 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Particles From Video: Property Estimation of Granular Materials via Visuo-Haptic Learning
Dec 03, 2024



Granular materials (GMs) are ubiquitous in daily life. Understanding their properties is also important, especially in agriculture and industry. However, existing works require dedicated measurement equipment and also need large human efforts to handle a large number of particles. In this paper, we introduce a method for estimating the relative values of particle size and density from the video of the interaction with GMs. It is trained on a visuo-haptic learning framework inspired by a contact model, which reveals the strong correlation between GM properties and the visual-haptic data during the probe-dragging in the GMs. After training, the network can map the visual modality well to the haptic signal and implicitly characterize the relative distribution of particle properties in its latent embeddings, as interpreted in that contact model. Therefore, we can analyze GM properties using the trained encoder, and only visual information is needed without extra sensory modalities and human efforts for labeling. The presented GM property estimator has been extensively validated via comparison and ablation experiments. The generalization capability has also been evaluated and a real-world application on the beach is also demonstrated. Experiment videos are available at \url{https://sites.google.com/view/gmwork/vhlearning} .
DaDiff: Domain-aware Diffusion Model for Nighttime UAV Tracking
Oct 16, 2024Domain adaptation is an inspiring solution to the misalignment issue of day/night image features for nighttime UAV tracking. However, the one-step adaptation paradigm is inadequate in addressing the prevalent difficulties posed by low-resolution (LR) objects when viewed from the UAVs at night, owing to the blurry edge contour and limited detail information. Moreover, these approaches struggle to perceive LR objects disturbed by nighttime noise. To address these challenges, this work proposes a novel progressive alignment paradigm, named domain-aware diffusion model (DaDiff), aligning nighttime LR object features to the daytime by virtue of progressive and stable generations. The proposed DaDiff includes an alignment encoder to enhance the detail information of nighttime LR objects, a tracking-oriented layer designed to achieve close collaboration with tracking tasks, and a successive distribution discriminator presented to distinguish different feature distributions at each diffusion timestep successively. Furthermore, an elaborate nighttime UAV tracking benchmark is constructed for LR objects, namely NUT-LR, consisting of 100 annotated sequences. Exhaustive experiments have demonstrated the robustness and feature alignment ability of the proposed DaDiff. The source code and video demo are available at https://github.com/vision4robotics/DaDiff.
Prompt-Driven Temporal Domain Adaptation for Nighttime UAV Tracking
Sep 27, 2024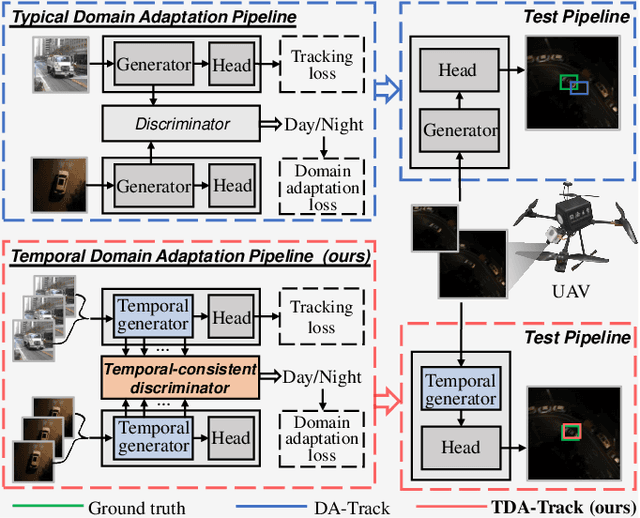

