 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Centric Robust Monocular Depth Estimation via Knowledge Distillation
Oct 09, 2024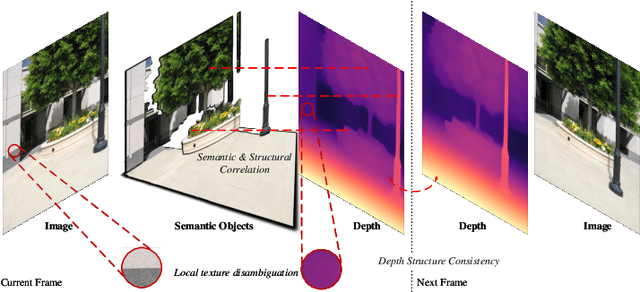
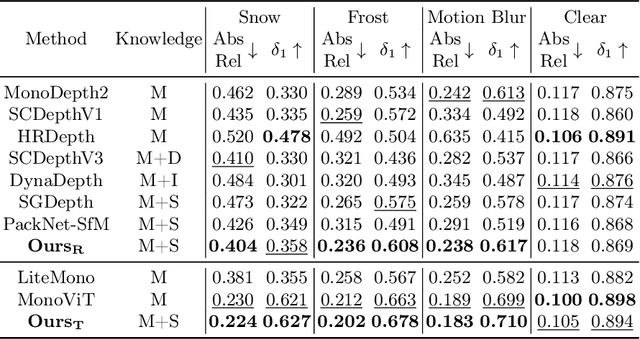
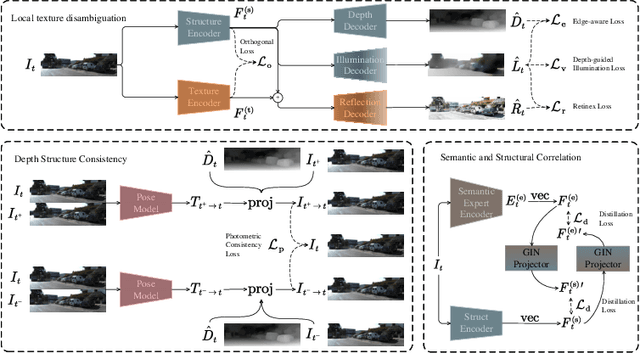
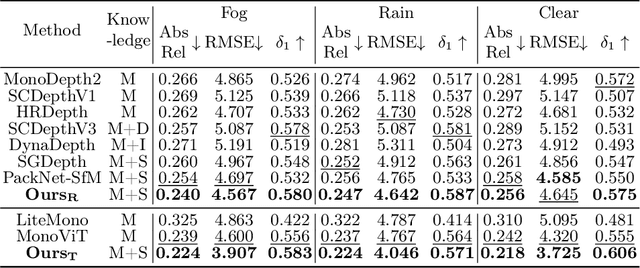
Monocular depth estimation, enabled by self-supervised learning, is a key technique for 3D perception in computer vision. However, it faces significant challenges in real-world scenarios, which encompass adverse weather variations, motion blur, as well as scenes with poor lighting conditions at night. Our research reveals that we can divide monocular depth estimation into three sub-problems: depth structure consistency, local texture disambiguation, and semantic-structural correlation. Our approach tackles the non-robustness of existing self-supervised monocular depth estimation models to interference textures by adopting a structure-centered perspective and utilizing the scene structure characteristics demonstrated by semantics and illumination. We devise a novel approach to reduce over-reliance on local textures, enhancing robustness against missing or interfering patterns. Additionally, we incorporate a semantic expert model as the teacher and construct inter-model feature dependencies via learnable isomorphic graphs to enable aggregation of semantic structural knowledge. Our approach achieves state-of-the-art out-of-distribution monocular depth estimation performance across a range of public adverse scenario datasets. It demonstrates notable scalability and compatibility, without necessitating extensive model engineering. This showcases the potential for customizing models for diverse industrial applications.
