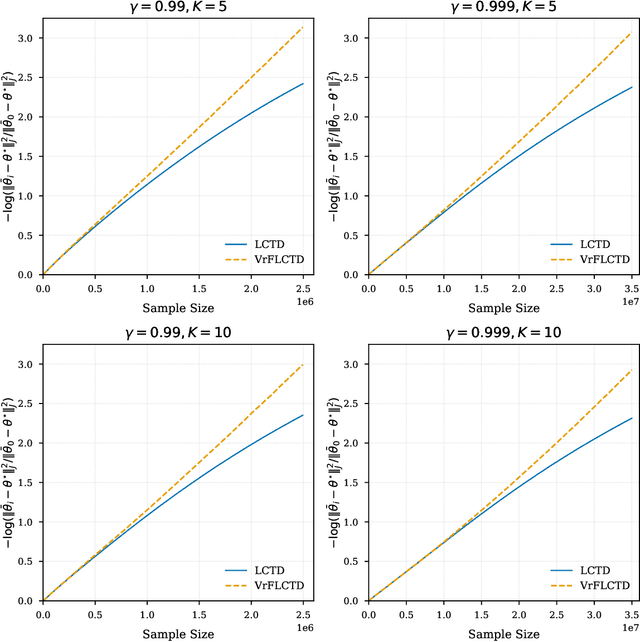
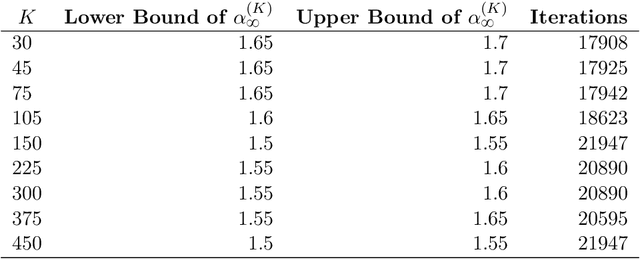
In this paper, we study the finite-sample statistical rates of distributional temporal difference (TD) learning with linear function approximation. The purpose of distributional TD learning is to estimate the return distribution of a discounted Markov decision process for a given policy. Previous works on statistical analysis of distributional TD learning focus mainly on the tabular case. We first consider the linear function approximation setting and conduct a fine-grained analysis of the linear-categorical Bellman equation. Building on this analysis, we further incorporate variance reduction techniques in our new algorithms to establish tight sample complexity bounds independent of the support size $K$ when $K$ is large. Our theoretical results imply that, when employing distributional TD learning with linear function approximation, learning the full distribution of the return function from streaming data is no more difficult than learning its expectation. This work provide new insights into the statistical efficiency of distributional reinforcement learning algorithms.
Finite Sample Analysis of Distributional TD Learning with Linear Function Approximation
Feb 20, 2025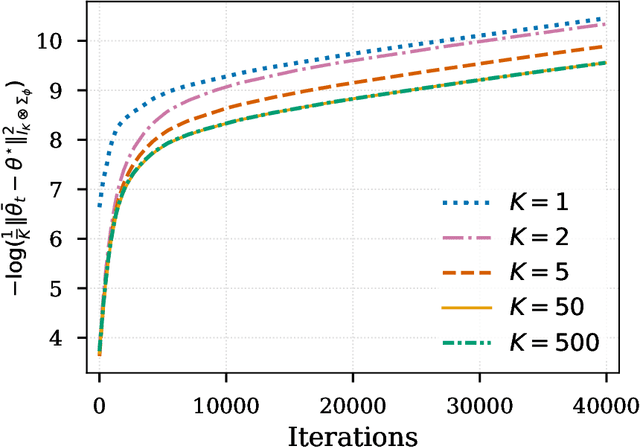


