 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAP: Accelerating Large-Scale DNN Training Through Tensor Automatic Parallelisation
Feb 01, 2023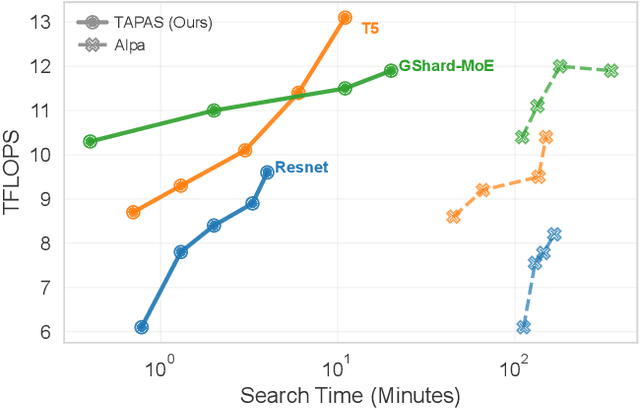

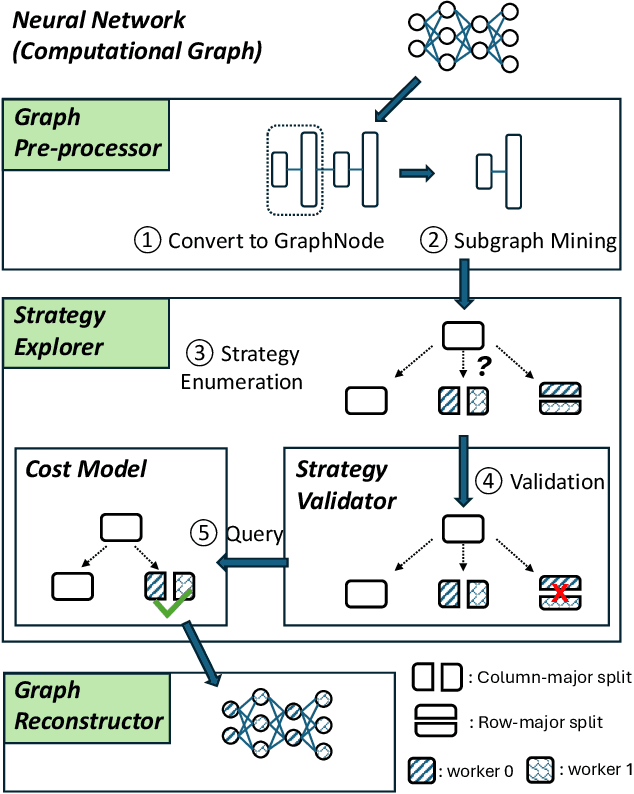
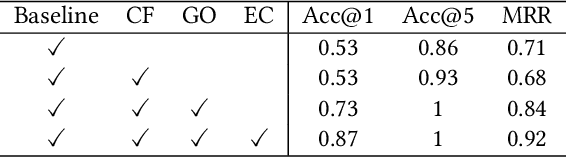
Model parallelism has become necessary to train large neural networks. However, finding a suitable model parallel schedule for an arbitrary neural network is a non-trivial task due to the exploding search space. In this work, we present a model parallelism framework TAP that automatically searches for the best data and tensor parallel schedules. Leveraging the key insight that a neural network can be represented as a directed acyclic graph, within which may only exist a limited set of frequent subgraphs, we design a graph pruning algorithm to fold the search space efficiently. TAP runs at sub-linear complexity concerning the neural network size. Experiments show that TAP is $20\times- 160\times$ faster than the state-of-the-art automatic parallelism framework, and the performance of its discovered schedules is competitive with the expert-engineered ones.
M6-10T: A Sharing-Delinking Paradigm for Efficient Multi-Trillion Parameter Pretraining
Oct 25, 2021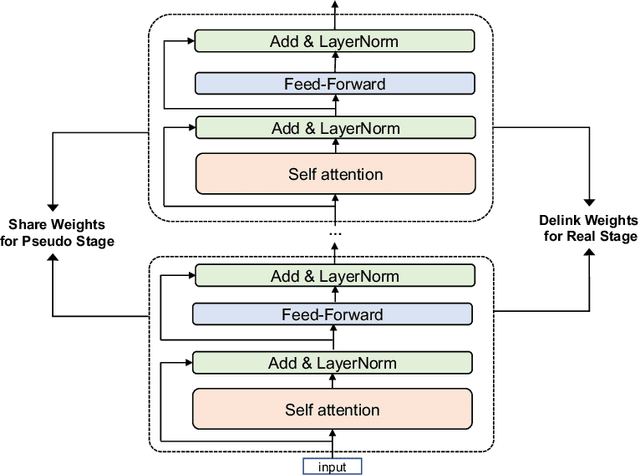