CSS: Overcoming Pose and Scene Challenges in Crowd-Sourced 3D Gaussian Splatting
Sep 13, 2024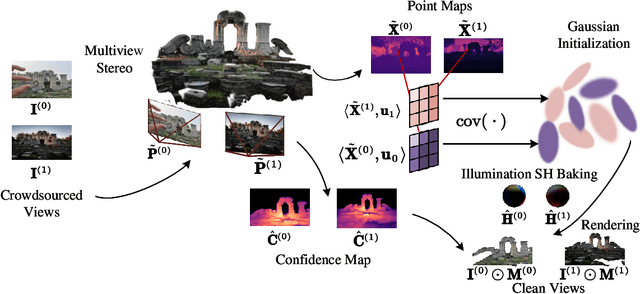

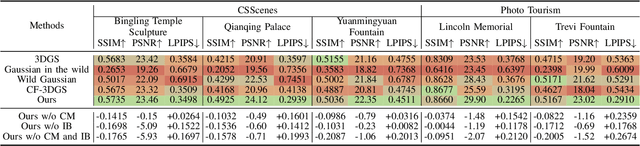
We introduce Crowd-Sourced Splatting (CSS), a novel 3D Gaussian Splatting (3DGS) pipeline designed to overcome the challenges of pose-free scene reconstruction using crowd-sourced imagery. The dream of reconstructing historically significant but inaccessible scenes from collections of photographs has long captivated researchers. However, traditional 3D techniques struggle with missing camera poses, limited viewpoints, and inconsistent lighting. CSS addresses these challenges through robust geometric priors and advanced illumination modeling, enabling high-quality novel view synthesis under complex, real-world conditions. Our method demonstrates clear improvements over existing approaches, paving the way for more accurate and flexible applications in AR, VR, and large-scale 3D reconstruction.
Map-Free Visual Relocalization Enhanced by Instance Knowledge and Depth Knowledge
Aug 23, 2024
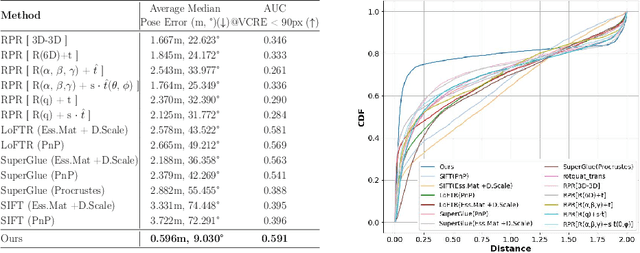
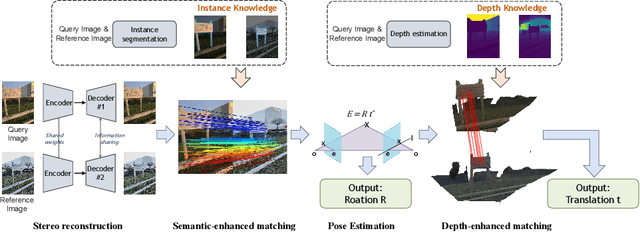

Map-free relocalization technology is crucial for applications in autonomous navigation and augmented reality, but relying on pre-built maps is often impractical. It faces significant challenges due to limitations in matching methods and the inherent lack of scale in monocular images. These issues lead to substantial rotational and metric errors and even localization failures in real-world scenarios. Large matching errors significantly impact the overall relocalization process, affecting both rotational and translational accuracy. Due to the inherent limitations of the camera itself, recovering the metric scale from a single image is crucial, as this significantly impacts the translation error. To address these challenges, we propose a map-free relocalization method enhanced by instance knowledge and depth knowledge. By leveraging instance-based matching information to improve global matching results, our method significantly reduces the possibility of mismatching across different objects. The robustness of instance knowledge across the scene helps the feature point matching model focus on relevant regions and enhance matching accuracy. Additionally, we use estimated metric depth from a single image to reduce metric errors and improve scale recovery accuracy. By integrating methods dedicated to mitigating large translational and rotational errors, our approach demonstrates superior performance in map-free relocalization techniques.