In this paper, we investigate the finite-sample statistical rates of distributional temporal difference (TD) learning with linear function approximation. The aim of distributional TD learning is to estimate the return distribution of a discounted Markov decision process for a given policy {\pi}. Prior works on statistical analysis of distributional TD learning mainly focus on the tabular case. In contrast, we first consider the linear function approximation setting and derive sharp finite-sample rates. Our theoretical results demonstrate that the sample complexity of linear distributional TD learning matches that of the classic linear TD learning. This implies that, with linear function approximation, learning the full distribution of the return using streaming data is no more difficult than learning its expectation (i.e. the value function). To derive tight sample complexity bounds, we conduct a fine-grained analysis of the linear-categorical Bellman equation, and employ the exponential stability arguments for products of random matrices. Our findings provide new insights into the statistical efficiency of distributional reinforcement learning algorithms.
SUSTechGAN: Image Generation for Object Recognition in Adverse Conditions of Autonomous Driving
Jul 18, 2024



Autonomous driving significantly benefits from data-driven deep neural networks. However, the data in autonomous driving typically fits the long-tailed distribution, in which the critical driving data in adverse conditions is hard to collect. Although generative adversarial networks (GANs) have been applied to augment data for autonomous driving, generating driving images in adverse conditions is still challenging. In this work, we propose a novel SUSTechGAN with dual attention modules and multi-scale generators to generate driving images for improving object recognition of autonomous driving in adverse conditions. We test the SUSTechGAN and the existing well-known GANs to generate driving images in adverse conditions of rain and night and apply the generated images to retrain object recognition networks. Specifically, we add generated images into the training datasets to retrain the well-known YOLOv5 and evaluate the improvement of the retrained YOLOv5 for object recognition in adverse conditions. The experimental results show that the generated driving images by our SUSTechGAN significantly improved the performance of retrained YOLOv5 in rain and night conditions, which outperforms the well-known GANs. The open-source code, video description and datasets are available on the page 1 to facilitate image generation development in autonomous driving under adverse conditions.
Federated Control in Markov Decision Processes
May 07, 2024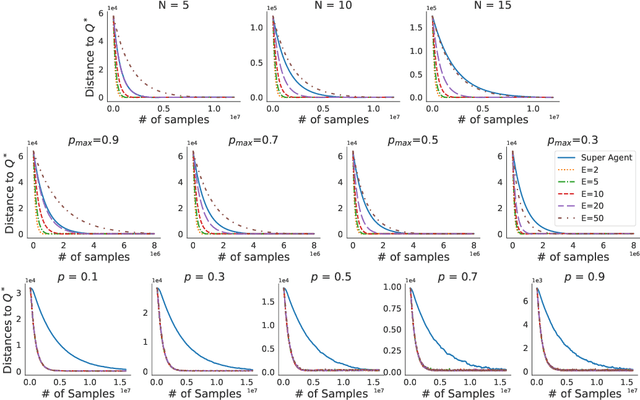
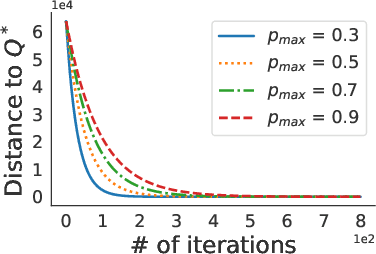
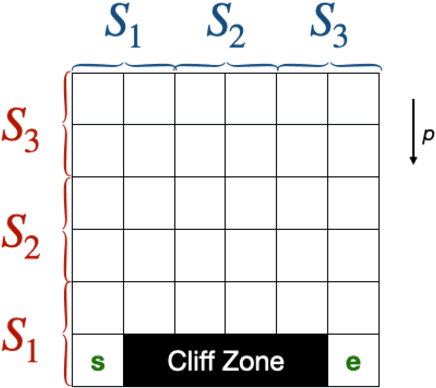
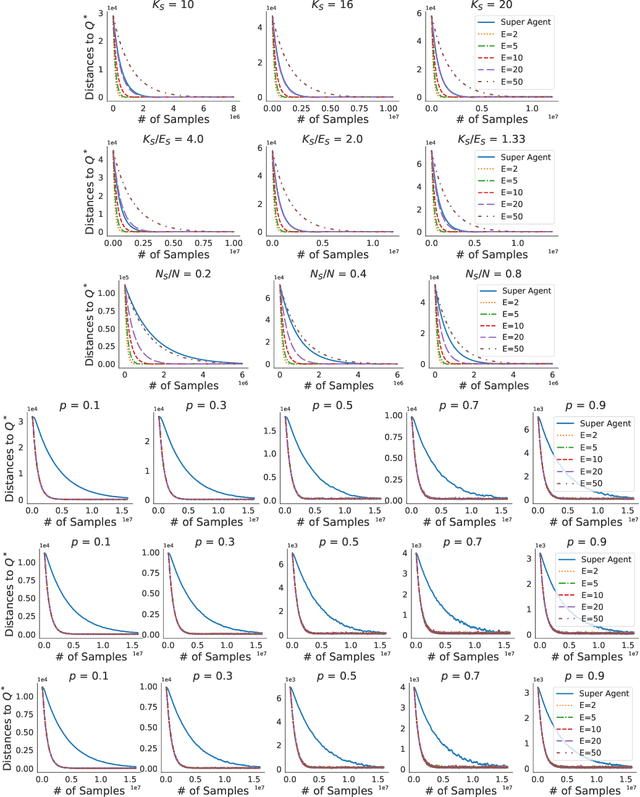
We study problems of federated control in Markov Decision Processes. To solve an MDP with large state space, multiple learning agents are introduced to collaboratively learn its optimal policy without communication of locally collected experience. In our settings, these agents have limited capabilities, which means they are restricted within different regions of the overall state space during the training process. In face of the difference among restricted regions, we firstly introduce concepts of leakage probabilities to understand how such heterogeneity affects the learning process, and then propose a novel communication protocol that we call Federated-Q protocol (FedQ), which periodically aggregates agents' knowledge of their restricted regions and accordingly modifies their learning problems for further training. In terms of theoretical analysis, we justify the correctness of FedQ as a communication protocol, then give a general result on sample complexity of derived algorithms FedQ-X with the RL oracle , and finally conduct a thorough study on the sample complexity of FedQ-SynQ. Specifically, FedQ-X has been shown to enjoy linear speedup in terms of sample complexity when workload is uniformly distributed among agents. Moreover, we carry out experiments in various environments to justify the efficiency of our methods.
Near Minimax-Optimal Distributional Temporal Difference Algorithms and The Freedman Inequality in Hilbert Spaces
Mar 14, 2024

