 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Apr 13, 2026With the advancement of interactive video generation, diffusion models have increasingly demonstrated their potential as world models. However, existing approaches still struggle to simultaneously achieve memory-enabled long-term temporal consistency and high-resolution real-time generation, limiting their applicability in real-world scenarios. To address this, we present Matrix-Game 3.0, a memory-augmented interactive world model designed for 720p real-time longform video generation. Building upon Matrix-Game 2.0, we introduce systematic improvements across data, model, and inference. First, we develop an upgraded industrial-scale infinite data engine that integrates Unreal Engine-based synthetic data, large-scale automated collection from AAA games, and real-world video augmentation to produce high-quality Video-Pose-Action-Prompt quadruplet data at scale. Second, we propose a training framework for long-horizon consistency: by modeling prediction residuals and re-injecting imperfect generated frames during training, the base model learns self-correction; meanwhile, camera-aware memory retrieval and injection enable the base model to achieve long horizon spatiotemporal consistency. Third, we design a multi-segment autoregressive distillation strategy based on Distribution Matching Distillation (DMD), combined with model quantization and VAE decoder pruning, to achieve efficient real-time inference. Experimental results show that Matrix-Game 3.0 achieves up to 40 FPS real-time generation at 720p resolution with a 5B model, while maintaining stable memory consistency over minute-long sequences. Scaling up to a 2x14B model further improves generation quality, dynamics, and generalization. Our approach provides a practical pathway toward industrial-scale deployable world models.
TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas
Mar 17, 2026Text-to-SQL parsing has achieved remarkable progress under the Full Schema Assumption. However, this premise fails in real-world enterprise environments where databases contain hundreds of tables with massive noisy metadata. Rather than injecting the full schema upfront, an agent must actively identify and verify only the relevant subset, giving rise to the Unknown Schema scenario we study in this work. To address this, we propose TRUST-SQL (Truthful Reasoning with Unknown Schema via Tools). We formulate the task as a Partially Observable Markov Decision Process where our autonomous agent employs a structured four-phase protocol to ground reasoning in verified metadata. Crucially, this