Camera-Invariant Meta-Learning Network for Single-Camera-Training Person Re-identification
Jun 21, 2024Single-camera-training person re-identification (SCT re-ID) aims to train a re-ID model using SCT datasets where each person appears in only one camera. The main challenge of SCT re-ID is to learn camera-invariant feature representations without cross-camera same-person (CCSP) data as supervision. Previous methods address it by assuming that the most similar person should be found in another camera. However, this assumption is not guaranteed to be correct. In this paper, we propose a Camera-Invariant Meta-Learning Network (CIMN) for SCT re-ID. CIMN assumes that the camera-invariant feature representations should be robust to camera changes. To this end, we split the training data into meta-train set and meta-test set based on camera IDs and perform a cross-camera simulation via meta-learning strategy, aiming to enforce the representations learned from the meta-train set to be robust to the meta-test set. With the cross-camera simulation, CIMN can learn camera-invariant and identity-discriminative representations even there are no CCSP data. However, this simulation also causes the separation of the meta-train set and the meta-test set, which ignores some beneficial relations between them. Thus, we introduce three losses: meta triplet loss, meta classification loss, and meta camera alignment loss, to leverage the ignored relations. The experiment results demonstrate that our method achieves comparable performance with and without CCSP data, and outperforms the state-of-the-art methods on SCT re-ID benchmarks. In addition, it is also effective in improving the domain generalization ability of the model.
OccupancyDETR: Making Semantic Scene Completion as Straightforward as Object Detection
Sep 22, 2023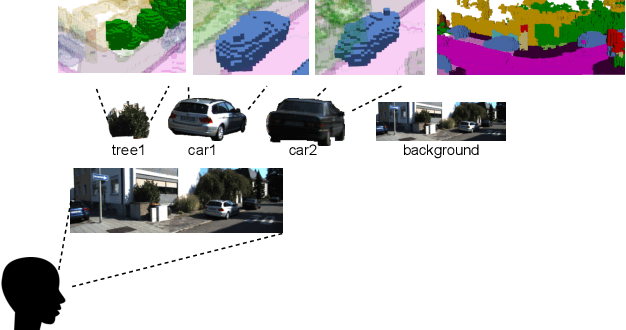
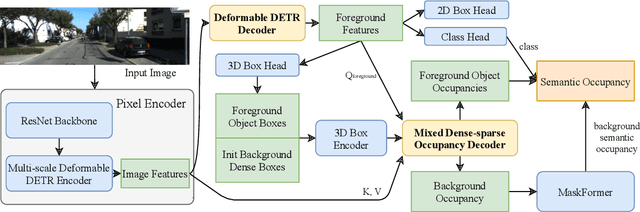
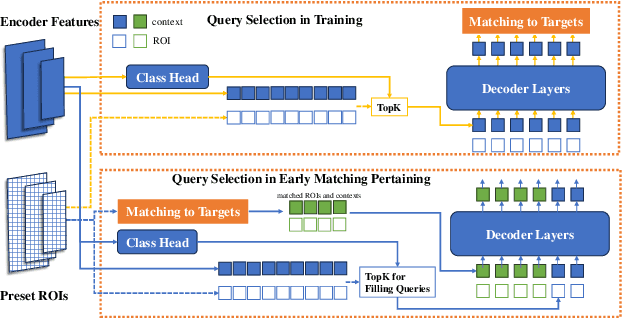
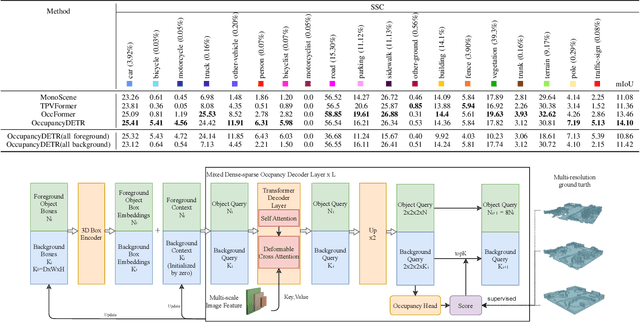
Visual-based 3D semantic occupancy perception (also known as 3D semantic scene completion) is a new perception paradigm for robotic applications like autonomous driving. Compared with Bird's Eye View (BEV) perception, it extends the vertical dimension, significantly enhancing the ability of robots to understand their surroundings. However, due to this very reason, the computational demand for current 3D semantic occupancy perception methods generally surpasses that of BEV perception methods and 2D perception methods. We propose a novel 3D semantic occupancy perception method, OccupancyDETR, which consists of a DETR-like object detection module and a 3D occupancy decoder module. The integration of object detection simplifies our method structurally - instead of predicting the semantics of each voxels, it identifies objects in the scene and their respective 3D occupancy grids. This speeds up our method, reduces required resources, and leverages object detection algorithm, giving our approach notable performance on small objects. We demonstrate the effectiveness of our proposed method on the SemanticKITTI dataset, showcasing an mIoU of 23 and a processing speed of 6 frames per second, thereby presenting a promising solution for real-time 3D semantic scene completion.
