 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Fourier-enhanced neural operator for efficient modeling of radiation transfer in fires
Apr 15, 2026Computational fluid dynamics (CFD) has become an essential tool for predicting fire behavior, yet maintaining both efficiency and accuracy remains challenging. A major source of computational cost in fire simulations is the modeling of radiation transfer, which is usually the dominant heat transfer mechanism in fires. Solving the high-dimensional radiative transfer equation (RTE) with traditional numerical methods can be a performance bottleneck. Here, we present a machine learning framework based on Fourier-enhanced multiple-input neural operators (Fourier-MIONet) as an efficient alternative to direct numerical integration of the RTE. We first investigate the performance of neural operator architectures for a small-scale 2D pool fire and find that Fourier-MIONet provides the most accurate radiative solution predictions. The approach is then extended to 3D CFD fire simulations, where the computational mesh is locally refined across multiple levels. In these high-resolution settings, monolithic surrogate models for direct field-to-field mapping become difficult to train and computationally inefficient. To address this issue, a nested Fourier-MIONet is proposed to predict radiation solutions across multiple mesh-refinement levels. We validate the approach on 3D McCaffrey pool fires simulated with FireFOAM, including fixed fire sizes and a unified model trained over a continuous range of heat release rates (HRRs). The proposed method achieves global relative errors of 2-4% for 3D varying-HRR scenarios while providing faster inference than the estimated cost of one finite-volume radiation solve in FireFOAM for the 16-solid-angle case. With fast and accurate inference, the surrogate makes higher-fidelity radiation treatments practical and enables the incorporation of more spectrally resolved radiation models into CFD fire simulations for engineering applications.
Q Cache: Visual Attention is Valuable in Less than Half of Decode Layers for Multimodal Large Language Model
Feb 02, 2026Multimodal large language models (MLLMs) are plagued by exorbitant inference costs attributable to the profusion of visual tokens within the vision encoder. The redundant visual tokens engenders a substantial computational load and key-value (KV) cache footprint bottleneck. Existing approaches focus on token-wise optimization, leveraging diverse intricate token pruning techniques to eliminate non-crucial visual tokens. Nevertheless, these methods often unavoidably undermine the integrity of the KV cache, resulting in failures in long-text generation tasks. To this end, we conduct an in-depth investigation towards the attention mechanism of the model from a new perspective, and discern that attention within more than half of all decode layers are semantic similar. Upon this finding, we contend that the attention in certain layers can be streamlined by inheriting the attention from their preceding layers. Consequently, we propose Lazy Attention, an efficient attention mechanism that enables cross-layer sharing of similar attention patterns. It ingeniously reduces layer-wise redundant computation in attention. In Lazy Attention, we develop a novel layer-shared cache, Q Cache, tailored for MLLMs, which facilitates the reuse of queries across adjacent layers. In particular, Q Cache is lightweight and fully compatible with existing inference frameworks, including Flash Attention and KV cache. Additionally, our method is highly flexible as it is orthogonal to existing token-wise techniques and can be deployed independently or combined with token pruning approaches. Empirical evaluations on multiple benchmarks demonstrate that our method can reduce KV cache usage by over 35% and achieve 1.5x throughput improvement, while sacrificing only approximately 1% of performance on various MLLMs. Compared with SOTA token-wise methods, our technique achieves superior accuracy preservation.
PI-MFM: Physics-informed multimodal foundation model for solving partial differential equations
Dec 28, 2025Partial differential equations (PDEs) govern a wide range of physical systems, and recent multimodal foundation models have shown promise for learning PDE solution operators across diverse equation families. However, existing multi-operator learning approaches are data-hungry and neglect physics during training. Here, we propose a physics-informed multimodal foundation model (PI-MFM) framework that directly enforces governing equations during pretraining and adaptation. PI-MFM takes symbolic representations of PDEs as the input, and automatically assembles PDE residual losses from the input expression via a vectorized derivative computation. These designs enable any PDE-encoding multimodal foundation model to be trained or adapted with unified physics-informed objectives across equation families. On a benchmark of 13 parametric one-dimensional time-dependent PDE families, PI-MFM consistently outperforms purely data-driven counterparts, especially with sparse labeled spatiotemporal points, partially observed time domains, or few labeled function pairs. Physics losses further improve robustness against noise, and simple strategies such as resampling collocation points substantially improve accuracy. We also analyze the accuracy, precision, and computational cost of automatic differentiation and finite differences for derivative computation within PI-MFM. Finally, we demonstrate zero-shot physics-informed fine-tuning to unseen PDE families: starting from a physics-informed pretrained model, adapting using only PDE residuals and initial/boundary conditions, without any labeled solution data, rapidly reduces test errors to around 1% and clearly outperforms physics-only training from scratch. These results show that PI-MFM provides a practical and scalable path toward data-efficient, transferable PDE solvers.
