 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Prompt-Driven Feature Encoding for Nighttime UAV Tracking
Mar 20, 2026Robust feature encoding constitutes the foundation of UAV tracking by enabling the nuanced perception of target appearance and motion, thereby playing a pivotal role in ensuring reliable tracking. However, existing feature encoding methods often overlook critical illumination and viewpoint cues, which are essential for robust perception under challenging nighttime conditions, leading to degraded tracking performance. To overcome the above limitation, this work proposes a dual prompt-driven feature encoding method that integrates prompt-conditioned feature adaptation and context-aware prompt evolution to promote domain-invariant feature encoding. Specifically, the pyramid illumination prompter is proposed to extract multi-scale frequency-aware illumination prompts. %The dynamic viewpoint prompter adapts the sampling to different viewpoints, enabling the tracker to learn view-invariant features. The dynamic viewpoint prompter modulates deformable convolution offsets to accommodate viewpoint variations, enabling the tracker to learn view-invariant features. Extensive experiments validate the effectiveness of the proposed dual prompt-driven tracker (DPTracker) in tackling nighttime UAV tracking. Ablation studies highlight the contribution of each component in DPTracker. Real-world tests under diverse nighttime UAV tracking scenarios further demonstrate the robustness and practical utility. The code and demo videos are available at https://github.com/yiheng-wang-duke/DPTracker.
EdgeSpotter: Multi-Scale Dense Text Spotting for Industrial Panel Monitoring
Jun 08, 2025



Text spotting for industrial panels is a key task for intelligent monitoring. However, achieving efficient and accurate text spotting for complex industrial panels remains challenging due to issues such as cross-scale localization and ambiguous boundaries in dense text regions. Moreover, most existing methods primarily focus on representing a single text shape, neglecting a comprehensive exploration of multi-scale feature information across different texts. To address these issues, this work proposes a novel multi-scale dense text spotter for edge AI-based vision system (EdgeSpotter) to achieve accurate and robust industrial panel monitoring. Specifically, a novel Transformer with efficient mixer is developed to learn the interdependencies among multi-level features, integrating multi-layer spatial and semantic cues. In addition, a new feature sampling with catmull-rom splines is designed, which explicitly encodes the shape, position, and semantic information of text, thereby alleviating missed detections and reducing recognition errors caused by multi-scale or dense text regions. Furthermore, a new benchmark dataset for industrial panel monitoring (IPM) is constructed. Extensive qualitative and quantitative evaluations on this challenging benchmark dataset validate the superior performance of the proposed method in different challenging panel monitoring tasks. Finally, practical tests based on the self-designed edge AI-based vision system demonstrate the practicality of the method. The code and demo will be available at https://github.com/vision4robotics/EdgeSpotter.
AnyTSR: Any-Scale Thermal Super-Resolution for UAV
Apr 18, 2025Thermal imaging can greatly enhance the application of intelligent unmanned aerial vehicles (UAV) in challenging environments. However, the inherent low resolution of thermal sensors leads to insufficient details and blurred boundaries. Super-resolution (SR) offers a promising solution to address this issue, while most existing SR methods are designed for fixed-scale SR. They are computationally expensive and inflexible in practical applications. To address above issues, this work proposes a novel any-scale thermal SR method (AnyTSR) for UAV within a single model. Specifically, a new image encoder is proposed to explicitly assign specific feature code to enable more accurate and flexible representation. Additionally, by effectively embedding coordinate offset information into the local feature ensemble, an innovative any-scale upsampler is proposed to better understand spatial relationships and reduce artifacts. Moreover, a novel dataset (UAV-TSR), covering both land and water scenes, is constructed for thermal SR tasks. Experimental results demonstrate that the proposed method consistently outperforms state-of-the-art methods across all scaling factors as well as generates more accurate and detailed high-resolution images. The code is located at https://github.com/vision4robotics/AnyTSR.