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Jul 27, 2023



Accurate depth estimation under out-of-distribution (OoD) scenarios, such as adverse weather conditions, sensor failure, and noise contamination, is desirable for safety-critical applications. Existing depth estimation systems, however, suffer inevitably from real-world corruptions and perturbations and are struggled to provide reliable depth predictions under such cases. In this paper, we summarize the winning solutions from the RoboDepth Challenge -- an academic competition designed to facilitate and advance robust OoD depth estimation. This challenge was developed based on the newly established KITTI-C and NYUDepth2-C benchmarks. We hosted two stand-alone tracks, with an emphasis on robust self-supervised and robust fully-supervised depth estimation, respectively. Out of more than two hundred participants, nine unique and top-performing solutions have appeared, with novel designs ranging from the following aspects: spatial- and frequency-domain augmentations, masked image modeling, image restoration and super-resolution, adversarial training, diffusion-based noise suppression, vision-language pre-training, learned model ensembling, and hierarchical feature enhancement. Extensive experimental analyses along with insightful observations are drawn to better understand the rationale behind each design. We hope this challenge could lay a solid foundation for future research on robust and reliable depth estimation and beyond. The datasets, competition toolkit, workshop recordings, and source code from the winning teams are publicly available on the challenge website.
Fine-Grained Trajectory-based Travel Time Estimation for Multi-city Scenarios Based on Deep Meta-Learning
Jan 20, 2022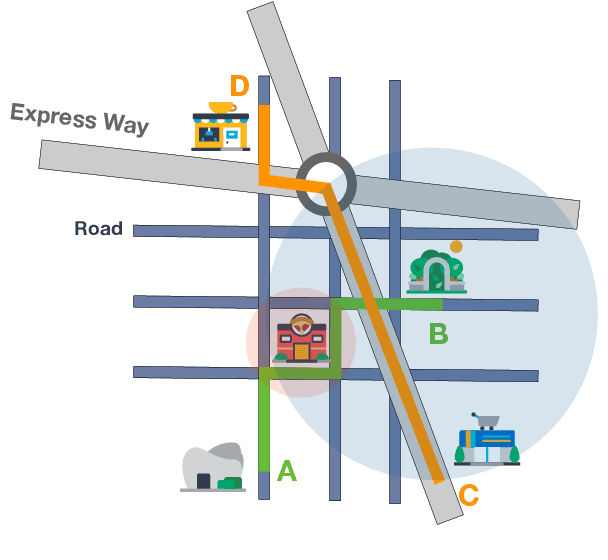


Travel Time Estimation (TTE) is indispensable in intelligent transportation system (ITS). It is significant to achieve the fine-grained Trajectory-based Travel Time Estimation (TTTE) for multi-city scenarios, namely to accurately estimate travel time of the given trajectory for multiple city scenarios. However, it faces great challenges due to complex factors including dynamic temporal dependencies and fine-grained spatial dependencies. To tackle these challenges, we propose a meta learning based framework, MetaTTE, to continuously provide accurate travel time estimation over time by leveraging well-designed deep neural network model called DED, which consists of Data preprocessing module and Encoder-Decoder network module. By introducing meta learning techniques, the generalization ability of MetaTTE is enhanced using small amount of examples, which opens up new opportunities to increase the potential of achieving consistent performance on TTTE when traffic conditions and road networks change over time in the future. The DED model adopts an encoder-decoder network to capture fine-grained spatial and temporal representations. Extensive experiments on two real-world datasets are conducted to confirm that our MetaTTE outperforms six state-of-art baselines, and improve 29.35% and 25.93% accuracy than the best baseline on Chengdu and Porto datasets, respectively.