protocol provides a structural boundary for our novel Dual-Track GRPO strategy. By applying token-level masked advantages, this strategy isolates exploration rewards from execution outcomes to resolve credit assignment, yielding a 9.9% relative improvement over standard GRPO. Extensive experiments across five benchmarks demonstrate that TRUST-SQL achieves an average absolute improvement of 30.6% and 16.6% for the 4B and 8B variants respectively over their base models. Remarkably, despite operating entirely without pre-loaded metadata, our framework consistently matches or surpasses strong baselines that rely on schema prefilling.
Skywork-R1V3 Technical Report
Jul 09, 2025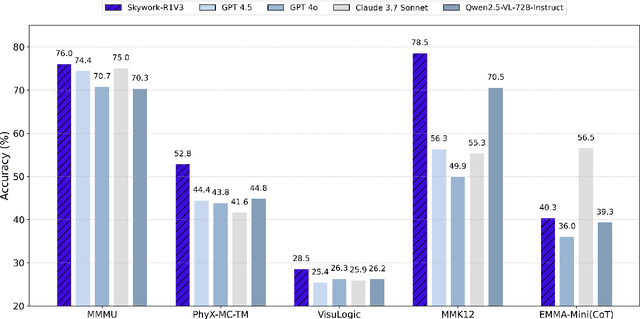
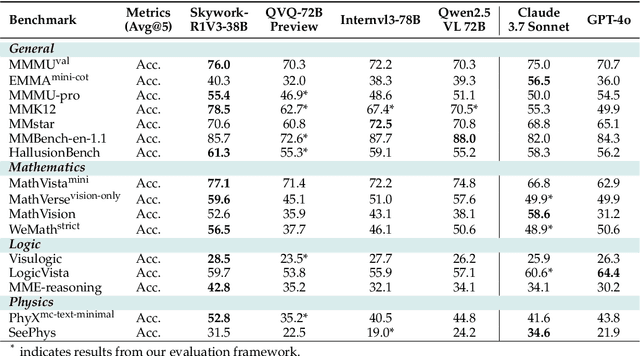
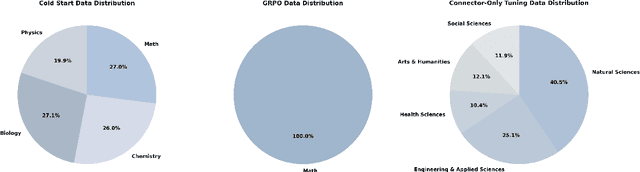

We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model's reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
CSVQA: A Chinese Multimodal Benchmark for Evaluating STEM Reasoning Capabilities of VLMs
May 30, 2025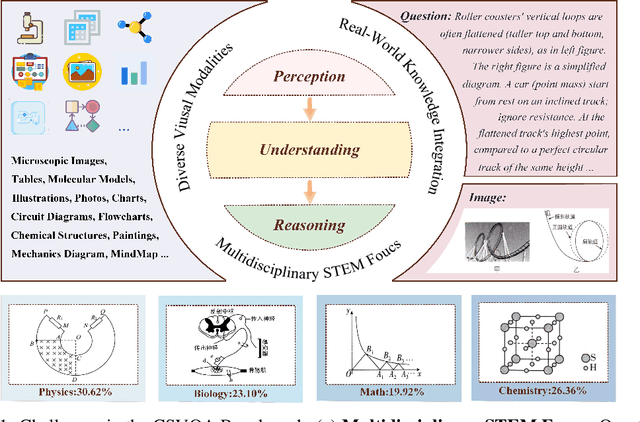
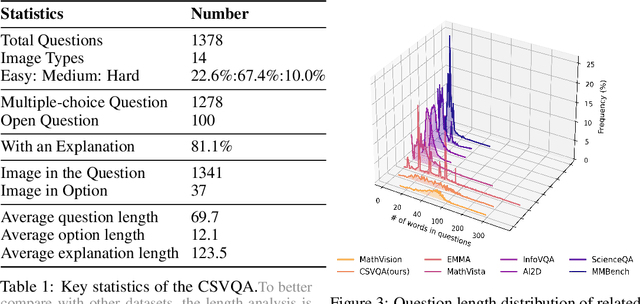
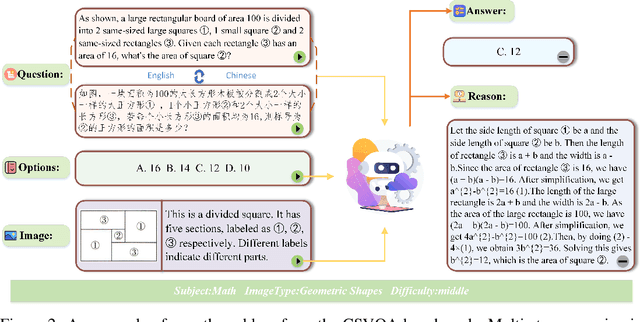
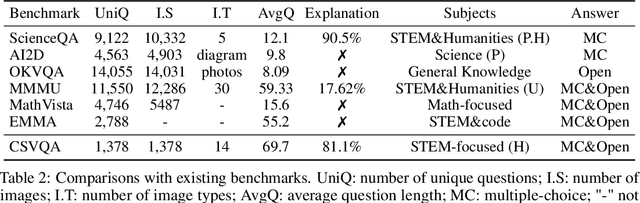
Vision-Language Models (VLMs) have demonstrated remarkable progress in multimodal understanding, yet their capabilities for scientific reasoning remains inadequately assessed. Current multimodal benchmarks predominantly evaluate generic image comprehension or text-driven reasoning, lacking authentic scientific contexts that require domain-specific knowledge integration with visual evidence analysis. To fill this gap, we present CSVQA, a diagnostic multimodal benchmark specifically designed for evaluating scientific reasoning through domain-grounded visual question answering.Our benchmark features 1,378 carefully constructed question-answer pairs spanning diverse STEM disciplines, each demanding domain knowledge, integration of visual evidence, and higher-order reasoning. Compared to prior multimodal benchmarks, CSVQA places greater emphasis on real-world scientific content and complex reasoning.We additionally propose a rigorous evaluation protocol to systematically assess whether model predictions are substantiated by valid intermediate reasoning steps based on curated explanations. Our comprehensive evaluation of 15 VLMs on this benchmark reveals notable performance disparities, as even the top-ranked proprietary model attains only 49.6\% accuracy.This empirical evidence underscores the pressing need for advancing scientific reasoning capabilities in VLMs. Our CSVQA is released at https://huggingface.co/datasets/Skywork/CSVQA.