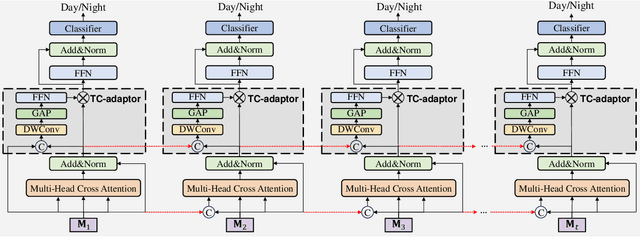

Nighttime UAV tracking under low-illuminated scenarios has achieved great progress by domain adaptation (DA). However, previous DA training-based works are deficient in narrowing the discrepancy of temporal contexts for UAV trackers. To address the issue, this work proposes a prompt-driven temporal domain adaptation training framework to fully utilize temporal contexts for challenging nighttime UAV tracking, i.e., TDA. Specifically, the proposed framework aligns the distribution of temporal contexts from daytime and nighttime domains by training the temporal feature generator against the discriminator. The temporal-consistent discriminator progressively extracts shared domain-specific features to generate coherent domain discrimination results in the time series. Additionally, to obtain high-quality training samples, a prompt-driven object miner is employed to precisely locate objects in unannotated nighttime videos. Moreover, a new benchmark for long-term nighttime UAV tracking is constructed. Exhaustive evaluations on both public and self-constructed nighttime benchmarks demonstrate the remarkable performance of the tracker trained in TDA framework, i.e., TDA-Track. Real-world tests at nighttime also show its practicality. The code and demo videos are available at https://github.com/vision4robotics/TDA-Track.
Progressive Representation Learning for Real-Time UAV Tracking
Sep 25, 2024



Visual object tracking has significantly promoted autonomous applications for unmanned aerial vehicles (UAVs). However, learning robust object representations for UAV tracking is especially challenging in complex dynamic environments, when confronted with aspect ratio change and occlusion. These challenges severely alter the original information of the object. To handle the above issues, this work proposes a novel progressive representation learning framework for UAV tracking, i.e., PRL-Track. Specifically, PRL-Track is divided into coarse representation learning and fine representation learning. For coarse representation learning, two innovative regulators, which rely on appearance and semantic information, are designed to mitigate appearance interference and capture semantic information. Furthermore, for fine representation learning, a new hierarchical modeling generator is developed to intertwine coarse object representations. Exhaustive experiments demonstrate that the proposed PRL-Track delivers exceptional performance on three authoritative UAV tracking benchmarks. Real-world tests indicate that the proposed PRL-Track realizes superior tracking performance with 42.6 frames per second on the typical UAV platform equipped with an edge smart camera. The code, model, and demo videos are available at \url{https://github.com/vision4robotics/PRL-Track}.
NetTrack: Tracking Highly Dynamic Objects with a Net
Mar 17, 2024



