 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitorBench: A Comprehensive Benchmark for Chain-of-Thought Monitorability in Large Language Models
Apr 02, 2026Large language models (LLMs) can generate chains of thought (CoTs) that are not always causally responsible for their final outputs. When such a mismatch occurs, the CoT no longer faithfully reflects the actual reasons (i.e., decision-critical factors) driving the model's behavior, leading to the reduced CoT monitorability problem. However, a comprehensive and fully open-source benchmark for thoroughly evaluating CoT monitorability remains lacking. To address this gap, we propose MonitorBench, a systematic benchmark for evaluating CoT monitorability in LLMs. MonitorBench provides: (1) a diverse set of 1,514 test instances with carefully designed decision-critical factors across 19 tasks spanning 7 categories to characterize \textit{when} CoTs can be used to monitor the factors driving LLM behavior; and (2) two stress-test settings to quantify \textit{the extent to which} CoT monitorability can be degraded. Extensive experiments across multiple popular LLMs with varying capabilities show that CoT monitorability is higher when the decision-critical factors shape the intermediate reasoning process without merely influencing the final answer. More capable LLMs tend to exhibit lower monitorability. And all evaluated LLMs can intentionally reduce monitorability under stress-tests, with monitorability dropping by up to 30\% in some tasks that do not require structural reasoning over the decision-critical factors. Overall, MonitorBench provides a basis for further research on evaluating future LLMs, studying advanced stress-test monitorability techniques, and developing new monitoring approaches. The code is available at https://github.com/ASTRAL-Group/MonitorBench.
RefReward-SR: LR-Conditioned Reward Modeling for Preference-Aligned Super-Resolution
Mar 25, 2026Recent advances in generative super-resolution (SR) have greatly improved visual realism, yet existing evaluation and optimization frameworks remain misaligned with human perception. Full-Reference and No-Reference metrics often fail to reflect perceptual preference, either penalizing semantically plausible details due to pixel misalignment or favoring visually sharp but inconsistent artifacts. Moreover, most SR methods rely on ground-truth (GT)-dependent distribution matching, which does not necessarily correspond to human judgments. In this work, we propose RefReward-SR, a low-resolution (LR) reference-aware reward model for preference-aligned SR. Instead of relying on GT supervision or NR evaluation, RefReward-SR assesses high-resolution (HR) reconstructions conditioned on their LR inputs, treating the LR image as a semantic anchor. Leveraging the visual-linguistic priors of a Multimodal Large Language Models (MLLM), it evaluates semantic consistency and plausibility in a reasoning-aware manner. To support this paradigm, we construct RefSR-18K, the first large-scale LR-conditioned preference dataset for SR, providing pairwise rankings based on LR-HR consistency and HR naturalness. We fine-tune the MLLM with Group Relative Policy Optimization (GRPO) using LR-conditioned ranking rewards, and further integrate GRPO into SR model training with RefReward-SR as the core reward signal for preference-aligned generation. Extensive experiments show that our framework achieves substantially better alignment with human judgments, producing reconstructions that preserve semantic consistency while enhancing perceptual plausibility and visual naturalness. Code, models, and datasets will be released upon paper acceptance.