DaDiff: Domain-aware Diffusion Model for Nighttime UAV Tracking
Oct 16, 2024Domain adaptation is an inspiring solution to the misalignment issue of day/night image features for nighttime UAV tracking. However, the one-step adaptation paradigm is inadequate in addressing the prevalent difficulties posed by low-resolution (LR) objects when viewed from the UAVs at night, owing to the blurry edge contour and limited detail information. Moreover, these approaches struggle to perceive LR objects disturbed by nighttime noise. To address these challenges, this work proposes a novel progressive alignment paradigm, named domain-aware diffusion model (DaDiff), aligning nighttime LR object features to the daytime by virtue of progressive and stable generations. The proposed DaDiff includes an alignment encoder to enhance the detail information of nighttime LR objects, a tracking-oriented layer designed to achieve close collaboration with tracking tasks, and a successive distribution discriminator presented to distinguish different feature distributions at each diffusion timestep successively. Furthermore, an elaborate nighttime UAV tracking benchmark is constructed for LR objects, namely NUT-LR, consisting of 100 annotated sequences. Exhaustive experiments have demonstrated the robustness and feature alignment ability of the proposed DaDiff. The source code and video demo are available at https://github.com/vision4robotics/DaDiff.
Intelligent Fish Detection System with Similarity-Aware Transformer
Sep 28, 2024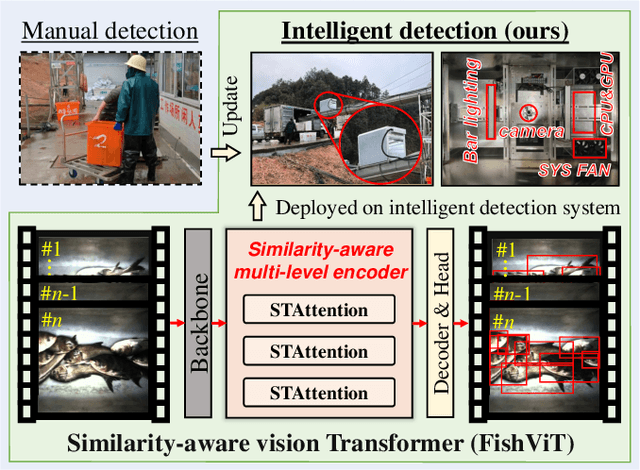
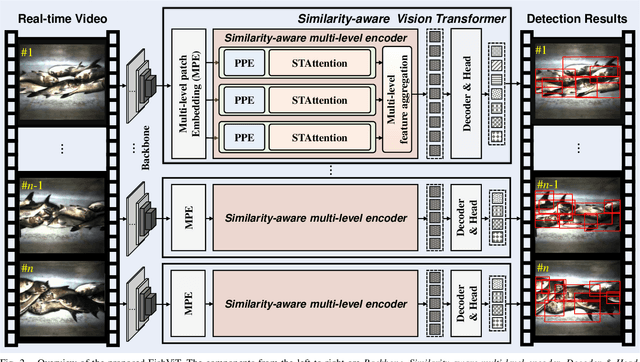
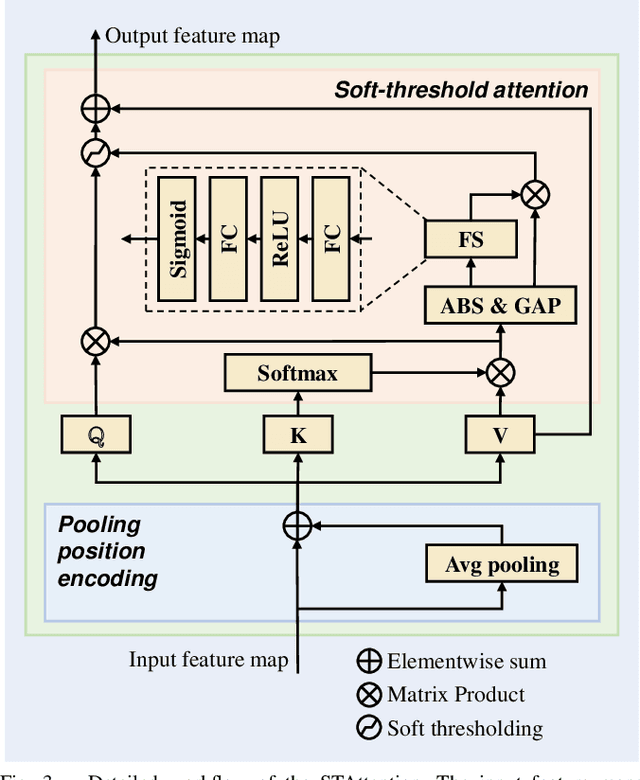

Fish detection in water-land transfer has significantly contributed to the fishery. However, manual fish detection in crowd-collaboration performs inefficiently and expensively, involving insufficient accuracy. To further enhance the water-land transfer efficiency, improve detection accuracy, and reduce labor costs, this work designs a new type of lightweight and plug-and-play edge intelligent vision system to automatically conduct fast fish detection with high-speed camera. Moreover, a novel similarity-aware vision Transformer for fast fish detection (FishViT) is proposed to onboard identify every single fish in a dense and similar group. Specifically, a novel similarity-aware