 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaGAN: A Scalable Distributed Training Framework for Generative Adversarial Networks
Nov 06, 2024
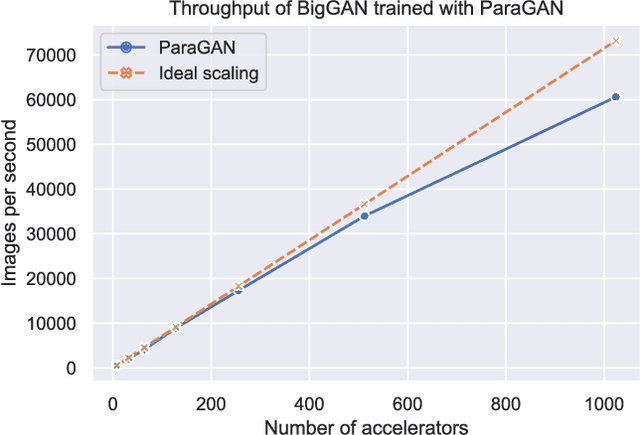
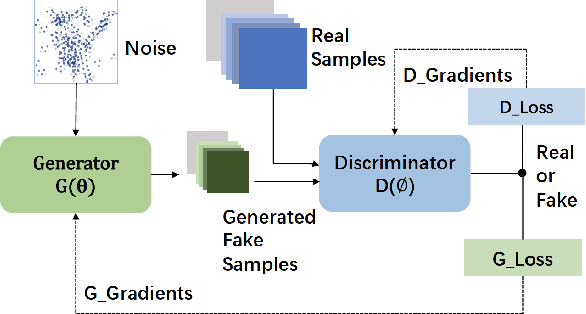
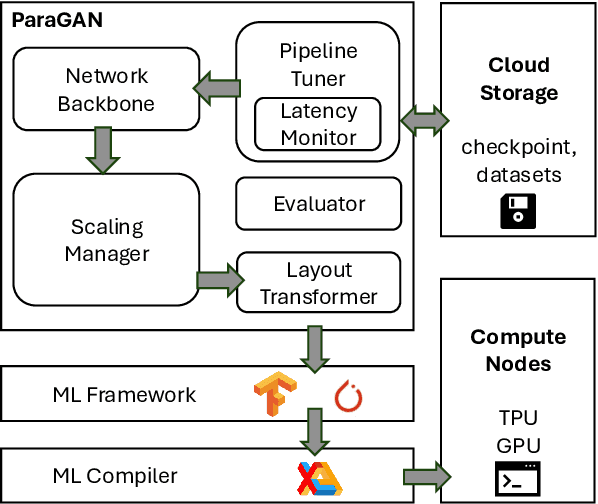
Recent advances in Generative Artificial Intelligence have fueled numerous applications, particularly those involving Generative Adversarial Networks (GANs), which are essential for synthesizing realistic photos and videos. However, efficiently training GANs remains a critical challenge due to their computationally intensive and numerically unstable nature. Existing methods often require days or even weeks for training, posing significant resource and time constraints. In this work, we introduce ParaGAN, a scalable distributed GAN training framework that leverages asynchronous training and an asymmetric optimization policy to accelerate GAN training. ParaGAN employs a congestion-aware data pipeline and hardware-aware layout transformation to enhance accelerator utilization, resulting in over 30% improvements in throughput. With ParaGAN, we reduce the training time of BigGAN from 15 days to 14 hours while achieving 91% scaling efficiency. Additionally, ParaGAN enables unprecedented high-resolution image generation using BigGAN.
ROAM: memory-efficient large DNN training via optimized operator ordering and memory layout
Oct 30, 2023



As deep learning models continue to increase in size, the memory requirements for training have surged. While high-level techniques like offloading, recomputation, and compression can alleviate memory pressure, they also introduce overheads. However, a memory-efficient execution plan that includes a reasonable operator execution order and tensor memory layout can significantly increase the models' memory efficiency and reduce overheads from high-level techniques. In this paper, we propose ROAM which operates on computation graph level to derive memory-efficient execution plan with optimized operator order and tensor memory layout for models. We first propose sophisticated theories that carefully consider model structure and training memory load to support optimization for large complex graphs that have not been well supported in the past. An efficient tree-based algorithm is further proposed to search task divisions automatically, along with delivering high performance and effectiveness to solve the problem. Experiments show that ROAM achieves a substantial memory reduction of 35.7%, 13.3%, and 27.2% compared to Pytorch and two state-of-the-art methods and offers a remarkable 53.7x speedup. The evaluation conducted on the expansive GPT2-XL further validates ROAM's scalability.