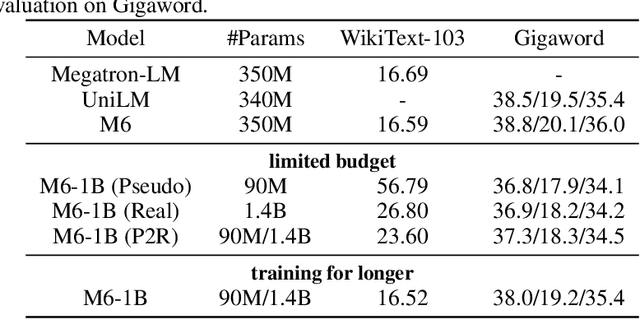
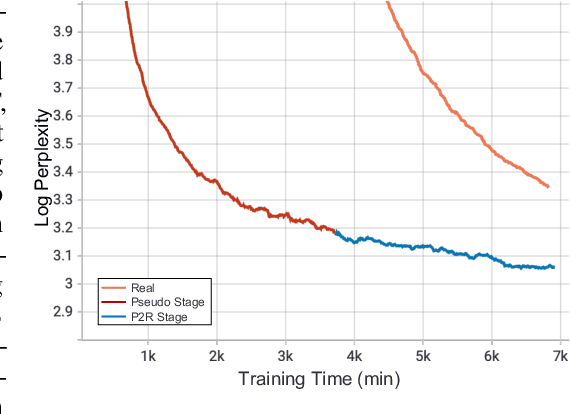
Recent expeditious developments in deep learning algorithms, distributed training, and even hardware design for large models have enabled training extreme-scale models, say GPT-3 and Switch Transformer possessing hundreds of billions or even trillions of parameters. However, under limited resources, extreme-scale model training that requires enormous amounts of computes and memory footprint suffers from frustratingly low efficiency in model convergence. In this paper, we propose a simple training strategy called "Pseudo-to-Real" for high-memory-footprint-required large models. Pseudo-to-Real is compatible with large models with architecture of sequential layers. We demonstrate a practice of pretraining unprecedented 10-trillion-parameter model, an order of magnitude larger than the state-of-the-art, on solely 512 GPUs within 10 days. Besides demonstrating the application of Pseudo-to-Real, we also provide a technique, Granular CPU offloading, to manage CPU memory for training large model and maintain high GPU utilities. Fast training of extreme-scale models on a decent amount of resources can bring much smaller carbon footprint and contribute to greener AI.
Exploring Sparse Expert Models and Beyond
Jun 14, 2021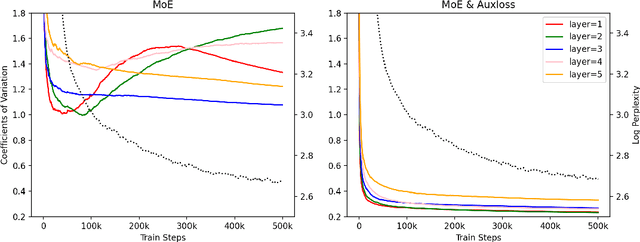