multi-level encoder is developed to enhance multi-scale features in parallel, thereby yielding discriminative representations for varying-size fish. Additionally, a new soft-threshold attention mechanism is introduced, which not only effectively eliminates background noise from images but also accurately recognizes both the edge details and overall features of different similar fish. 85 challenging video sequences with high framerate and high-resolution are collected to establish a benchmark from real fish water-land transfer scenarios. Exhaustive evaluation conducted with this challenging benchmark has proved the robustness and effectiveness of FishViT with over 80 FPS. Real work scenario tests validate the practicality of the proposed method. The code and demo video are available at https://github.com/vision4robotics/FishViT.
Prompt-Driven Temporal Domain Adaptation for Nighttime UAV Tracking
Sep 27, 2024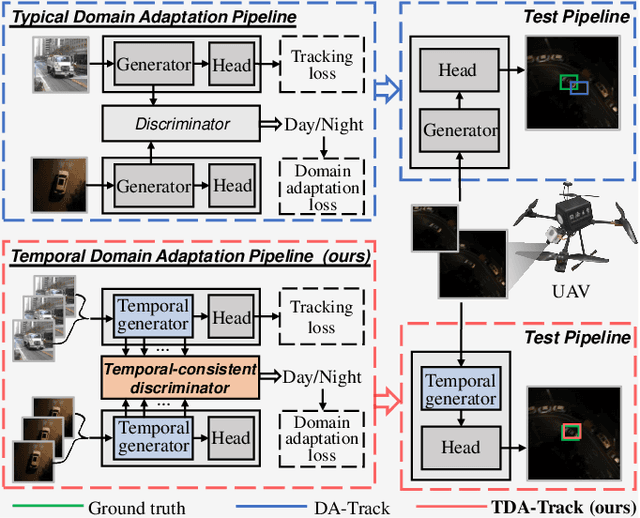

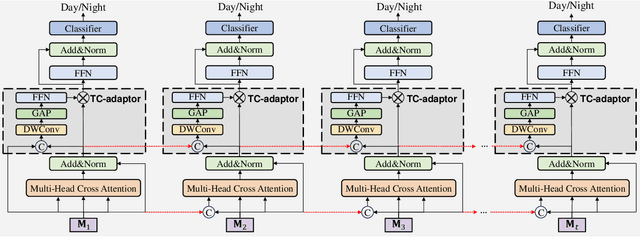

Nighttime UAV tracking under low-illuminated scenarios has achieved great progress by domain adaptation (DA). However, previous DA training-based works are deficient in narrowing the discrepancy of temporal contexts for UAV trackers. To address the issue, this work proposes a prompt-driven temporal domain adaptation training framework to fully utilize temporal contexts for challenging nighttime UAV tracking, i.e., TDA. Specifically, the proposed framework aligns the distribution of temporal contexts from daytime and nighttime domains by training the temporal feature generator against the discriminator. The temporal-consistent discriminator progressively extracts shared domain-specific features to generate coherent domain discrimination results in the time series. Additionally, to obtain high-quality training samples, a prompt-driven object miner is employed to precisely locate objects in unannotated nighttime videos. Moreover, a new benchmark for long-term nighttime UAV tracking is constructed. Exhaustive evaluations on both public and self-constructed nighttime benchmarks demonstrate the remarkable performance of the tracker trained in TDA framework, i.e., TDA-Track. Real-world tests at nighttime also show its practicality. The code and demo videos are available at https://github.com/vision4robotics/TDA-Track.