Skywork-VL Reward: An Effective Reward Model for Multimodal Understanding and Reasoning
May 12, 2025We propose Skywork-VL Reward, a multimodal reward model that provides reward signals for both multimodal understanding and reasoning tasks. Our technical approach comprises two key components: First, we construct a large-scale multimodal preference dataset that covers a wide range of tasks and scenarios, with responses collected from both standard vision-language models (VLMs) and advanced VLM reasoners. Second, we design a reward model architecture based on Qwen2.5-VL-7B-Instruct, integrating a reward head and applying multi-stage fine-tuning using pairwise ranking loss on pairwise preference data. Experimental evaluations show that Skywork-VL Reward achieves state-of-the-art results on multimodal VL-RewardBench and exhibits competitive performance on the text-only RewardBench benchmark. Furthermore, preference data constructed based on our Skywork-VL Reward proves highly effective for training Mixed Preference Optimization (MPO), leading to significant improvements in multimodal reasoning capabilities. Our results underscore Skywork-VL Reward as a significant advancement toward general-purpose, reliable reward models for multimodal alignment. Our model has been publicly released to promote transparency and reproducibility.
Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Apr 23, 2025We present Skywork R1V2, a next-generation multimodal reasoning model and a major leap forward from its predecessor, Skywork R1V. At its core, R1V2 introduces a hybrid reinforcement learning paradigm that harmonizes reward-model guidance with rule-based strategies, thereby addressing the long-standing challenge of balancing sophisticated reasoning capabilities with broad generalization. To further enhance training efficiency, we propose the Selective Sample Buffer (SSB) mechanism, which effectively counters the ``Vanishing Advantages'' dilemma inherent in Group Relative Policy Optimization (GRPO) by prioritizing high-value samples throughout the optimization process. Notably, we observe that excessive reinforcement signals can induce visual hallucinations--a phenomenon we systematically monitor and mitigate through calibrated reward thresholds throughout the training process. Empirical results affirm the exceptional capability of R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in closing the performance gap with premier proprietary systems, including Gemini 2.5 and OpenAI o4-mini. The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility https://huggingface.co/Skywork/Skywork-R1V2-38B.
Skywork R1V: Pioneering Multimodal Reasoning with Chain-of-Thought
Apr 08, 2025We introduce Skywork R1V, a multimodal reasoning model extending the an R1-series Large language models (LLM) to visual modalities via an efficient multimodal transfer method. Leveraging a lightweight visual projector, Skywork R1V facilitates seamless multimodal adaptation without necessitating retraining of either the foundational language model or the vision encoder. To strengthen visual-text alignment, we propose a hybrid optimization strategy that combines Iterative Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), significantly enhancing cross-modal integration efficiency. Additionally, we introduce an adaptive-length Chain-of-Thought distillation approach for reasoning data generation. This approach dynamically optimizes reasoning chain lengths, thereby enhancing inference efficiency and preventing excessive reasoning overthinking. Empirical evaluations demonstrate that Skywork R1V, with only 38B parameters, delivers competitive performance, achieving a score of 69.0 on the MMMU benchmark and 67.5 on MathVista. Meanwhile, it maintains robust textual reasoning performance, evidenced by impressive scores of 72.0 on AIME and 94.0 on MATH500. The Skywork R1V model weights have been publicly released to promote openness and reproducibility.
Camera-Invariant Meta-Learning Network for Single-Camera-Training Person Re-identification
Jun 21, 2024Single-camera-training person re-identification (SCT re-ID) aims to train a re-ID model using SCT datasets where each person appears in only one camera. The main challenge of SCT re-ID is to learn camera-invariant feature representations without cross-camera same-person (CCSP) data as supervision. Previous methods address it by assuming that the most similar person should be found in another camera. However, this assumption is not guaranteed to be correct. In this paper, we propose a Camera-Invariant Meta-Learning Network (CIMN) for SCT re-ID. CIMN assumes that the camera-invariant feature representations should be robust to camera changes. To this end, we split the training data into meta-train set and meta-test set based on camera IDs and perform a cross-camera simulation via meta-learning strategy, aiming to enforce the representations learned from the meta-train set to be robust to the meta-test set. With the cross-camera simulation, CIMN can learn camera-invariant and identity-discriminative representations even there are no CCSP data. However, this simulation also causes the separation of the meta-train set and the meta-test set, which ignores some beneficial relations between them. Thus, we introduce three losses: meta triplet loss, meta classification loss, and meta camera alignment loss, to leverage the ignored relations. The experiment results demonstrate that our method achieves comparable performance with and without CCSP data, and outperforms the state-of-the-art methods on SCT re-ID benchmarks. In addition, it is also effective in improving the domain generalization ability of the model.