Distributional reinforcement learning (DRL) has achieved empirical success in various domains. One of the core tasks in the field of DRL is distributional policy evaluation, which involves estimating the return distribution $\eta^\pi$ for a given policy $\pi$. The distributional temporal difference (TD) algorithm has been accordingly proposed, which is an extension of the temporal difference algorithm in the classic RL literature. In the tabular case, \citet{rowland2018analysis} and \citet{rowland2023analysis} proved the asymptotic convergence of two instances of distributional TD, namely categorical temporal difference algorithm (CTD) and quantile temporal difference algorithm (QTD), respectively. In this paper, we go a step further and analyze the finite-sample performance of distributional TD. To facilitate theoretical analysis, we propose a non-parametric distributional TD algorithm (NTD). For a $\gamma$-discounted infinite-horizon tabular Markov decision process, we show that for NTD we need $\tilde{O}\left(\frac{1}{\varepsilon^{2p}(1-\gamma)^{2p+1}}\right)$ iterations to achieve an $\varepsilon$-optimal estimator with high probability, when the estimation error is measured by the $p$-Wasserstein distance. This sample complexity bound is minimax optimal (up to logarithmic factors) in the case of the $1$-Wasserstein distance. To achieve this, we establish a novel Freedman's inequality in Hilbert spaces, which would be of independent interest. In addition, we revisit CTD, showing that the same non-asymptotic convergence bounds hold for CTD in the case of the $p$-Wasserstein distance.
Deep learning for 3D Object Detection and Tracking in Autonomous Driving: A Brief Survey
Nov 10, 2023