MedBench v4: A Robust and Scalable Benchmark for Evaluating Chinese Medical Language Models, Multimodal Models, and Intelligent Agents
Nov 19, 2025Recent advances in medical large language models (LLMs), multimodal models, and agents demand evaluation frameworks that reflect real clinical workflows and safety constraints. We present MedBench v4, a nationwide, cloud-based benchmarking infrastructure comprising over 700,000 expert-curated tasks spanning 24 primary and 91 secondary specialties, with dedicated tracks for LLMs, multimodal models, and agents. Items undergo multi-stage refinement and multi-round review by clinicians from more than 500 institutions, and open-ended responses are scored by an LLM-as-a-judge calibrated to human ratings. We evaluate 15 frontier models. Base LLMs reach a mean overall score of 54.1/100 (best: Claude Sonnet 4.5, 62.5/100), but safety and ethics remain low (18.4/100). Multimodal models perform worse overall (mean 47.5/100; best: GPT-5, 54.9/100), with solid perception yet weaker cross-modal reasoning. Agents built on the same backbones substantially improve end-to-end performance (mean 79.8/100), with Claude Sonnet 4.5-based agents achieving up to 85.3/100 overall and 88.9/100 on safety tasks. MedBench v4 thus reveals persisting gaps in multimodal reasoning and safety for base models, while showing that governance-aware agentic orchestration can markedly enhance benchmarked clinical readiness without sacrificing capability. By aligning tasks with Chinese clinical guidelines and regulatory priorities, the platform offers a practical reference for hospitals, developers, and policymakers auditing medical AI.
TCM-5CEval: Extended Deep Evaluation Benchmark for LLM's Comprehensive Clinical Research Competence in Traditional Chinese Medicine
Nov 17, 2025Large language models (LLMs) have demonstrated exceptional capabilities in general domains, yet their application in highly specialized and culturally-rich fields like Traditional Chinese Medicine (TCM) requires rigorous and nuanced evaluation. Building upon prior foundational work such as TCM-3CEval, which highlighted systemic knowledge gaps and the importance of cultural-contextual alignment, we introduce TCM-5CEval, a more granular and comprehensive benchmark. TCM-5CEval is designed to assess LLMs across five critical dimensions: (1) Core Knowledge (TCM-Exam), (2) Classical Literacy (TCM-LitQA), (3) Clinical Decision-making (TCM-MRCD), (4) Chinese Materia Medica (TCM-CMM), and (5) Clinical Non-pharmacological Therapy (TCM-ClinNPT). We conducted a thorough evaluation of fifteen prominent LLMs, revealing significant performance disparities and identifying top-performing models like deepseek\_r1 and gemini\_2\_5\_pro. Our findings show that while models exhibit proficiency in recalling foundational knowledge, they struggle with the interpretative complexities of classical texts. Critically, permutation-based consistency testing reveals widespread fragilities in model inference. All evaluated models, including the highest-scoring ones, displayed a substantial performance degradation when faced with varied question option ordering, indicating a pervasive sensitivity to positional bias and a lack of robust understanding. TCM-5CEval not only provides a more detailed diagnostic tool for LLM capabilities in TCM but aldso exposes fundamental weaknesses in their reasoning stability. To promote further research and standardized comparison, TCM-5CEval has been uploaded to the Medbench platform, joining its predecessor in the "In-depth Challenge for Comprehensive TCM Abilities" special track.