Progressive Representation Learning for Real-Time UAV Tracking
Sep 25, 2024



Visual object tracking has significantly promoted autonomous applications for unmanned aerial vehicles (UAVs). However, learning robust object representations for UAV tracking is especially challenging in complex dynamic environments, when confronted with aspect ratio change and occlusion. These challenges severely alter the original information of the object. To handle the above issues, this work proposes a novel progressive representation learning framework for UAV tracking, i.e., PRL-Track. Specifically, PRL-Track is divided into coarse representation learning and fine representation learning. For coarse representation learning, two innovative regulators, which rely on appearance and semantic information, are designed to mitigate appearance interference and capture semantic information. Furthermore, for fine representation learning, a new hierarchical modeling generator is developed to intertwine coarse object representations. Exhaustive experiments demonstrate that the proposed PRL-Track delivers exceptional performance on three authoritative UAV tracking benchmarks. Real-world tests indicate that the proposed PRL-Track realizes superior tracking performance with 42.6 frames per second on the typical UAV platform equipped with an edge smart camera. The code, model, and demo videos are available at \url{https://github.com/vision4robotics/PRL-Track}.
Enhancing Nighttime UAV Tracking with Light Distribution Suppression
Sep 25, 2024Visual object tracking has boosted extensive intelligent applications for unmanned aerial vehicles (UAVs). However, the state-of-the-art (SOTA) enhancers for nighttime UAV tracking always neglect the uneven light distribution in low-light images, inevitably leading to excessive enhancement in scenarios with complex illumination. To address these issues, this work proposes a novel enhancer, i.e., LDEnhancer, enhancing nighttime UAV tracking with light distribution suppression. Specifically, a novel image content refinement module is developed to decompose the light distribution information and image content information in the feature space, allowing for the targeted enhancement of the image content information. Then this work designs a new light distribution generation module to capture light distribution effectively. The features with light distribution information and image content information are fed into the different parameter estimation modules, respectively, for the parameter map prediction. Finally, leveraging two parameter maps, an innovative interweave iteration adjustment is proposed for the collaborative pixel-wise adjustment of low-light images. Additionally, a challenging nighttime UAV tracking dataset with uneven light distribution, namely NAT2024-2, is constructed to provide a comprehensive evaluation, which contains 40 challenging sequences with over 74K frames in total. Experimental results on the authoritative UAV benchmarks and the proposed NAT2024-2 demonstrate that LDEnhancer outperforms other SOTA low-light enhancers for nighttime UAV tracking. Furthermore, real-world tests on a typical UAV platform with an NVIDIA Orin NX confirm the practicality and efficiency of LDEnhancer. The code is available at https://github.com/vision4robotics/LDEnhancer.
