 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
Scientists' First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
Jun 12, 2025Scientific discoveries increasingly rely on complex multimodal reasoning based on information-intensive scientific data and domain-specific expertise. Empowered by expert-level scientific benchmarks, scientific Multimodal Large Language Models (MLLMs) hold the potential to significantly enhance this discovery process in realistic workflows. However, current scientific benchmarks mostly focus on evaluating the knowledge understanding capabilities of MLLMs, leading to an inadequate assessment of their perception and reasoning abilities. To address this gap, we present the Scientists' First Exam (SFE) benchmark, designed to evaluate the scientific cognitive capacities of MLLMs through three interconnected levels: scientific signal perception, scientific attribute understanding, scientific comparative reasoning. Specifically, SFE comprises 830 expert-verified VQA pairs across three question types, spanning 66 multimodal tasks across five high-value disciplines. Extensive experiments reveal that current state-of-the-art GPT-o3 and InternVL-3 achieve only 34.08% and 26.52% on SFE, highlighting significant room for MLLMs to improve in scientific realms. We hope the insights obtained in SFE will facilitate further developments in AI-enhanced scientific discoveries.
RadSplatter: Extending 3D Gaussian Splatting to Radio Frequencies for Wireless Radiomap Extrapolation
Feb 18, 2025A radiomap represents the spatial distribution of wireless signal strength, critical for applications like network optimization and autonomous driving. However, constructing radiomap relies on measuring radio signal power across the entire system, which is costly in outdoor environments due to large network scales. We present RadSplatter, a framework that extends 3D Gaussian Splatting (3DGS) to radio frequencies for efficient and accurate radiomap extrapolation from sparse measurements. RadSplatter models environmental scatterers and radio paths using 3D Gaussians, capturing key factors of radio wave propagation. It employs a relaxed-mean (RM) scheme to reparameterize the positions of 3D Gaussians from noisy and dense 3D point clouds. A camera-free 3DGS-based projection is proposed to map 3D Gaussians onto 2D radio beam patterns. Furthermore, a regularized loss function and recursive fine-tuning using highly structured sparse measurements in real-world settings are applied to ensure robust generalization. Experiments on synthetic and real-world data show state-of-the-art extrapolation accuracy and execution speed.
Prompt-Driven Temporal Domain Adaptation for Nighttime UAV Tracking
Sep 27, 2024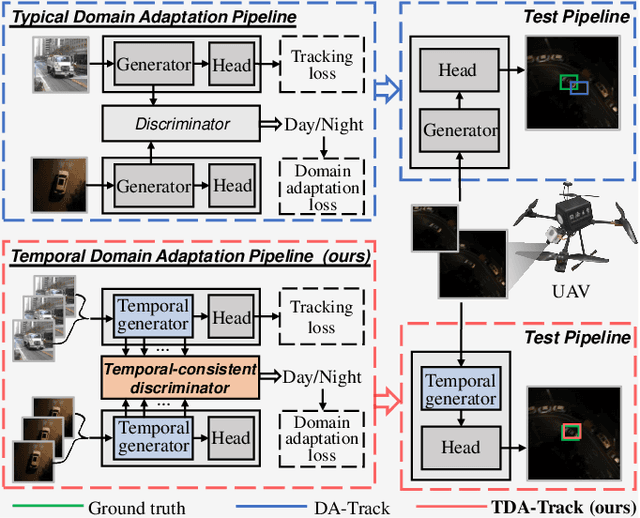

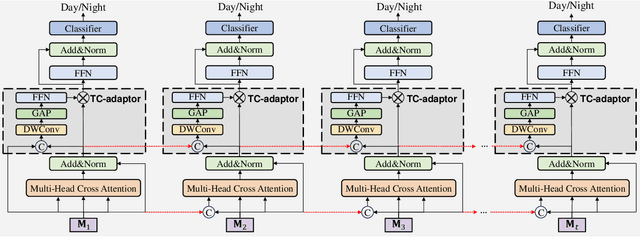

Nighttime UAV tracking under low-illuminated scenarios has achieved great progress by domain adaptation (DA). However, previous DA training-based works are deficient in narrowing the discrepancy of temporal contexts for UAV trackers. To address the issue, this work proposes a prompt-driven temporal domain adaptation training framework to fully utilize temporal contexts for challenging nighttime UAV tracking, i.e., TDA. Specifically, the proposed framework aligns the distribution of temporal contexts from daytime and nighttime domains by training the temporal feature generator against the discriminator. The temporal-consistent discriminator progressively extracts shared domain-specific features to generate coherent domain discrimination results in the time series. Additionally, to obtain high-quality training samples, a prompt-driven object miner is employed to precisely locate objects in unannotated nighttime videos. Moreover, a new benchmark for long-term nighttime UAV tracking is constructed. Exhaustive evaluations on both public and self-constructed nighttime benchmarks demonstrate the remarkable performance of the tracker trained in TDA framework, i.e., TDA-Track. Real-world tests at nighttime also show its practicality. The code and demo videos are available at https://github.com/vision4robotics/TDA-Track.
