 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Speech Tokenizers with Diffusion Autoencoders
Feb 06, 2026Speech tokenizers are foundational to speech language models, yet existing approaches face two major challenges: (1) balancing trade-offs between encoding semantics for understanding and acoustics for reconstruction, and (2) achieving low bit rates and low token rates. We propose Speech Diffusion Tokenizer (SiTok), a diffusion autoencoder that jointly learns semantic-rich representations through supervised learning and enables high-fidelity audio reconstruction with diffusion. We scale SiTok to 1.6B parameters and train it on 2 million hours of speech. Experiments show that SiTok outperforms strong baselines on understanding, reconstruction and generation tasks, at an extremely low token rate of $12.5$ Hz and a bit-rate of 200 bits-per-second.
EchoMind: An Interrelated Multi-level Benchmark for Evaluating Empathetic Speech Language Models
Oct 26, 2025Speech Language Models (SLMs) have made significant progress in spoken language understanding. Yet it remains unclear whether they can fully perceive non lexical vocal cues alongside spoken words, and respond with empathy that aligns with both emotional and contextual factors. Existing benchmarks typically evaluate linguistic, acoustic, reasoning, or dialogue abilities in isolation, overlooking the integration of these skills that is crucial for human-like, emotionally intelligent conversation. We present EchoMind, the first interrelated, multi-level benchmark that simulates the cognitive process of empathetic dialogue through sequential, context-linked tasks: spoken-content understanding, vocal-cue perception, integrated reasoning, and response generation. All tasks share identical and semantically neutral scripts that are free of explicit emotional or contextual cues, and controlled variations in vocal style are used to test the effect of delivery independent of the transcript. EchoMind is grounded in an empathy-oriented framework spanning 3 coarse and 12 fine-grained dimensions, encompassing 39 vocal attributes, and evaluated using both objective and subjective metrics. Testing 12 advanced SLMs reveals that even state-of-the-art models struggle with high-expressive vocal cues, limiting empathetic response quality. Analyses of prompt strength, speech source, and ideal vocal cue recognition reveal persistent weaknesses in instruction-following, resilience to natural speech variability, and effective use of vocal cues for empathy. These results underscore the need for SLMs that integrate linguistic content with diverse vocal cues to achieve truly empathetic conversational ability.
Audio Deepfake Verification
Sep 10, 2025With the rapid development of deepfake technology, simply making a binary judgment of true or false on audio is no longer sufficient to meet practical needs. Accurately determining the specific deepfake method has become crucial. This paper introduces the Audio Deepfake Verification (ADV) task, effectively addressing the limitations of existing deepfake source tracing methods in closed-set scenarios, aiming to achieve open-set deepfake source tracing. Meanwhile, the Audity dual-branch architecture is proposed, extracting deepfake features from two dimensions: audio structure and generation artifacts. Experimental results show that the dual-branch Audity architecture outperforms any single-branch configuration, and it can simultaneously achieve excellent performance in both deepfake detection and verification tasks.