Conditional Generative Denoiser for Nighttime UAV Tracking
Sep 25, 2024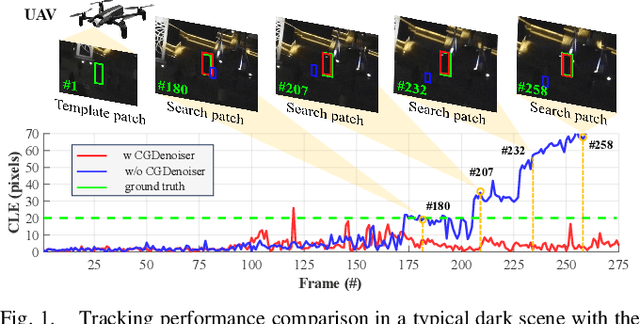
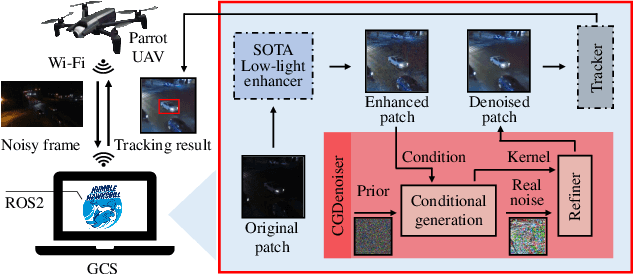

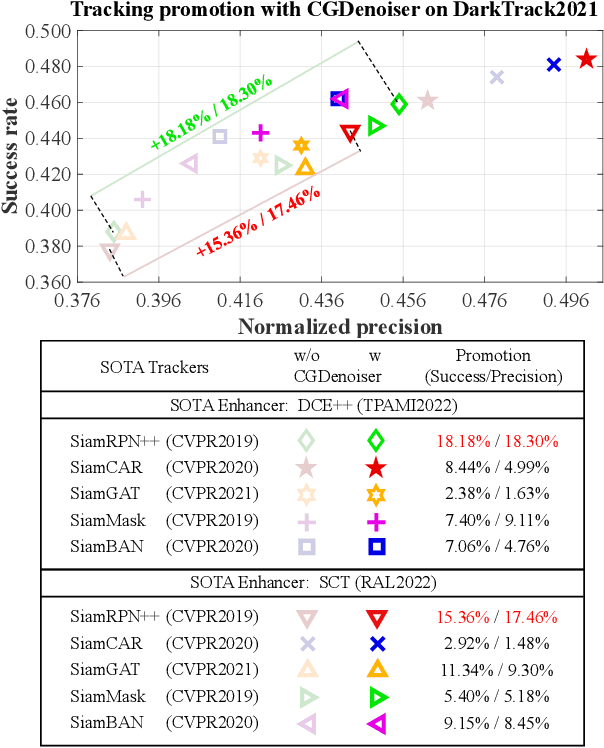
State-of-the-art (SOTA) visual object tracking methods have significantly enhanced the autonomy of unmanned aerial vehicles (UAVs). However, in low-light conditions, the presence of irregular real noise from the environments severely degrades the performance of these SOTA methods. Moreover, existing SOTA denoising techniques often fail to meet the real-time processing requirements when deployed as plug-and-play denoisers for UAV tracking. To address this challenge, this work proposes a novel conditional generative denoiser (CGDenoiser), which breaks free from the limitations of traditional deterministic paradigms and generates the noise conditioning on the input, subsequently removing it. To better align the input dimensions and accelerate inference, a novel nested residual Transformer conditionalizer is developed. Furthermore, an innovative multi-kernel conditional refiner is designed to pertinently refine the denoised output. Extensive experiments show that CGDenoiser promotes the tracking precision of the SOTA tracker by 18.18\% on DarkTrack2021 whereas working 5.8 times faster than the second well-performed denoiser. Real-world tests with complex challenges also prove the effectiveness and practicality of CGDenoiser. Code, video demo and supplementary proof for CGDenoier are now available at: \url{https://github.com/vision4robotics/CGDenoiser}.
NetTrack: Tracking Highly Dynamic Objects with a Net
Mar 17, 2024



The complex dynamicity of open-world objects presents non-negligible challenges for multi-object tracking (MOT), often manifested as severe deformations, fast motion, and occlusions. Most methods that solely depend on coarse-grained object cues, such as boxes and the overall appearance of the object, are susceptible to degradation due to distorted internal relationships of dynamic objects. To address this problem, this work proposes NetTrack, an efficient, generic, and affordable tracking framework to introduce fine-grained learning that is robust to dynamicity. Specifically, NetTrack constructs a dynamicity-aware association with a fine-grained Net, leveraging point-level visual cues. Correspondingly, a fine-grained sampler and matching method have been incorporated. Furthermore, NetTrack learns object-text correspondence for fine-grained localization. To evaluate MOT in extremely dynamic open-world scenarios, a bird flock tracking (BFT) dataset is constructed, which exhibits high dynamicity with diverse species and open-world scenarios. Comprehensive evaluation on BFT validates the effectiveness of fine-grained learning on object dynamicity, and thorough transfer experiments on challenging open-world benchmarks, i.e., TAO, TAO-OW, AnimalTrack, and GMOT-40, validate the strong generalization ability of NetTrack even without finetuning. Project page: https://george-zhuang.github.io/nettrack/.