Enhancing Nighttime UAV Tracking with Light Distribution Suppression
Sep 25, 2024Visual object tracking has boosted extensive intelligent applications for unmanned aerial vehicles (UAVs). However, the state-of-the-art (SOTA) enhancers for nighttime UAV tracking always neglect the uneven light distribution in low-light images, inevitably leading to excessive enhancement in scenarios with complex illumination. To address these issues, this work proposes a novel enhancer, i.e., LDEnhancer, enhancing nighttime UAV tracking with light distribution suppression. Specifically, a novel image content refinement module is developed to decompose the light distribution information and image content information in the feature space, allowing for the targeted enhancement of the image content information. Then this work designs a new light distribution generation module to capture light distribution effectively. The features with light distribution information and image content information are fed into the different parameter estimation modules, respectively, for the parameter map prediction. Finally, leveraging two parameter maps, an innovative interweave iteration adjustment is proposed for the collaborative pixel-wise adjustment of low-light images. Additionally, a challenging nighttime UAV tracking dataset with uneven light distribution, namely NAT2024-2, is constructed to provide a comprehensive evaluation, which contains 40 challenging sequences with over 74K frames in total. Experimental results on the authoritative UAV benchmarks and the proposed NAT2024-2 demonstrate that LDEnhancer outperforms other SOTA low-light enhancers for nighttime UAV tracking. Furthermore, real-world tests on a typical UAV platform with an NVIDIA Orin NX confirm the practicality and efficiency of LDEnhancer. The code is available at https://github.com/vision4robotics/LDEnhancer.
A Comparative Study of Pre-training and Self-training
Sep 04, 2024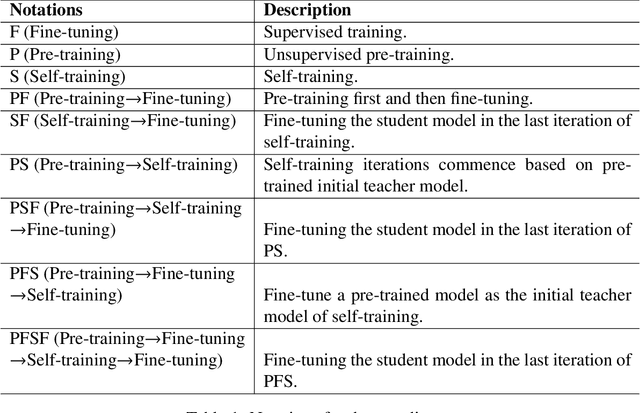

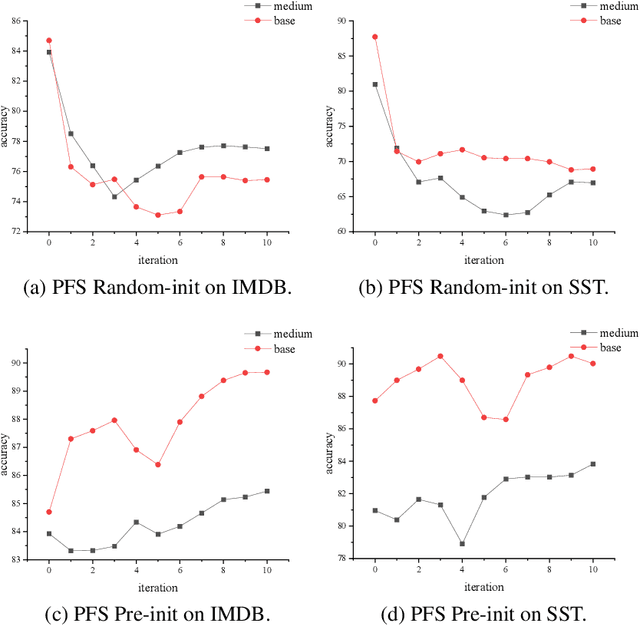
Pre-training and self-training are two approaches to semi-supervised learning. The comparison between pre-training and self-training has been explored. However, the previous works led to confusing findings: self-training outperforms pre-training experienced on some tasks in computer vision, and contrarily, pre-training outperforms self-training experienced on some tasks in natural language processing, under certain conditions of incomparable settings. We propose, comparatively