Auto-Parallelizing Large Models with Rhino: A Systematic Approach on Production AI Platform
Feb 16, 2023



We present Rhino, a system for accelerating tensor programs with automatic parallelization on AI platform for real production environment. It transforms a tensor program written for a single device into an equivalent distributed program that is capable of scaling up to thousands of devices with no user configuration. Rhino firstly works on a semantically independent intermediate representation of tensor programs, which facilitates its generalization to unprecedented applications. Additionally, it implements a task-oriented controller and a distributed runtime for optimal performance. Rhino explores on a complete and systematic parallelization strategy space that comprises all the paradigms commonly employed in deep learning (DL), in addition to strided partitioning and pipeline parallelism on non-linear models. Aiming to efficiently search for a near-optimal parallel execution plan, our analysis of production clusters reveals general heuristics to speed up the strategy search. On top of it, two optimization levels are designed to offer users flexible trade-offs between the search time and strategy quality. Our experiments demonstrate that Rhino can not only re-discover the expert-crafted strategies of classic, research and production DL models, but also identify novel parallelization strategies which surpass existing systems for novel models.
TAP: Accelerating Large-Scale DNN Training Through Tensor Automatic Parallelisation
Feb 01, 2023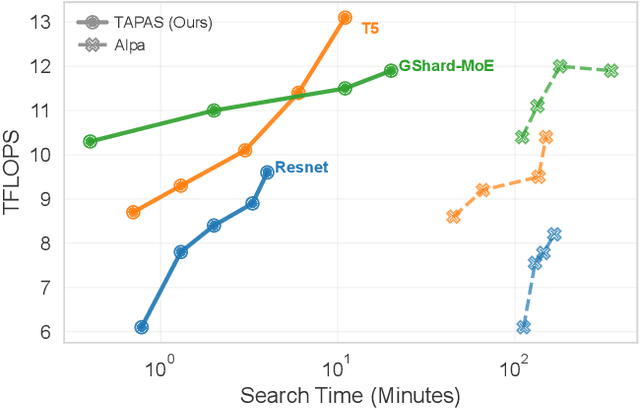

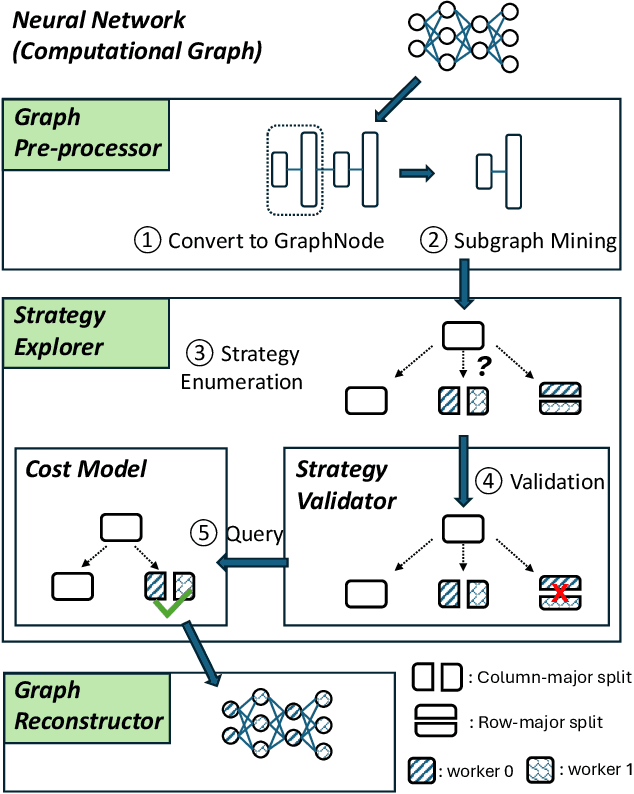
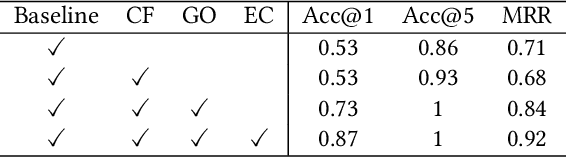
Model parallelism has become necessary to train large neural networks. However, finding a suitable model parallel schedule for an arbitrary neural network is a non-trivial task due to the exploding search space. In this work, we present a model parallelism framework TAP that automatically searches for the best data and tensor parallel schedules. Leveraging the key insight that a neural network can be represented as a directed acyclic graph, within which may only exist a limited set of frequent subgraphs, we design a graph pruning algorithm to fold the search space efficiently. TAP runs at sub-linear complexity concerning the neural network size. Experiments show that TAP is $20\times- 160\times$ faster than the state-of-the-art automatic parallelism framework, and the performance of its discovered schedules is competitive with the expert-engineered ones.