The complex dynamicity of open-world objects presents non-negligible challenges for multi-object tracking (MOT), often manifested as severe deformations, fast motion, and occlusions. Most methods that solely depend on coarse-grained object cues, such as boxes and the overall appearance of the object, are susceptible to degradation due to distorted internal relationships of dynamic objects. To address this problem, this work proposes NetTrack, an efficient, generic, and affordable tracking framework to introduce fine-grained learning that is robust to dynamicity. Specifically, NetTrack constructs a dynamicity-aware association with a fine-grained Net, leveraging point-level visual cues. Correspondingly, a fine-grained sampler and matching method have been incorporated. Furthermore, NetTrack learns object-text correspondence for fine-grained localization. To evaluate MOT in extremely dynamic open-world scenarios, a bird flock tracking (BFT) dataset is constructed, which exhibits high dynamicity with diverse species and open-world scenarios. Comprehensive evaluation on BFT validates the effectiveness of fine-grained learning on object dynamicity, and thorough transfer experiments on challenging open-world benchmarks, i.e., TAO, TAO-OW, AnimalTrack, and GMOT-40, validate the strong generalization ability of NetTrack even without finetuning. Project page: https://george-zhuang.github.io/nettrack/.
Simultaneous Synchronization and Calibration for Wide-baseline Stereo Event Cameras
Sep 29, 2023Event-based cameras are increasingly utilized in various applications, owing to their high temporal resolution and low power consumption. However, a fundamental challenge arises when deploying multiple such cameras: they operate on independent time systems, leading to temporal misalignment. This misalignment can significantly degrade performance in downstream applications. Traditional solutions, which often rely on hardware-based synchronization, face limitations in compatibility and are impractical for long-distance setups. To address these challenges, we propose a novel algorithm that exploits the motion of objects in the shared field of view to achieve millisecond-level synchronization among multiple event-based cameras. Our method also concurrently estimates extrinsic parameters. We validate our approach in both simulated and real-world indoor/outdoor scenarios, demonstrating successful synchronization and accurate extrinsic parameters estimation.
SAM-DA: UAV Tracks Anything at Night with SAM-Powered Domain Adaptation
Jul 03, 2023Domain adaptation (DA) has demonstrated significant promise for real-time nighttime unmanned aerial vehicle (UAV) tracking. However, the state-of-the-art (SOTA) DA still lacks the potential object with accurate pixel-level location and boundary to generate the high-quality target domain training sample. This key issue constrains the transfer learning of the real-time daytime SOTA trackers for challenging nighttime UAV tracking. Recently, the notable Segment Anything Model (SAM) has achieved remarkable zero-shot generalization ability to discover abundant potential objects due to its huge data-driven training approach. To solve the aforementioned issue, this work proposes a novel SAM-powered DA framework for real-time nighttime UAV tracking, i.e., SAM-DA. Specifically, an innovative SAM-powered target domain training sample swelling is designed to determine enormous high-quality target domain training samples from every single raw nighttime image. This novel one-to-many method significantly expands the high-quality target domain training sample for DA. Comprehensive experiments on extensive nighttime UAV videos prove the robustness and domain adaptability of SAM-DA for nighttime UAV tracking. Especially, compared to the SOTA DA, SAM-DA can achieve better performance with fewer raw nighttime images, i.e., the fewer-better training. This economized training approach facilitates the quick validation and deployment of algorithms for UAVs. The code is available at https://github.com/vision4robotics/SAM-DA.
Tracker Meets Night: A Transformer Enhancer for UAV Tracking
Mar 20, 2023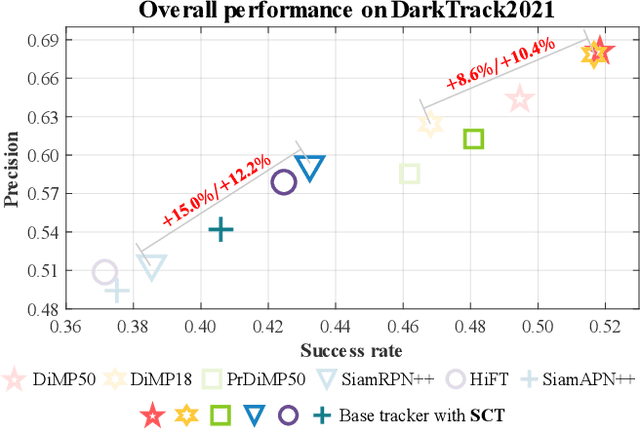
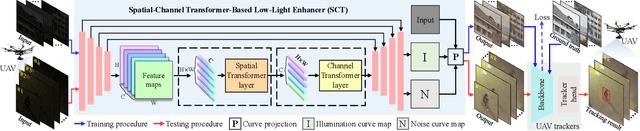
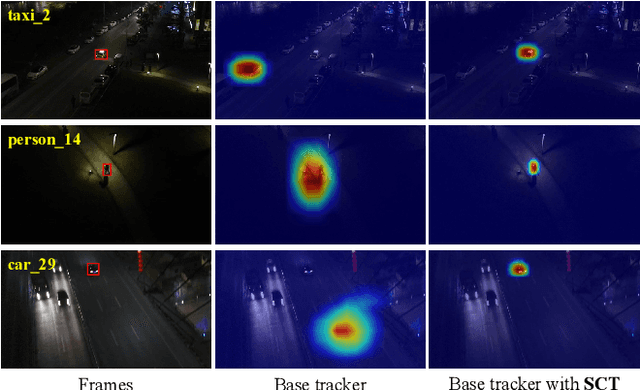
Most previous progress in object tracking is realized in daytime scenes with favorable illumination. State-of-the-arts can hardly carry on their superiority at night so far, thereby considerably blocking the broadening of visual tracking-related unmanned aerial vehicle (UAV) applications. To realize reliable UAV tracking at night, a spatial-channel Transformer-based low-light enhancer (namely SCT), which is trained in a novel task-inspired manner, is proposed and plugged prior to tracking approaches. To achieve semantic-level low-light enhancement targeting the high-level task, the novel spatial-channel attention module is proposed to model global information while preserving local context. In the enhancement process, SCT denoises and illuminates nighttime images simultaneously through a robust non-linear curve projection. Moreover, to provide a comprehensive evaluation, we construct a challenging nighttime tracking benchmark, namely DarkTrack2021, which contains 110 challenging sequences with over 100 K frames in total. Evaluations on both the public UAVDark135 benchmark and the newly constructed DarkTrack2021 benchmark show that the task-inspired design enables SCT with significant performance gains for nighttime UAV tracking compared with other top-ranked low-light enhancers. Real-world tests on a typical UAV platform further verify the practicability of the proposed approach. The DarkTrack2021 benchmark and the code of the proposed approach are publicly available at https://github.com/vision4robotics/SCT.
SGDViT: Saliency-Guided Dynamic Vision Transformer for UAV Tracking
Mar 08, 2023