and exhaustively, an ensemble method to empirical study all feasible training paradigms combining pre-training, self-training, and fine-tuning within consistent foundational settings comparable to data augmentation. We conduct experiments on six datasets, four data augmentation, and imbalanced data for sentiment analysis and natural language inference tasks. Our findings confirm that the pre-training and fine-tuning paradigm yields the best overall performances. Moreover, self-training offers no additional benefits when combined with semi-supervised pre-training.
Surgical tool classification and localization: results and methods from the MICCAI 2022 SurgToolLoc challenge
May 11, 2023



The ability to automatically detect and track surgical instruments in endoscopic videos can enable transformational interventions. Assessing surgical performance and efficiency, identifying skilled tool use and choreography, and planning operational and logistical aspects of OR resources are just a few of the applications that could benefit. Unfortunately, obtaining the annotations needed to train machine learning models to identify and localize surgical tools is a difficult task. Annotating bounding boxes frame-by-frame is tedious and time-consuming, yet large amounts of data with a wide variety of surgical tools and surgeries must be captured for robust training. Moreover, ongoing annotator training is needed to stay up to date with surgical instrument innovation. In robotic-assisted surgery, however, potentially informative data like timestamps of instrument installation and removal can be programmatically harvested. The ability to rely on tool installation data alone would significantly reduce the workload to train robust tool-tracking models. With this motivation in mind we invited the surgical data science community to participate in the challenge, SurgToolLoc 2022. The goal was to leverage tool presence data as weak labels for machine learning models trained to detect tools and localize them in video frames with bounding boxes. We present the results of this challenge along with many of the team's efforts. We conclude by discussing these results in the broader context of machine learning and surgical data science. The training data used for this challenge consisting of 24,695 video clips with tool presence labels is also being released publicly and can be accessed at https://console.cloud.google.com/storage/browser/isi-surgtoolloc-2022.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