On the Model-Agnostic Multi-Source-Free Unsupervised Domain Adaptation
Mar 03, 2024Multi-Source-Free Unsupervised Domain Adaptation (MSFDA) aims to transfer knowledge from multiple well-labeled source domains to an unlabeled target domain, using source models instead of source data. Existing MSFDA methods limited that each source domain provides only a single model, with a uniform structure. This paper introduces a new MSFDA setting: Model-Agnostic Multi-Source-Free Unsupervised Domain Adaptation (MMDA), allowing diverse source models with varying architectures, without quantitative restrictions. While MMDA holds promising potential, incorporating numerous source models poses a high risk of including undesired models, which highlights the source model selection problem. To address it, we first provide a theoretical analysis of this problem. We reveal two fundamental selection principles: transferability principle and diversity principle, and introduce a selection algorithm to integrate them. Then, considering the measure of transferability is challenging, we propose a novel Source-Free Unsupervised Transferability Estimation (SUTE). This novel formulation enables the assessment and comparison of transferability across multiple source models with different architectures in the context of domain shift, without requiring access to any target labels or source data. Based on the above, we introduce a new framework to address MMDA. Specifically, we first conduct source model selection based on the proposed selection principles. Subsequently, we design two modules to aggregate knowledge from included models and recycle useful knowledge from excluded models. These modules enable us to leverage source knowledge efficiently and effectively, thereby supporting us in learning a discriminative target model via adaptation. We validate the effectiveness of our method through numerous experimental results, and demonstrate that our approach achieves state-of-the-art performance.
Uncertainty-Induced Transferability Representation for Source-Free Unsupervised Domain Adaptation
Aug 30, 2022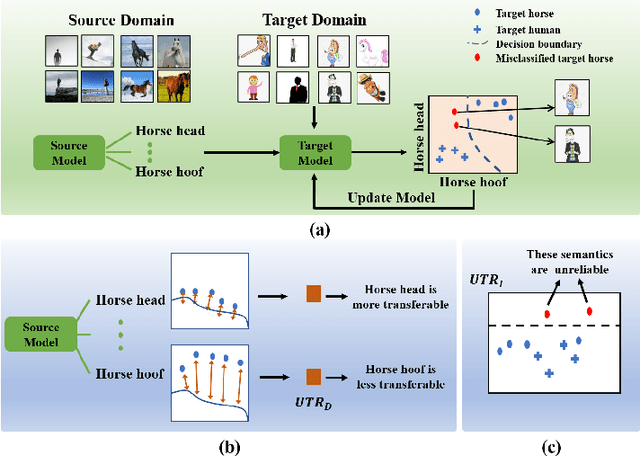


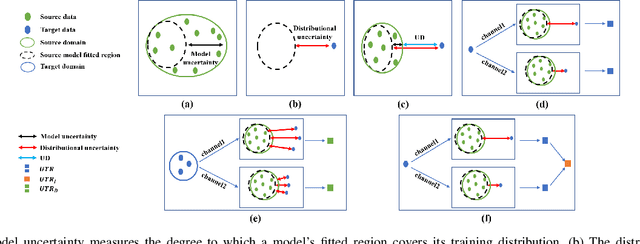
Source-free unsupervised domain adaptation (SFUDA) aims to learn a target domain model using unlabeled target data and the knowledge of a well-trained source domain model. Most previous SFUDA works focus on inferring semantics of target data based on the source knowledge. Without measuring the transferability of the source knowledge, these methods insufficiently exploit the source knowledge, and fail to identify the reliability of the inferred target semantics. However, existing transferability measurements require either source data or target labels, which are infeasible in SFUDA. To this end, firstly, we propose a novel Uncertainty-induced Transferability Representation (UTR), which leverages uncertainty as the tool to analyse the channel-wise transferability of the source encoder in the absence of the source data and target labels. The domain-level UTR unravels how transferable the encoder channels are to the target domain and the instance-level UTR characterizes the reliability of the inferred target semantics. Secondly, based on the UTR, we propose a novel Calibrated Adaption Framework (CAF) for SFUDA, including i)the source knowledge calibration module that guides the target model to learn the transferable source knowledge and discard the non-transferable one, and ii)the target semantics calibration module that calibrates the unreliable semantics. With the help of the calibrated source knowledge and the target semantics, the model adapts to the target domain safely and ultimately better. We verified the effectiveness of our method using experimental results and demonstrated that the proposed method achieves state-of-the-art performances on the three SFUDA benchmarks. Code is available at https://github.com/SPIresearch/UTR.