Object detection and tracking are vital and fundamental tasks for autonomous driving, aiming at identifying and locating objects from those predefined categories in a scene. 3D point cloud learning has been attracting more and more attention among all other forms of self-driving data. Currently, there are many deep learning methods for 3D object detection. However, the tasks of object detection and tracking for point clouds still need intensive study due to the unique characteristics of point cloud data. To help get a good grasp of the present situation of this research, this paper shows recent advances in deep learning methods for 3D object detection and tracking.
Estimation and Inference in Distributional Reinforcement Learning
Sep 29, 2023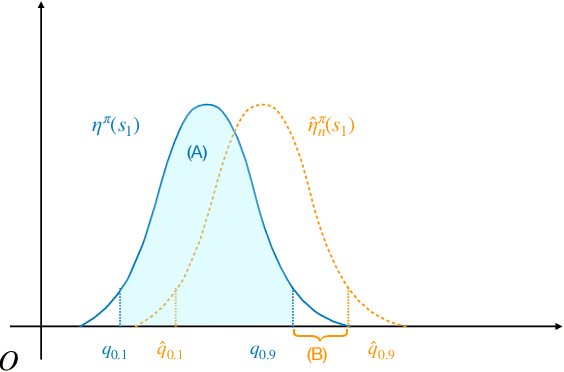

In this paper, we study distributional reinforcement learning from the perspective of statistical efficiency. We investigate distributional policy evaluation, aiming to estimate the complete distribution of the random return (denoted $\eta^\pi$) attained by a given policy $\pi$. We use the certainty-equivalence method to construct our estimator $\hat\eta^\pi$, given a generative model is available. We show that in this circumstance we need a dataset of size $\widetilde O\left(\frac{|\mathcal{S}||\mathcal{A}|}{\epsilon^{2p}(1-\gamma)^{2p+2}}\right)$ to guarantee a $p$-Wasserstein metric between $\hat\eta^\pi$ and $\eta^\pi$ is less than $\epsilon$ with high probability. This implies the distributional policy evaluation problem can be solved with sample efficiency. Also, we show that under different mild assumptions a dataset of size $\widetilde O\left(\frac{|\mathcal{S}||\mathcal{A}|}{\epsilon^{2}(1-\gamma)^{4}}\right)$ suffices to ensure the Kolmogorov metric and total variation metric between $\hat\eta^\pi$ and $\eta^\pi$ is below $\epsilon$ with high probability. Furthermore, we investigate the asymptotic behavior of $\hat\eta^\pi$. We demonstrate that the ``empirical process'' $\sqrt{n}(\hat\eta^\pi-\eta^\pi)$ converges weakly to a Gaussian process in the space of bounded functionals on Lipschitz function class $\ell^\infty(\mathcal{F}_{W_1})$, also in the space of bounded functionals on indicator function class $\ell^\infty(\mathcal{F}_{\mathrm{KS}})$ and bounded measurable function class $\ell^\infty(\mathcal{F}_{\mathrm{TV}})$ when some mild conditions hold. Our findings give rise to a unified approach to statistical inference of a wide class of statistical functionals of $\eta^\pi$.
BEA: Revisiting anchor-based object detection DNN using Budding Ensemble Architecture
Sep 19, 2023