Vision-based object tracking has boosted extensive autonomous applications for unmanned aerial vehicles (UAVs). However, the dynamic changes in flight maneuver and viewpoint encountered in UAV tracking pose significant difficulties, e.g. , aspect ratio change, and scale variation. The conventional cross-correlation operation, while commonly used, has limitations in effectively capturing perceptual similarity and incorporates extraneous background information. To mitigate these limitations, this work presents a novel saliency-guided dynamic vision Transformer (SGDViT) for UAV tracking. The proposed method designs a new task-specific object saliency mining network to refine the cross-correlation operation and effectively discriminate foreground and background information. Additionally, a saliency adaptation embedding operation dynamically generates tokens based on initial saliency, thereby reducing the computational complexity of the Transformer architecture. Finally, a lightweight saliency filtering Transformer further refines saliency information and increases the focus on appearance information. The efficacy and robustness of the proposed approach have been thoroughly assessed through experiments on three widely-used UAV tracking benchmarks and real-world scenarios, with results demonstrating its superiority. The source code and demo videos are available at https://github.com/vision4robotics/SGDViT.
Siamese Object Tracking for Vision-Based UAM Approaching with Pairwise Scale-Channel Attention
Nov 26, 2022



Although the manipulating of the unmanned aerial manipulator (UAM) has been widely studied, vision-based UAM approaching, which is crucial to the subsequent manipulating, generally lacks effective design. The key to the visual UAM approaching lies in object tracking, while current UAM tracking typically relies on costly model-based methods. Besides, UAM approaching often confronts more severe object scale variation issues, which makes it inappropriate to directly employ state-of-the-art model-free Siamese-based methods from the object tracking field. To address the above problems, this work proposes a novel Siamese network with pairwise scale-channel attention (SiamSA) for vision-based UAM approaching. Specifically, SiamSA consists of a pairwise scale-channel attention network (PSAN) and a scale-aware anchor proposal network (SA-APN). PSAN acquires valuable scale information for feature processing, while SA-APN mainly attaches scale awareness to anchor proposing. Moreover, a new tracking benchmark for UAM approaching, namely UAMT100, is recorded with 35K frames on a flying UAM platform for evaluation. Exhaustive experiments on the benchmarks and real-world tests validate the efficiency and practicality of SiamSA with a promising speed. Both the code and UAMT100 benchmark are now available at https://github.com/vision4robotics/SiamSA.