ParaS2S: Benchmarking and Aligning Spoken Language Models for Paralinguistic-aware Speech-to-Speech Interaction
Nov 11, 2025Speech-to-Speech (S2S) models have shown promising dialogue capabilities, but their ability to handle paralinguistic cues--such as emotion, tone, and speaker attributes--and to respond appropriately in both content and style remains underexplored. Progress is further hindered by the scarcity of high-quality and expressive demonstrations. To address this, we introduce a novel reinforcement learning (RL) framework for paralinguistic-aware S2S, ParaS2S, which evaluates and optimizes both content and speaking style directly at the waveform level. We first construct ParaS2SBench, a benchmark comprehensively evaluates S2S models' output for content and style appropriateness from diverse and challenging input queries. It scores the fitness of input-output pairs and aligns well with human judgments, serving as an automatic judge for model outputs. With this scalable scoring feedback, we enable the model to explore and learn from diverse unlabeled speech via Group Relative Policy Optimization (GRPO). Experiments show that existing S2S models fail to respond appropriately to paralinguistic attributes, performing no better than pipeline-based baselines. Our RL approach achieves a 11% relative improvement in response content and style's appropriateness on ParaS2SBench over supervised fine-tuning (SFT), surpassing all prior models while requiring substantially fewer warm-up annotations than pure SFT.
DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
Aug 20, 2025We present DuPO, a dual learning-based preference optimization framework that generates annotation-free feedback via a generalized duality. DuPO addresses two key limitations: Reinforcement Learning with Verifiable Rewards (RLVR)'s reliance on costly labels and applicability restricted to verifiable tasks, and traditional dual learning's restriction to strictly dual task pairs (e.g., translation and back-translation). Specifically, DuPO decomposes a primal task's input into known and unknown components, then constructs its dual task to reconstruct the unknown part using the primal output and known information (e.g., reversing math solutions to recover hidden variables), broadening applicability to non-invertible tasks. The quality of this reconstruction serves as a self-supervised reward to optimize the primal task, synergizing with LLMs' ability to instantiate both tasks via a single model. Empirically, DuPO achieves substantial gains across diverse tasks: it enhances the average translation quality by 2.13 COMET over 756 directions, boosts the mathematical reasoning accuracy by an average of 6.4 points on three challenge benchmarks, and enhances performance by 9.3 points as an inference-time reranker (trading computation for accuracy). These results position DuPO as a scalable, general, and annotation-free paradigm for LLM optimization.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
FunDiff: Diffusion Models over Function Spaces for Physics-Informed Generative Modeling
Jun 09, 2025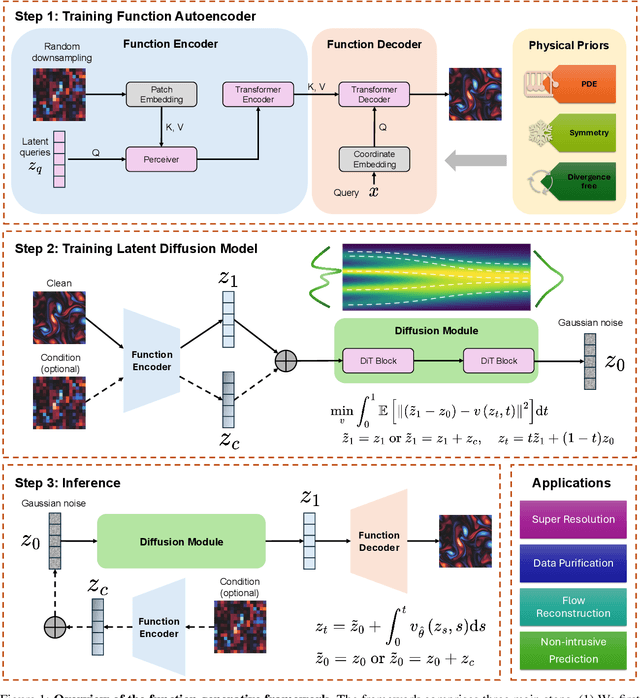