Solla: Towards a Speech-Oriented LLM That Hears Acoustic Context
Mar 19, 2025
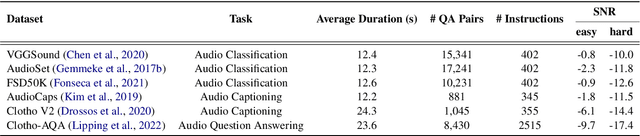
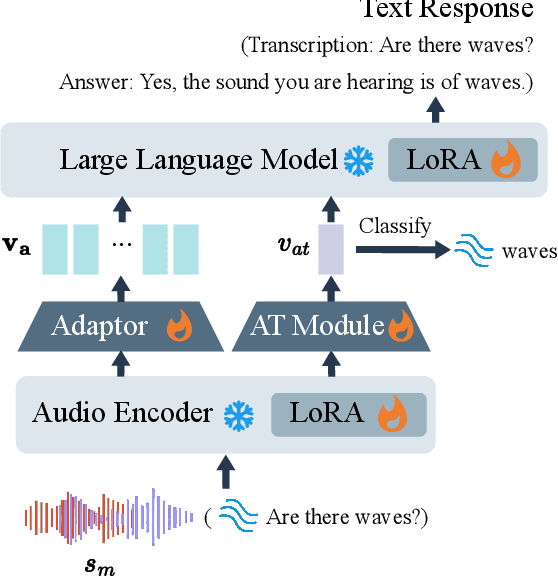
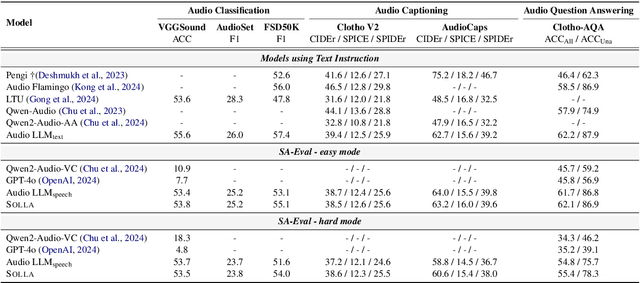
Large Language Models (LLMs) have recently shown remarkable ability to process not only text but also multimodal inputs such as speech and audio. However, most existing models primarily focus on analyzing input signals using text instructions, overlooking scenarios in which speech instructions and audio are mixed and serve as inputs to the model. To address these challenges, we introduce Solla, a novel framework designed to understand speech-based questions and hear the acoustic context concurrently. Solla incorporates an audio tagging module to effectively identify and represent audio events, as well as an ASR-assisted prediction method to improve comprehension of spoken content. To rigorously evaluate Solla and other publicly available models, we propose a new benchmark dataset called SA-Eval, which includes three tasks: audio event classification, audio captioning, and audio question answering. SA-Eval has diverse speech instruction with various speaking styles, encompassing two difficulty levels, easy and hard, to capture the range of real-world acoustic conditions. Experimental results show that Solla performs on par with or outperforms baseline models on both the easy and hard test sets, underscoring its effectiveness in jointly understanding speech and audio.
Overview of the Amphion Toolkit (v0.2)
Jan 26, 2025



Amphion is an open-source toolkit for Audio, Music, and Speech Generation, designed to lower the entry barrier for junior researchers and engineers in these fields. It provides a versatile framework that supports a variety of generation tasks and models. In this report, we introduce Amphion v0.2, the second major release developed in 2024. This release features a 100K-hour open-source multilingual dataset, a robust data preparation pipeline, and novel models for tasks such as text-to-speech, audio coding, and voice conversion. Furthermore, the report includes multiple tutorials that guide users through the functionalities and usage of the newly released models.
SA-WavLM: Speaker-Aware Self-Supervised Pre-training for Mixture Speech
Jul 03, 2024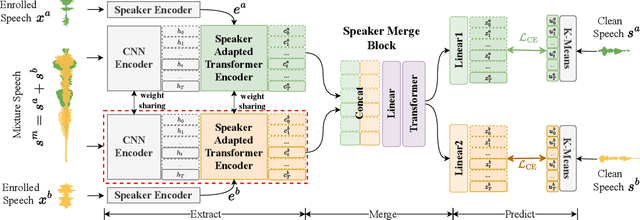
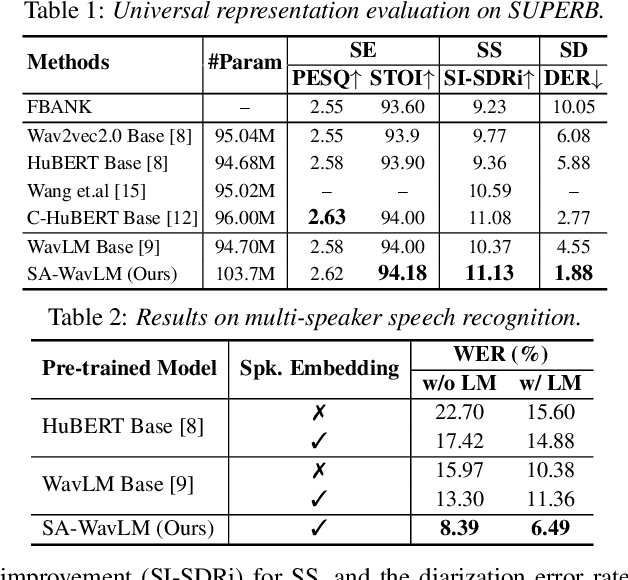
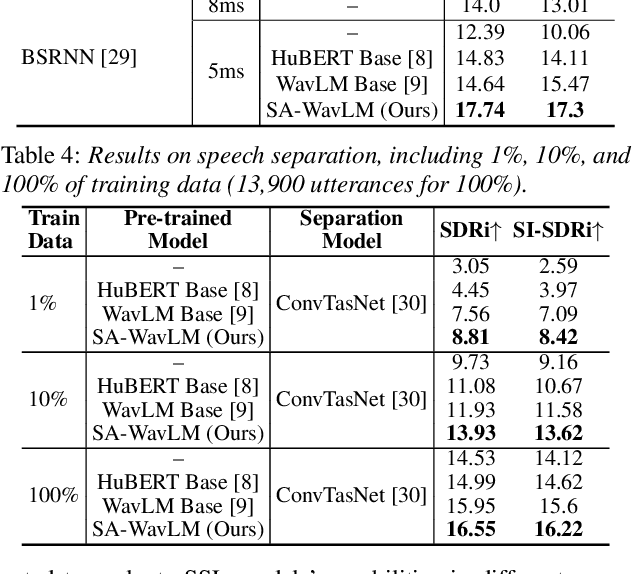