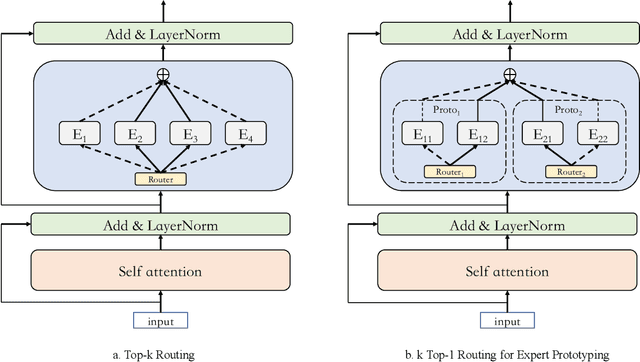
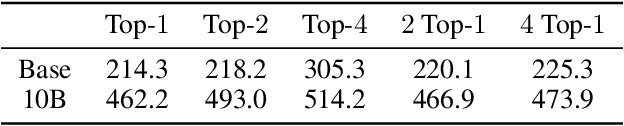
Mixture-of-Experts (MoE) models can achieve promising results with outrageous large amount of parameters but constant computation cost, and thus it has become a trend in model scaling. Still it is a mystery how MoE layers bring quality gains by leveraging the parameters with sparse activation. In this work, we investigate several key factors in sparse expert models. We observe that load imbalance may not be a significant problem affecting model quality, contrary to the perspectives of recent studies, while the number of sparsely activated experts $k$ and expert capacity $C$ in top-$k$ routing can significantly make a difference in this context. Furthermore, we take a step forward to propose a simple method called expert prototyping that splits experts into different prototypes and applies $k$ top-$1$ routing. This strategy improves the model quality but maintains constant computational costs, and our further exploration on extremely large-scale models reflects that it is more effective in training larger models. We push the model scale to over $1$ trillion parameters and implement it on solely $480$ NVIDIA V100-32GB GPUs, in comparison with the recent SOTAs on $2048$ TPU cores. The proposed giant model achieves substantial speedup in convergence over the same-size baseline.
M6: A Chinese Multimodal Pretrainer
Mar 02, 2021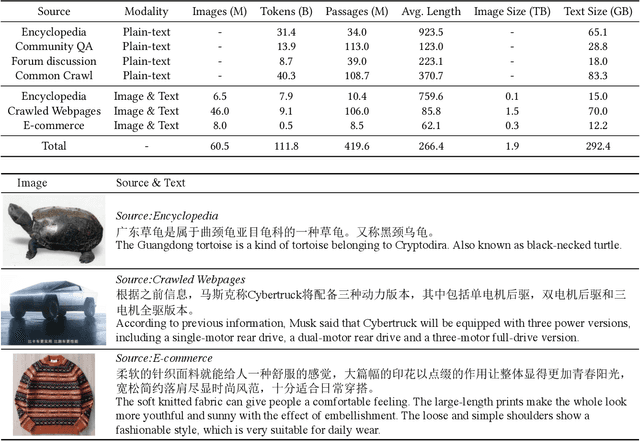
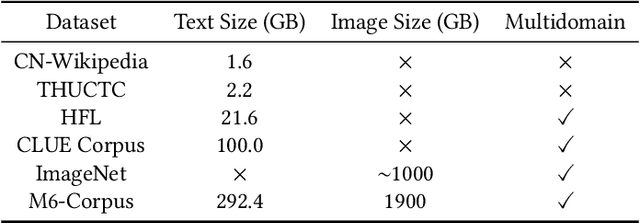

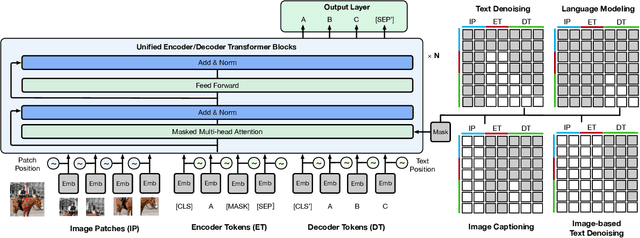
In this work, we construct the largest dataset for multimodal pretraining in Chinese, which consists of over 1.9TB images and 292GB texts that cover a wide range of domains. We propose a cross-modal pretraining method called M6, referring to Multi-Modality to Multi-Modality Multitask Mega-transformer, for unified pretraining on the data of single modality and multiple modalities. We scale the model size up to 10 billion and 100 billion parameters, and build the largest pretrained model in Chinese. We apply the model to a series of downstream applications, and demonstrate its outstanding performance in comparison with strong baselines. Furthermore, we specifically design a downstream task of text-guided image generation, and show that the finetuned M6 can create high-quality images with high resolution and abundant details.
Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in Four Minutes
Jul 30, 2018
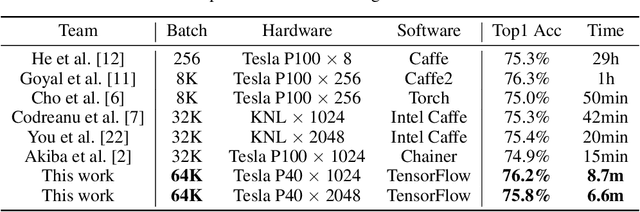