STformer: A Noise-Aware Efficient Spatio-Temporal Transformer Architecture for Traffic Forecasting
Dec 06, 2021

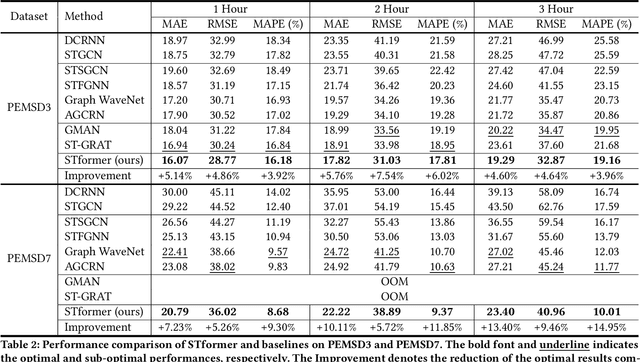
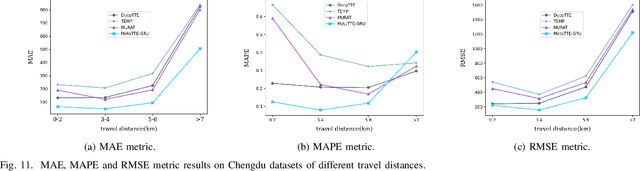
Traffic forecasting plays an indispensable role in the intelligent transportation system, which makes daily travel more convenient and safer. However, the dynamic evolution of spatio-temporal correlations makes accurate traffic forecasting very difficult. Existing work mainly employs graph neural netwroks (GNNs) and deep time series models (e.g., recurrent neural networks) to capture complex spatio-temporal patterns in the dynamic traffic system. For the spatial patterns, it is difficult for GNNs to extract the global spatial information, i.e., remote sensors information in road networks. Although we can use the self-attention to extract global spatial information as in the previous work, it is also accompanied by huge resource consumption. For the temporal patterns, traffic data have not only easy-to-recognize daily and weekly trends but also difficult-to-recognize short-term noise caused by accidents (e.g., car accidents and thunderstorms). Prior traffic models are difficult to distinguish intricate temporal patterns in time series and thus hard to get accurate temporal dependence. To address above issues, we propose a novel noise-aware efficient spatio-temporal Transformer architecture for accurate traffic forecasting, named STformer. STformer consists of two components, which are the noise-aware temporal self-attention (NATSA) and the graph-based sparse spatial self-attention (GBS3A). NATSA separates the high-frequency component and the low-frequency component from the time series to remove noise and capture stable temporal dependence by the learnable filter and the temporal self-attention, respectively. GBS3A replaces the full query in vanilla self-attention with the graph-based sparse query to decrease the time and memory usage. Experiments on four real-world traffic datasets show that STformer outperforms state-of-the-art baselines with lower computational cost.
CDGNet: A Cross-Time Dynamic Graph-based Deep Learning Model for Traffic Forecasting
Dec 06, 2021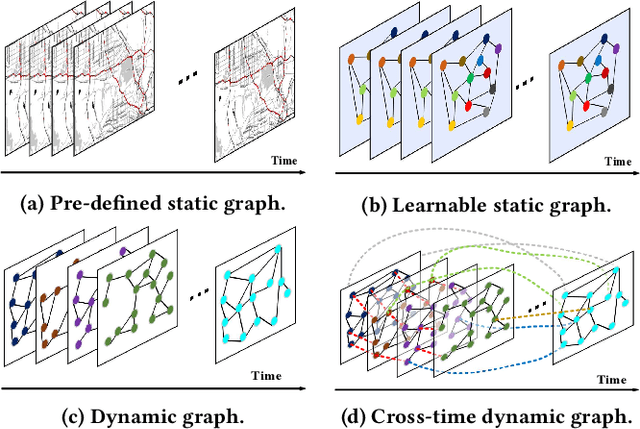
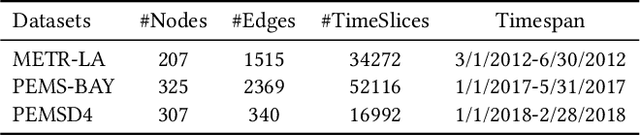
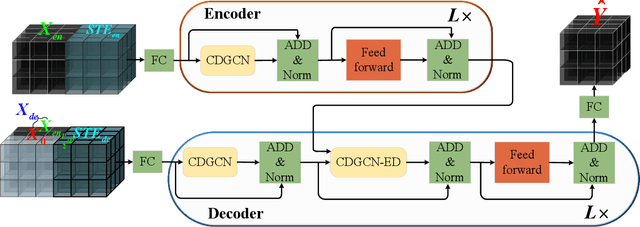
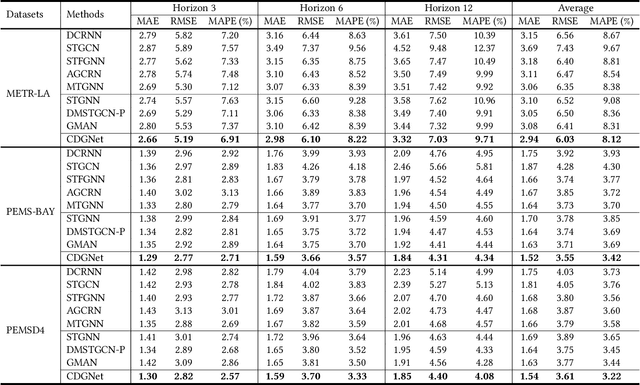
Traffic forecasting is important in intelligent transportation systems of webs and beneficial to traffic safety, yet is very challenging because of the complex and dynamic spatio-temporal dependencies in real-world traffic systems. Prior methods use the pre-defined or learnable static graph to extract spatial correlations. However, the static graph-based methods fail to mine the evolution of the traffic network. Researchers subsequently generate the dynamic graph for each time slice to reflect the changes of spatial