Text-Image Conditioned 3D Generation
Mar 22, 2026High-quality 3D assets are essential for VR/AR, industrial design, and entertainment, motivating growing interest in generative models that create 3D content from user prompts. Most existing 3D generators, however, rely on a single conditioning modality: image-conditioned models achieve high visual fidelity by exploiting pixel-aligned cues but suffer from viewpoint bias when the input view is limited or ambiguous, while text-conditioned models provide broad semantic guidance yet lack low-level visual detail. This limits how users can express intent and raises a natural question: can these two modalities be combined for more flexible and faithful 3D generation? Our diagnostic study shows that even simple late fusion of text- and image-conditioned predictions outperforms single-modality models, revealing strong cross-modal complementarity. We therefore formalize Text-Image Conditioned 3D Generation, which requires joint reasoning over a visual exemplar and a textual specification. To address this task, we introduce TIGON, a minimalist dual-branch baseline with separate image- and text-conditioned backbones and lightweight cross-modal fusion. Extensive experiments show that text-image conditioning consistently improves over single-modality methods, highlighting complementary vision-language guidance as a promising direction for future 3D generation research. Project page: https://jumpat.github.io/tigon-page
CodePercept: Code-Grounded Visual STEM Perception for MLLMs
Mar 11, 2026When MLLMs fail at Science, Technology, Engineering, and Mathematics (STEM) visual reasoning, a fundamental question arises: is it due to perceptual deficiencies or reasoning limitations? Through systematic scaling analysis that independently scales perception and reasoning components, we uncover a critical insight: scaling perception consistently outperforms scaling reasoning. This reveals perception as the true lever limiting current STEM visual reasoning. Motivated by this insight, our work focuses on systematically enhancing the perception capabilities of MLLMs by establishing code as a powerful perceptual medium--executable code provides precise semantics that naturally align with the structured nature of STEM visuals. Specifically, we construct ICC-1M, a large-scale dataset comprising 1M Image-Caption-Code triplets that materializes this code-as-perception paradigm through two complementary approaches: (1) Code-Grounded Caption Generation treats executable code as ground truth for image captions, eliminating the hallucinations inherent in existing knowledge distillation methods; (2) STEM Image-to-Code Translation prompts models to generate reconstruction code, mitigating the ambiguity of natural language for perception enhancement. To validate this paradigm, we further introduce STEM2Code-Eval, a novel benchmark that directly evaluates visual perception in STEM domains. Unlike existing work relying on problem-solving accuracy as a proxy that only measures problem-relevant understanding, our benchmark requires comprehensive visual comprehension through executable code generation for image reconstruction, providing deterministic and verifiable assessment. Code is available at https://github.com/TongkunGuan/Qwen-CodePercept.
SkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
Thinking Like a Radiologist: A Dataset for Anatomy-Guided Interleaved Vision Language Reasoning in Chest X-ray Interpretation
Feb 13, 2026Radiological diagnosis is a perceptual process in which careful visual inspection and language reasoning are repeatedly interleaved. Most medical large vision language models (LVLMs) perform visual inspection only once and then rely on text-only chain-of-thought (CoT) reasoning, which operates purely in the linguistic space and is prone to hallucination. Recent methods attempt to mitigate this issue by introducing visually related coordinates, such as bounding boxes. However, these remain a pseudo-visual solution: coordinates are still text and fail to preserve rich visual details like texture and density. Motivated by the interleaved nature of radiological diagnosis, we introduce MMRad-IVL-22K, the first large-scale dataset designed for natively interleaved visual language reasoning in chest X-ray interpretation. MMRad-IVL-22K reflects a repeated cycle of reasoning and visual inspection workflow of radiologists, in which visual rationales complement textual descriptions and ground each step of the reasoning process. MMRad-IVL-22K comprises 21,994 diagnostic traces, enabling systematic scanning across 35 anatomical regions. Experimental results on advanced closed-source LVLMs demonstrate that report generation guided by multimodal CoT significantly outperforms that guided by text-only CoT in clinical accuracy and report quality (e.g., 6\% increase in the RadGraph metric), confirming that high-fidelity interleaved vision language evidence is a non-substitutable component of reliable medical AI. Furthermore, benchmarking across seven state-of-the-art open-source LVLMs demonstrates that models fine-tuned on MMRad-IVL-22K achieve superior reasoning consistency and report quality compared with both general-purpose and medical-specific LVLMs. The project page is available at https://github.com/qiuzyc/thinking_like_a_radiologist.
Beyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
Jan 01, 2026We introduce WildAGTEval, a benchmark designed to evaluate large language model (LLM) agents' function-calling capabilities under realistic API complexity. Unlike prior work that assumes an idealized API system and disregards real-world factors such as noisy API outputs, WildAGTEval accounts for two dimensions of real-world complexity: 1. API specification, which includes detailed documentation and usage constraints, and 2. API execution, which captures runtime challenges. Consequently, WildAGTEval offers (i) an API system encompassing 60 distinct complexity scenarios that can be composed into approximately 32K test configurations, and (ii) user-agent interactions for evaluating LLM agents on these scenarios. Using WildAGTEval, we systematically assess several advanced LLMs and observe that most scenarios are challenging, with irrelevant information complexity posing the greatest difficulty and reducing the performance of strong LLMs by 27.3%. Furthermore, our qualitative analysis reveals that LLMs occasionally distort user intent merely to claim task completion, critically affecting user satisfaction.
Generative Human-Object Interaction Detection via Differentiable Cognitive Steering of Multi-modal LLMs
Dec 19, 2025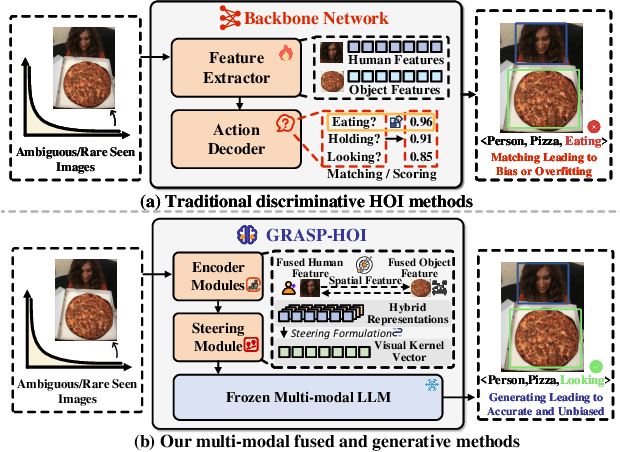
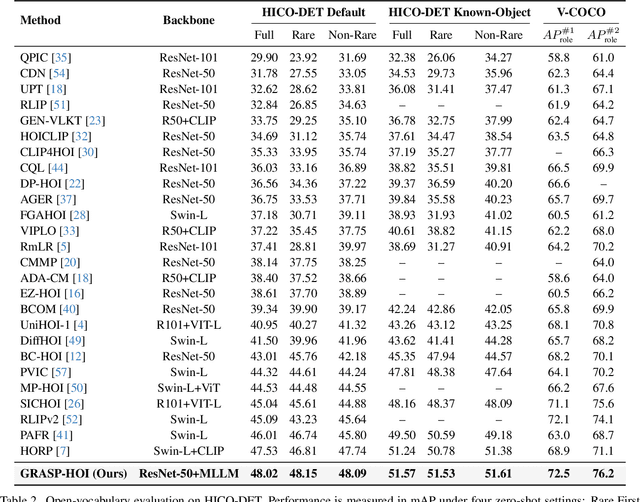
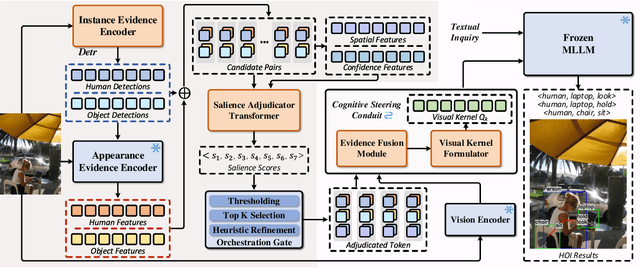
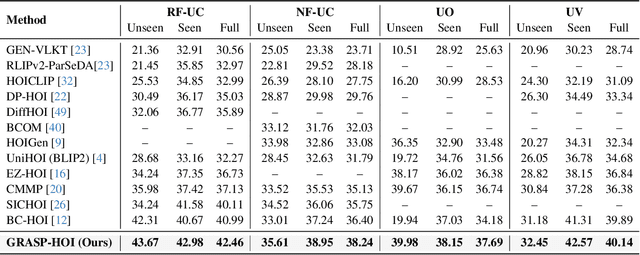
Human-object interaction (HOI) detection aims to localize human-object pairs and the interactions between them. Existing methods operate under a closed-world assumption, treating the task as a classification problem over a small, predefined verb set, which struggles to generalize to the long-tail of unseen or ambiguous interactions in the wild. While recent multi-modal large language models (MLLMs) possess the rich world knowledge required for open-vocabulary understanding, they remain decoupled from existing HOI detectors since fine-tuning them is computationally prohibitive. To address these constraints, we propose \GRASP-HO}, a novel Generative Reasoning And Steerable Perception framework that reformulates HOI detection from the closed-set classification task to the open-vocabulary generation problem. To bridge the vision and cognitive, we first extract hybrid interaction representations, then design a lightweight learnable cognitive steering conduit (CSC) module to inject the fine-grained visual evidence into a frozen MLLM for effective reasoning. To address the supervision mismatch between classification-based HOI datasets and open-vocabulary generative models, we introduce a hybrid guidance strategy that coupling the language modeling loss and auxiliary classification loss, enabling discriminative grounding without sacrificing generative flexibility. Experiments demonstrate state-of-the-art closed-set performance and strong zero-shot generalization, achieving a unified paradigm that seamlessly bridges discriminative perception and generative reasoning for open-world HOI detection.
WorldGrow: Generating Infinite 3D World
Oct 24, 2025