BigDL: A Distributed Deep Learning Framework for Big Data
Jun 25, 2018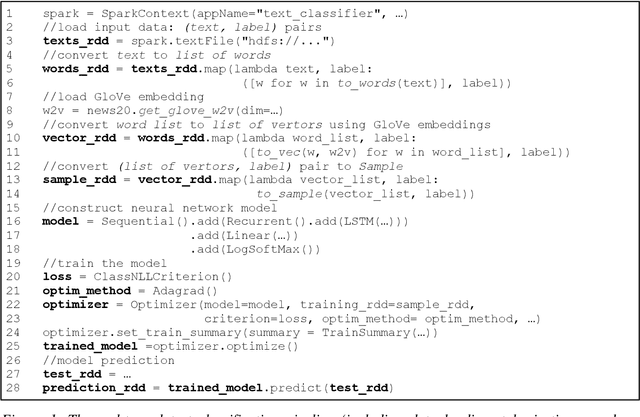
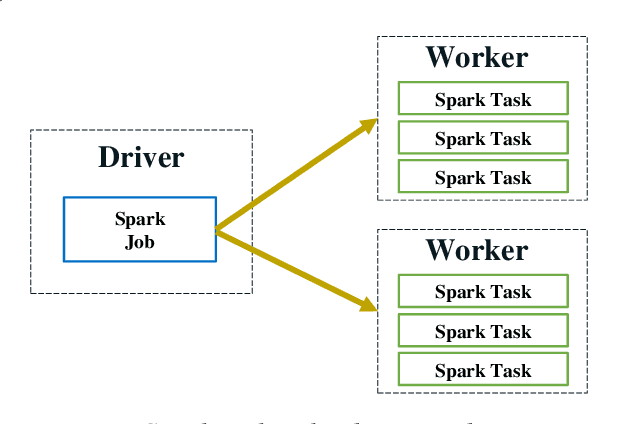

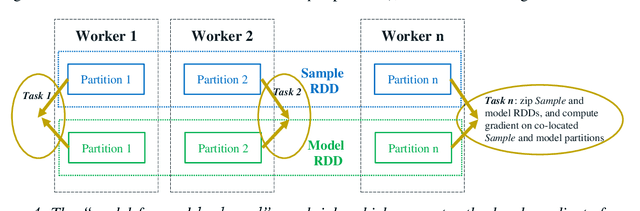
In this paper, we present BigDL, a distributed deep learning framework for Big Data platforms and workflows. It is implemented on top of Apache Spark, and allows users to write their deep learning applications as standard Spark programs (running directly on large-scale big data clusters in a distributed fashion). It provides an expressive, "data-analytics integrated" deep learning programming model, so that users can easily build the end-to-end analytics + AI pipelines under a unified programming paradigm; by implementing an AllReduce like operation using existing primitives in Spark (e.g., shuffle, broadcast, and in-memory data persistence), it also provides a highly efficient "parameter server" style architecture, so as to achieve highly scalable, data-parallel distributed training. Since its initial open source release, BigDL users have built many analytics and deep learning applications (e.g., object detection, sequence-to-sequence generation, visual similarity, neural recommendations, fraud detection, etc.) on Spark.
Multi-Scale DenseNet-Based Electricity Theft Detection
May 24, 2018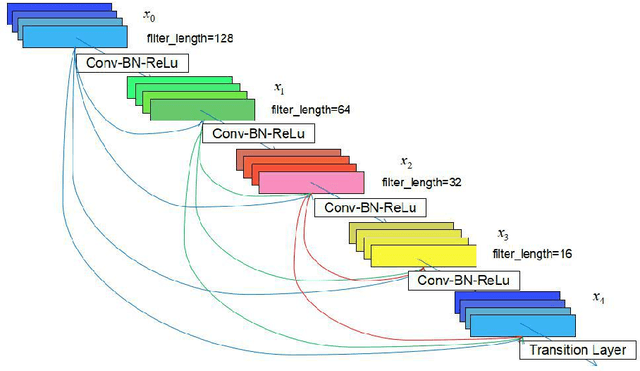
Electricity theft detection issue has drawn lots of attention during last decades. Timely identification of the electricity theft in the power system is crucial for the safety and availability of the system. Although sustainable efforts have been made, the detection task remains challenging and falls short of accuracy and efficiency, especially with the increase of the data size. Recently, convolutional neural network-based methods have achieved better performance in comparison with traditional methods, which employ handcrafted features and shallow-architecture classifiers. In this paper, we present a novel approach for automatic detection by using a multi-scale dense connected convolution neural network (multi-scale DenseNet) in order to capture the long-term and short-term periodic features within the sequential data. We compare the proposed approaches with the classical algorithms, and the experimental results demonstrate that the multiscale DenseNet approach can significantly improve the accuracy of the detection. Moreover, our method is scalable, enabling larger data processing while no handcrafted feature engineering is needed.