Synchronized stochastic gradient descent (SGD) optimizers with data parallelism are widely used in training large-scale deep neural networks. Although using larger mini-batch sizes can improve the system scalability by reducing the communication-to-computation ratio, it may hurt the generalization ability of the models. To this end, we build a highly scalable deep learning training system for dense GPU clusters with three main contributions: (1) We propose a mixed-precision training method that significantly improves the training throughput of a single GPU without losing accuracy. (2) We propose an optimization approach for extremely large mini-batch size (up to 64k) that can train CNN models on the ImageNet dataset without losing accuracy. (3) We propose highly optimized all-reduce algorithms that achieve up to 3x and 11x speedup on AlexNet and ResNet-50 respectively than NCCL-based training on a cluster with 1024 Tesla P40 GPUs. On training ResNet-50 with 90 epochs, the state-of-the-art GPU-based system with 1024 Tesla P100 GPUs spent 15 minutes and achieved 74.9\% top-1 test accuracy, and another KNL-based system with 2048 Intel KNLs spent 20 minutes and achieved 75.4\% accuracy. Our training system can achieve 75.8\% top-1 test accuracy in only 6.6 minutes using 2048 Tesla P40 GPUs. When training AlexNet with 95 epochs, our system can achieve 58.7\% top-1 test accuracy within 4 minutes, which also outperforms all other existing systems.
BigDL: A Distributed Deep Learning Framework for Big Data
Jun 25, 2018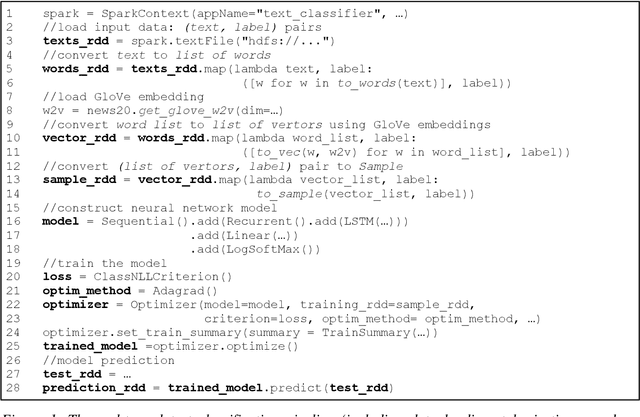
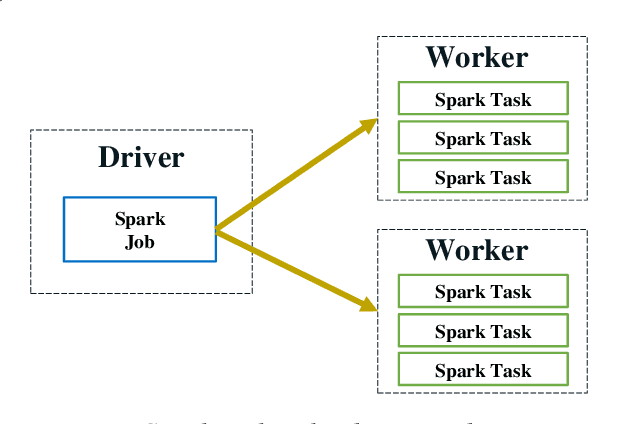

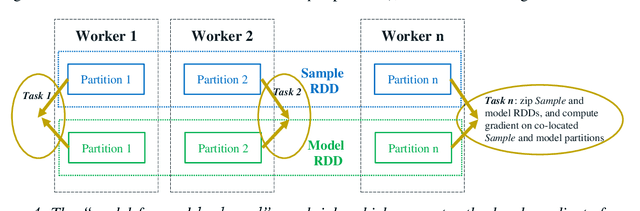
In this paper, we present BigDL, a distributed deep learning framework for Big Data platforms and workflows. It is implemented on top of Apache Spark, and allows users to write their deep learning applications as standard Spark programs (running directly on large-scale big data clusters in a distributed fashion). It provides an expressive, "data-analytics integrated" deep learning programming model, so that users can easily build the end-to-end analytics + AI pipelines under a unified programming paradigm; by implementing an AllReduce like operation using existing primitives in Spark (e.g., shuffle, broadcast, and in-memory data persistence), it also provides a highly efficient "parameter server" style architecture, so as to achieve highly scalable, data-parallel distributed training. Since its initial open source release, BigDL users have built many analytics and deep learning applications (e.g., object detection, sequence-to-sequence generation, visual similarity, neural recommendations, fraud detection, etc.) on Spark.
Sentiment Analysis for Twitter : Going Beyond Tweet Text
Nov 29, 2016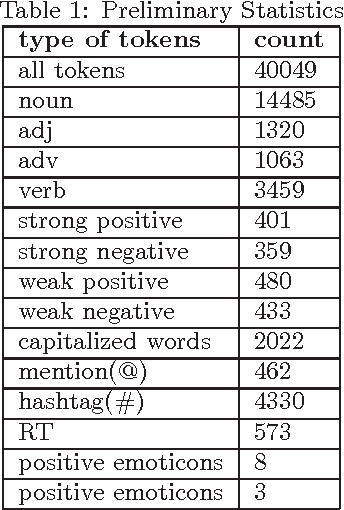


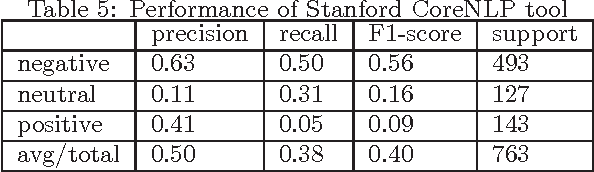
Analysing sentiment of tweets is important as it helps to determine the users' opinion. Knowing people's opinion is crucial for several purposes starting from gathering knowledge about customer base, e-governance, campaigning and many more. In this report, we aim to develop a system to detect the sentiment from tweets. We employ several linguistic features along with some other external sources of information to detect the sentiment of a tweet. We show that augmenting the 140 character-long tweet with information harvested from external urls shared in the tweet as well as Social Media features enhances the sentiment prediction accuracy significantly.