 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransBridge: Boost 3D Object Detection by Scene-Level Completion with Transformer Decoder
Dec 12, 2025



3D object detection is essential in autonomous driving, providing vital information about moving objects and obstacles. Detecting objects in distant regions with only a few LiDAR points is still a challenge, and numerous strategies have been developed to address point cloud sparsity through densification.This paper presents a joint completion and detection framework that improves the detection feature in sparse areas while maintaining costs unchanged. Specifically, we propose TransBridge, a novel transformer-based up-sampling block that fuses the features from the detection and completion networks.The detection network can benefit from acquiring implicit completion features derived from the completion network. Additionally, we design the Dynamic-Static Reconstruction (DSRecon) module to produce dense LiDAR data for the completion network, meeting the requirement for dense point cloud ground truth.Furthermore, we employ the transformer mechanism to establish connections between channels and spatial relations, resulting in a high-resolution feature map used for completion purposes.Extensive experiments on the nuScenes and Waymo datasets demonstrate the effectiveness of the proposed framework.The results show that our framework consistently improves end-to-end 3D object detection, with the mean average precision (mAP) ranging from 0.7 to 1.5 across multiple methods, indicating its generalization ability. For the two-stage detection framework, it also boosts the mAP up to 5.78 points.
CMD: Constraining Multimodal Distribution for Domain Adaptation in Stereo Matching
Apr 30, 2025Recently, learning-based stereo matching methods have achieved great improvement in public benchmarks, where soft argmin and smooth L1 loss play a core contribution to their success. However, in unsupervised domain adaptation scenarios, we observe that these two operations often yield multimodal disparity probability distributions in target domains, resulting in degraded generalization. In this paper, we propose a novel approach, Constrain Multi-modal Distribution (CMD), to address this issue. Specifically, we introduce \textit{uncertainty-regularized minimization} and \textit{anisotropic soft argmin} to encourage the network to produce predominantly unimodal disparity distributions in the target domain, thereby improving prediction accuracy. Experimentally, we apply the proposed method to multiple representative stereo-matching networks and conduct domain adaptation from synthetic data to unlabeled real-world scenes. Results consistently demonstrate improved generalization in both top-performing and domain-adaptable stereo-matching models. The code for CMD will be available at: \href{https://github.com/gallenszl/CMD}{https://github.com/gallenszl/CMD}.
Understanding Particles From Video: Property Estimation of Granular Materials via Visuo-Haptic Learning
Dec 03, 2024



Granular materials (GMs) are ubiquitous in daily life. Understanding their properties is also important, especially in agriculture and industry. However, existing works require dedicated measurement equipment and also need large human efforts to handle a large number of particles. In this paper, we introduce a method for estimating the relative values of particle size and density from the video of the interaction with GMs. It is trained on a visuo-haptic learning framework inspired by a contact model, which reveals the strong correlation between GM properties and the visual-haptic data during the probe-dragging in the GMs. After training, the network can map the visual modality well to the haptic signal and implicitly characterize the relative distribution of particle properties in its latent embeddings, as interpreted in that contact model. Therefore, we can analyze GM properties using the trained encoder, and only visual information is needed without extra sensory modalities and human efforts for labeling. The presented GM property estimator has been extensively validated via comparison and ablation experiments. The generalization capability has also been evaluated and a real-world application on the beach is also demonstrated. Experiment videos are available at \url{https://sites.google.com/view/gmwork/vhlearning} .
A Haptic-Based Proximity Sensing System for Buried Object in Granular Material
Nov 26, 2024



The proximity perception of objects in granular materials is significant, especially for applications like minesweeping. However, due to particles' opacity and complex properties, existing proximity sensors suffer from high costs from sophisticated hardware and high user-cost from unintuitive results. In this paper, we propose a simple yet effective proximity sensing system for underground stuff based on the haptic feedback of the sensor-granules interaction. We study and employ the unique characteristic of particles -- failure wedge zone, and combine the machine learning method -- Gaussian process regression, to identify the force signal changes induced by the proximity of objects, so as to achieve near-field perception. Furthermore, we design a novel trajectory to control the probe searching in granules for a wide range of perception. Also, our proximity sensing system can adaptively determine optimal parameters for robustness operation in different particles. Experiments demonstrate our system can perceive underground objects over 0.5 to 7 cm in advance among various materials.