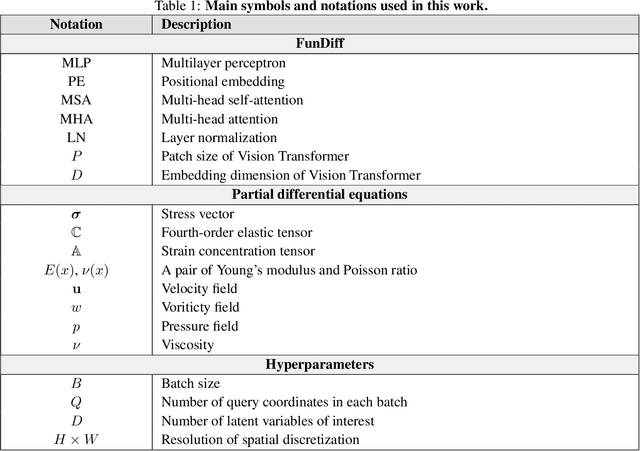
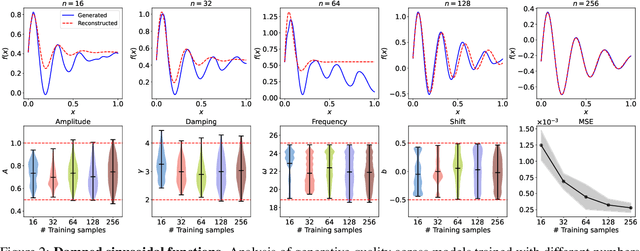
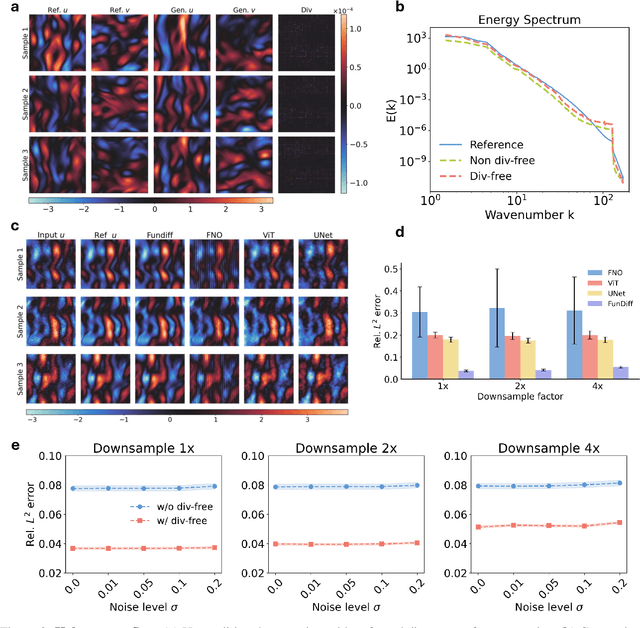
Recent advances in generative modeling -- particularly diffusion models and flow matching -- have achieved remarkable success in synthesizing discrete data such as images and videos. However, adapting these models to physical applications remains challenging, as the quantities of interest are continuous functions governed by complex physical laws. Here, we introduce $\textbf{FunDiff}$, a novel framework for generative modeling in function spaces. FunDiff combines a latent diffusion process with a function autoencoder architecture to handle input functions with varying discretizations, generate continuous functions evaluable at arbitrary locations, and seamlessly incorporate physical priors. These priors are enforced through architectural constraints or physics-informed loss functions, ensuring that generated samples satisfy fundamental physical laws. We theoretically establish minimax optimality guarantees for density estimation in function spaces, showing that diffusion-based estimators achieve optimal convergence rates under suitable regularity conditions. We demonstrate the practical effectiveness of FunDiff across diverse applications in fluid dynamics and solid mechanics. Empirical results show that our method generates physically consistent samples with high fidelity to the target distribution and exhibits robustness to noisy and low-resolution data. Code and datasets are publicly available at https://github.com/sifanexisted/fundiff.
Capacity-Optimized Pre-Equalizer Design for Visible Light Communication Systems
May 26, 2025Since commercial LEDs are primarily designed for illumination rather than data transmission, their modulation bandwidth is inherently limited to a few MHz. This becomes a major bottleneck in the implementation of visible light communication (VLC) systems necessiating the design of pre-equalizers. While state-of-the-art equalizer designs primarily focus on the data rate increasing through bandwidth expansion, they often overlook the accompanying degradation in signal-to-noise ratio (SNR). Achieving effective bandwidth extension without introducing excessive SNR penalties remains a significant challenge, since the channel capacity is a non-linear function of both parameters. In this paper, we present a fundamental analysis of how the parameters of the LED and pre-equalization circuits influence the channel capacity in intensity modulation and direct detection (IMDD)-based VLC systems. We derive a closed-form expression for channel capacity model that is an explicitly function of analog pre-equalizer circuit parameters. Building upon the derived capacity expression, we propose a systematic design methodology for analog pre-equalizers that effectively balances bandwidth and SNR, thereby maximizing the overall channel capacity across a wide range of channel attenuations. We present extensive numerical results to validate the effectiveness of the proposed design and demonstrate the improvements over conventional bandwidth-optimized pre-equalizer designs.