This paper introduces the Budding Ensemble Architecture (BEA), a novel reduced ensemble architecture for anchor-based object detection models. Object detection models are crucial in vision-based tasks, particularly in autonomous systems. They should provide precise bounding box detections while also calibrating their predicted confidence scores, leading to higher-quality uncertainty estimates. However, current models may make erroneous decisions due to false positives receiving high scores or true positives being discarded due to low scores. BEA aims to address these issues. The proposed loss functions in BEA improve the confidence score calibration and lower the uncertainty error, which results in a better distinction of true and false positives and, eventually, higher accuracy of the object detection models. Both Base-YOLOv3 and SSD models were enhanced using the BEA method and its proposed loss functions. The BEA on Base-YOLOv3 trained on the KITTI dataset results in a 6% and 3.7% increase in mAP and AP50, respectively. Utilizing a well-balanced uncertainty estimation threshold to discard samples in real-time even leads to a 9.6% higher AP50 than its base model. This is attributed to a 40% increase in the area under the AP50-based retention curve used to measure the quality of calibration of confidence scores. Furthermore, BEA-YOLOV3 trained on KITTI provides superior out-of-distribution detection on Citypersons, BDD100K, and COCO datasets compared to the ensembles and vanilla models of YOLOv3 and Gaussian-YOLOv3.
Semi-Infinitely Constrained Markov Decision Processes and Efficient Reinforcement Learning
Apr 29, 2023


We propose a novel generalization of constrained Markov decision processes (CMDPs) that we call the \emph{semi-infinitely constrained Markov decision process} (SICMDP). Particularly, we consider a continuum of constraints instead of a finite number of constraints as in the case of ordinary CMDPs. We also devise two reinforcement learning algorithms for SICMDPs that we call SI-CRL and SI-CPO. SI-CRL is a model-based reinforcement learning algorithm. Given an estimate of the transition model, we first transform the reinforcement learning problem into a linear semi-infinitely programming (LSIP) problem and then use the dual exchange method in the LSIP literature to solve it. SI-CPO is a policy optimization algorithm. Borrowing the ideas from the cooperative stochastic approximation approach, we make alternative updates to the policy parameters to maximize the reward or minimize the cost. To the best of our knowledge, we are the first to apply tools from semi-infinitely programming (SIP) to solve constrained reinforcement learning problems. We present theoretical analysis for SI-CRL and SI-CPO, identifying their iteration complexity and sample complexity. We also conduct extensive numerical examples to illustrate the SICMDP model and demonstrate that our proposed algorithms are able to solve complex sequential decision-making tasks leveraging modern deep reinforcement learning techniques.
Finding Lookalike Customers for E-Commerce Marketing
Jan 09, 2023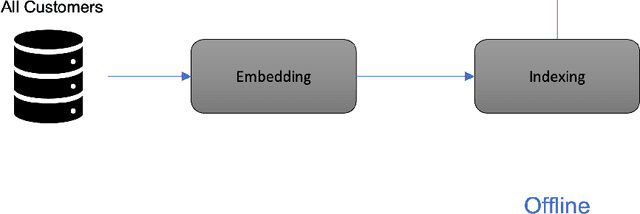

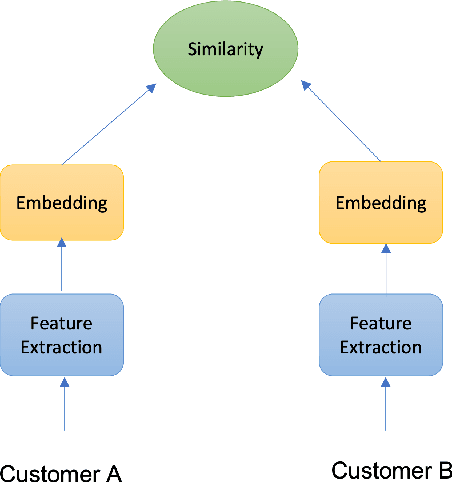

Customer-centric marketing campaigns generate a large portion of e-commerce website traffic for Walmart. As the scale of customer data grows larger, expanding the marketing audience to reach more customers is becoming more critical for e-commerce companies to drive business growth and bring more value to customers. In this paper, we present a scalable and efficient system to expand targeted audience of marketing campaigns, which can handle hundreds of millions of customers. We use a deep learning based embedding model to represent customers and an approximate nearest neighbor search method to quickly find lookalike customers of interest. The model can deal with various business interests by constructing interpretable and meaningful customer similarity metrics. We conduct extensive experiments to demonstrate the great performance of our system and customer embedding model.