Go Wider Instead of Deeper
Jul 29, 2021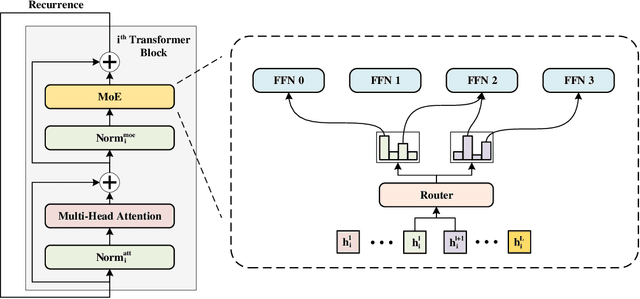
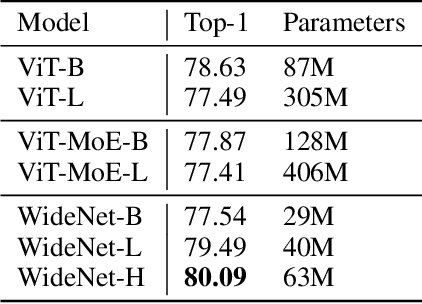
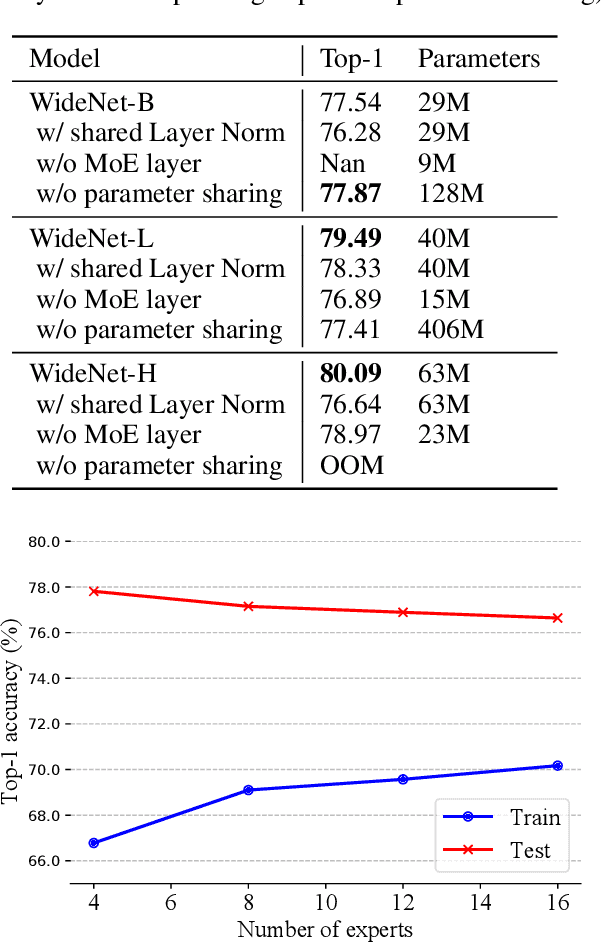
The transformer has recently achieved impressive results on various tasks. To further improve the effectiveness and efficiency of the transformer, there are two trains of thought among existing works: (1) going wider by scaling to more trainable parameters; (2) going shallower by parameter sharing or model compressing along with the depth. However, larger models usually do not scale well when fewer tokens are available to train, and advanced parallelisms are required when the model is extremely large. Smaller models usually achieve inferior performance compared to the original transformer model due to the loss of representation power. In this paper, to achieve better performance with fewer trainable parameters, we propose a framework to deploy trainable parameters efficiently, by going wider instead of deeper. Specially, we scale along model width by replacing feed-forward network (FFN) with mixture-of-experts (MoE). We then share the MoE layers across transformer blocks using individual layer normalization. Such deployment plays the role to transform various semantic representations, which makes the model more parameter-efficient and effective. To evaluate our framework, we design WideNet and evaluate it on ImageNet-1K. Our best model outperforms Vision Transformer (ViT) by $1.46\%$ with $0.72 \times$ trainable parameters. Using $0.46 \times$ and $0.13 \times$ parameters, our WideNet can still surpass ViT and ViT-MoE by $0.83\%$ and $2.08\%$, respectively.
A Collision-Free Path Planning Algorithm for Unmanned Aerial Vehicle Delivery
May 09, 2018



Path planning is important for the autonomy of Unmanned Aerial Vehicle (UAV), especially for scheduling UAV delivery. However, the operating environment of UAVs is usually uncertain and dynamic. Without proper planning, collisions may happen where multiple UAVs are congested. Besides, there may also be temporary no-fly zone setup by authorities that makes airspace unusable. Thus, proper pre-departure planning that avoids such places is needed. In this paper, we formulate this problem into a Constraint Satisfaction Problem to find a collision-free shortest path on a dynamic graph. We propose a collision-free path planning algorithm that is based on A* algorithm. The main novelty is that we invent a heuristic function that also considers waiting time. We later show that, with added waiting penalty, the proposed algorithm is optimal because the heuristic is admissible. Implementation of this algorithm simulates UAV delivery using Singapore's airspace structure. Our simulation exhibits desirable runtime performance. Using the proposed algorithm, the percentage of collision-free routes decreases as number of requests per unit area increases, and this percentage drops significantly at boundary value. Our empirical analysis could aid the decision-making of no-fly zone policy and infrastructure of UAV delivery.