RT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model
Nov 07, 2024Recent advances in Large Language Models (LLMs) have showcased their remarkable reasoning capabilities, making them influential across various fields. However, in robotics, their use has primarily been limited to manipulation planning tasks due to their inherent textual output. This paper addresses this limitation by investigating the potential of adopting the reasoning ability of LLMs for generating numerical predictions in robotics tasks, specifically for robotic grasping. We propose Reasoning Tuning, a novel method that integrates a reasoning phase before prediction during training, leveraging the extensive prior knowledge and advanced reasoning abilities of LLMs. This approach enables LLMs, notably with multi-modal capabilities, to generate accurate numerical outputs like grasp poses that are context-aware and adaptable through conversations. Additionally, we present the Reasoning Tuning VLM Grasp dataset, carefully curated to facilitate the adaptation of LLMs to robotic grasping. Extensive validation on both grasping datasets and real-world experiments underscores the adaptability of multi-modal LLMs for numerical prediction tasks in robotics. This not only expands their applicability but also bridges the gap between text-based planning and direct robot control, thereby maximizing the potential of LLMs in robotics.
HERO-SLAM: Hybrid Enhanced Robust Optimization of Neural SLAM
Jul 26, 2024Simultaneous Localization and Mapping (SLAM) is a fundamental task in robotics, driving numerous applications such as autonomous driving and virtual reality. Recent progress on neural implicit SLAM has shown encouraging and impressive results. However, the robustness of neural SLAM, particularly in challenging or data-limited situations, remains an unresolved issue. This paper presents HERO-SLAM, a Hybrid Enhanced Robust Optimization method for neural SLAM, which combines the benefits of neural implicit field and feature-metric optimization. This hybrid method optimizes a multi-resolution implicit field and enhances robustness in challenging environments with sudden viewpoint changes or sparse data collection. Our comprehensive experimental results on benchmarking datasets validate the effectiveness of our hybrid approach, demonstrating its superior performance over existing implicit field-based methods in challenging scenarios. HERO-SLAM provides a new pathway to enhance the stability, performance, and applicability of neural SLAM in real-world scenarios. Code is available on the project page: https://hero-slam.github.io.
ExACT: An End-to-End Autonomous Excavator System Using Action Chunking With Transformers
May 09, 2024Excavators are crucial for diverse tasks such as construction and mining, while autonomous excavator systems enhance safety and efficiency, address labor shortages, and improve human working conditions. Different from the existing modularized approaches, this paper introduces ExACT, an end-to-end autonomous excavator system that processes raw LiDAR, camera data, and joint positions to control excavator valves directly. Utilizing the Action Chunking with Transformers (ACT) architecture, ExACT employs imitation learning to take observations from multi-modal sensors as inputs and generate actionable sequences. In our experiment, we build a simulator based on the captured real-world data to model the relations between excavator valve states and joint velocities. With a few human-operated demonstration data trajectories, ExACT demonstrates the capability of completing different excavation tasks, including reaching, digging and dumping through imitation learning in validations with the simulator. To the best of our knowledge, ExACT represents the first instance towards building an end-to-end autonomous excavator system via imitation learning methods with a minimal set of human demonstrations. The video about this work can be accessed at https://youtu.be/NmzR_Rf-aEk.
HO-Gaussian: Hybrid Optimization of 3D Gaussian Splatting for Urban Scenes
Mar 29, 2024


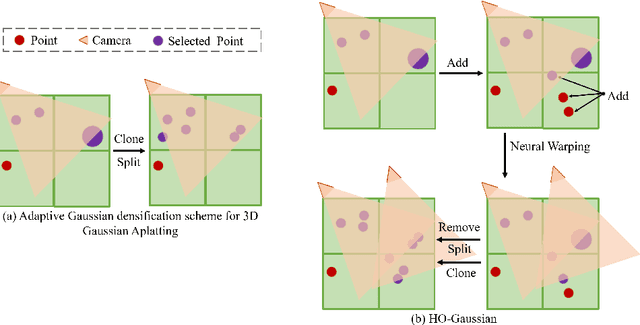
The rapid growth of 3D Gaussian Splatting (3DGS) has revolutionized neural rendering, enabling real-time production of high-quality renderings. However, the previous 3DGS-based methods have limitations in urban scenes due to reliance on initial Structure-from-Motion(SfM) points and difficulties in rendering distant, sky and low-texture areas. To overcome these challenges, we propose a hybrid optimization method named HO-Gaussian, which combines a grid-based volume with the 3DGS pipeline. HO-Gaussian eliminates the dependency on SfM point initialization, allowing for rendering of urban scenes, and incorporates the Point Densitification to enhance rendering quality in problematic regions during training. Furthermore, we introduce Gaussian Direction Encoding as an alternative for spherical harmonics in the rendering pipeline, which enables view-dependent color representation. To account for multi-camera systems, we introduce neural warping to enhance object consistency across different cameras. Experimental results on widely used autonomous driving datasets demonstrate that HO-Gaussian achieves photo-realistic rendering in real-time on multi-camera urban datasets.