We tackle the challenge of generating the infinitely extendable 3D world -- large, continuous environments with coherent geometry and realistic appearance. Existing methods face key challenges: 2D-lifting approaches suffer from geometric and appearance inconsistencies across views, 3D implicit representations are hard to scale up, and current 3D foundation models are mostly object-centric, limiting their applicability to scene-level generation. Our key insight is leveraging strong generation priors from pre-trained 3D models for structured scene block generation. To this end, we propose WorldGrow, a hierarchical framework for unbounded 3D scene synthesis. Our method features three core components: (1) a data curation pipeline that extracts high-quality scene blocks for training, making the 3D structured latent representations suitable for scene generation; (2) a 3D block inpainting mechanism that enables context-aware scene extension; and (3) a coarse-to-fine generation strategy that ensures both global layout plausibility and local geometric/textural fidelity. Evaluated on the large-scale 3D-FRONT dataset, WorldGrow achieves SOTA performance in geometry reconstruction, while uniquely supporting infinite scene generation with photorealistic and structurally consistent outputs. These results highlight its capability for constructing large-scale virtual environments and potential for building future world models.
Few-step Flow for 3D Generation via Marginal-Data Transport Distillation
Sep 04, 2025Flow-based 3D generation models typically require dozens of sampling steps during inference. Though few-step distillation methods, particularly Consistency Models (CMs), have achieved substantial advancements in accelerating 2D diffusion models, they remain under-explored for more complex 3D generation tasks. In this study, we propose a novel framework, MDT-dist, for few-step 3D flow distillation. Our approach is built upon a primary objective: distilling the pretrained model to learn the Marginal-Data Transport. Directly learning this objective needs to integrate the velocity fields, while this integral is intractable to be implemented. Therefore, we propose two optimizable objectives, Velocity Matching (VM) and Velocity Distillation (VD), to equivalently convert the optimization target from the transport level to the velocity and the distribution level respectively. Velocity Matching (VM) learns to stably match the velocity fields between the student and the teacher, but inevitably provides biased gradient estimates. Velocity Distillation (VD) further enhances the optimization process by leveraging the learned velocity fields to perform probability density distillation. When evaluated on the pioneer 3D generation framework TRELLIS, our method reduces sampling steps of each flow transformer from 25 to 1 or 2, achieving 0.68s (1 step x 2) and 0.94s (2 steps x 2) latency with 9.0x and 6.5x speedup on A800, while preserving high visual and geometric fidelity. Extensive experiments demonstrate that our method significantly outperforms existing CM distillation methods, and enables TRELLIS to achieve superior performance in few-step 3D generation.