correlations, but they follow the paradigm of independently modeling spatio-temporal dependencies, ignoring the cross-time spatial influence. In this paper, we propose a novel cross-time dynamic graph-based deep learning model, named CDGNet, for traffic forecasting. The model is able to effectively capture the cross-time spatial dependence between each time slice and its historical time slices by utilizing the cross-time dynamic graph. Meanwhile, we design a gating mechanism to sparse the cross-time dynamic graph, which conforms to the sparse spatial correlations in the real world. Besides, we propose a novel encoder-decoder architecture to incorporate the cross-time dynamic graph-based GCN for multi-step traffic forecasting. Experimental results on three real-world public traffic datasets demonstrate that CDGNet outperforms the state-of-the-art baselines. We additionally provide a qualitative study to analyze the effectiveness of our architecture.
DMGCRN: Dynamic Multi-Graph Convolution Recurrent Network for Traffic Forecasting
Dec 04, 2021



Traffic forecasting is a problem of intelligent transportation systems (ITS) and crucial for individuals and public agencies. Therefore, researches pay great attention to deal with the complex spatio-temporal dependencies of traffic system for accurate forecasting. However, there are two challenges: 1) Most traffic forecasting studies mainly focus on modeling correlations of neighboring sensors and ignore correlations of remote sensors, e.g., business districts with similar spatio-temporal patterns; 2) Prior methods which use static adjacency matrix in graph convolutional networks (GCNs) are not enough to reflect the dynamic spatial dependence in traffic system. Moreover, fine-grained methods which use self-attention to model dynamic correlations of all sensors ignore hierarchical information in road networks and have quadratic computational complexity. In this paper, we propose a novel dynamic multi-graph convolution recurrent network (DMGCRN) to tackle above issues, which can model the spatial correlations of distance, the spatial correlations of structure, and the temporal correlations simultaneously. We not only use the distance-based graph to capture spatial information from nodes are close in distance but also construct a novel latent graph which encoded the structure correlations among roads to capture spatial information from nodes are similar in structure. Furthermore, we divide the neighbors of each sensor into coarse-grained regions, and dynamically assign different weights to each region at different times. Meanwhile, we integrate the dynamic multi-graph convolution network into the gated recurrent unit (GRU) to capture temporal dependence. Extensive experiments on three real-world traffic datasets demonstrate that our proposed algorithm outperforms state-of-the-art baselines.