RLingua: Improving Reinforcement Learning Sample Efficiency in Robotic Manipulations With Large Language Models
Mar 19, 2024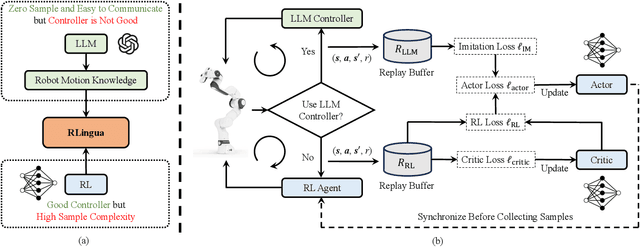
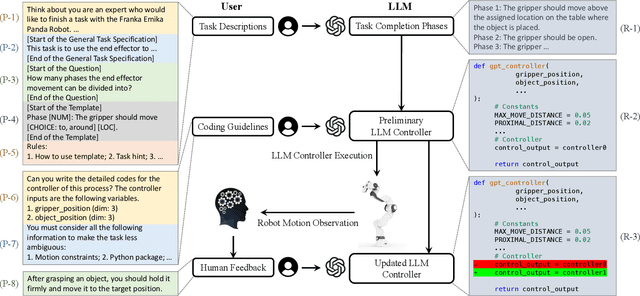
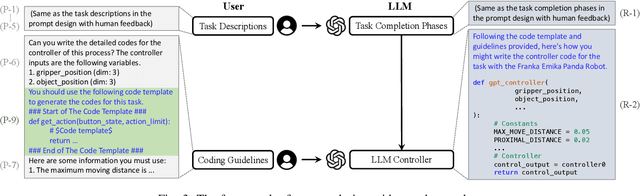
Reinforcement learning (RL) has demonstrated its capability in solving various tasks but is notorious for its low sample efficiency. In this paper, we propose RLingua, a framework that can leverage the internal knowledge of large language models (LLMs) to reduce the sample complexity of RL in robotic manipulations. To this end, we first present a method for extracting the prior knowledge of LLMs by prompt engineering so that a preliminary rule-based robot controller for a specific task can be generated in a user-friendly manner. Despite being imperfect, the LLM-generated robot controller is utilized to produce action samples during rollouts with a decaying probability, thereby improving RL's sample efficiency. We employ TD3, the widely-used RL baseline method, and modify the actor loss to regularize the policy learning towards the LLM-generated controller. RLingua also provides a novel method of improving the imperfect LLM-generated robot controllers by RL. We demonstrate that RLingua can significantly reduce the sample complexity of TD3 in four robot tasks of panda_gym and achieve high success rates in 12 sampled sparsely rewarded robot tasks in RLBench, where the standard TD3 fails. Additionally, We validated RLingua's effectiveness in real-world robot experiments through Sim2Real, demonstrating that the learned policies are effectively transferable to real robot tasks. Further details about our work are available at our project website https://rlingua.github.io.
VIHE: Virtual In-Hand Eye Transformer for 3D Robotic Manipulation
Mar 19, 2024In this work, we introduce the Virtual In-Hand Eye Transformer (VIHE), a novel method designed to enhance 3D manipulation capabilities through action-aware view rendering. VIHE autoregressively refines actions in multiple stages by conditioning on rendered views posed from action predictions in the earlier stages. These virtual in-hand views provide a strong inductive bias for effectively recognizing the correct pose for the hand, especially for challenging high-precision tasks such as peg insertion. On 18 manipulation tasks in RLBench simulated environments, VIHE achieves a new state-of-the-art, with a 12% absolute improvement, increasing from 65% to 77% over the existing state-of-the-art model using 100 demonstrations per task. In real-world scenarios, VIHE can learn manipulation tasks with just a handful of demonstrations, highlighting its practical utility. Videos and code implementation can be found at our project site: https://vihe-3d.github.io.