It was shown that pre-trained models with self-supervised learning (SSL) techniques are effective in various downstream speech tasks. However, most such models are trained on single-speaker speech data, limiting their effectiveness in mixture speech. This motivates us to explore pre-training on mixture speech. This work presents SA-WavLM, a novel pre-trained model for mixture speech. Specifically, SA-WavLM follows an "extract-merge-predict" pipeline in which the representations of each speaker in the input mixture are first extracted individually and then merged before the final prediction. In this pipeline, SA-WavLM performs speaker-informed extractions with the consideration of the interactions between different speakers. Furthermore, a speaker shuffling strategy is proposed to enhance the robustness towards the speaker absence. Experiments show that SA-WavLM either matches or improves upon the state-of-the-art pre-trained models.
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Jun 19, 2024



Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a similar process as SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.
Text-guided HuBERT: Self-Supervised Speech Pre-training via Generative Adversarial Networks
Feb 28, 2024



Human language can be expressed in either written or spoken form, i.e. text or speech. Humans can acquire knowledge from text to improve speaking and listening. However, the quest for speech pre-trained models to leverage unpaired text has just started. In this paper, we investigate a new way to pre-train such a joint speech-text model to learn enhanced speech representations and benefit various speech-related downstream tasks. Specifically, we propose a novel pre-training method, text-guided HuBERT, or T-HuBERT, which performs self-supervised learning over speech to derive phoneme-like discrete representations. And these phoneme-like pseudo-label sequences are firstly derived from speech via the generative adversarial networks (GAN) to be statistically similar to those from additional unpaired textual data. In this way, we build a bridge between unpaired speech and text in an unsupervised manner. Extensive experiments demonstrate the significant superiority of our proposed method over various strong baselines, which achieves up to 15.3% relative Word Error Rate (WER) reduction on the LibriSpeech dataset.
The NUS-HLT System for ICASSP2024 ICMC-ASR Grand Challenge
Dec 26, 2023This paper summarizes our team's efforts in both tracks of the ICMC-ASR Challenge for in-car multi-channel automatic speech recognition. Our submitted systems for ICMC-ASR Challenge include the multi-channel front-end enhancement and diarization, training data augmentation, speech recognition modeling with multi-channel branches. Tested on the offical Eval1 and Eval2 set, our best system achieves a relative 34.3% improvement in CER and 56.5% improvement in cpCER, compared to the offical baseline system.
USED: Universal Speaker Extraction and Diarization
Sep 19, 2023



Speaker extraction and diarization are two crucial enabling techniques for speech applications. Speaker extraction aims to extract a target speaker's voice from a multi-talk mixture, while speaker diarization demarcates speech segments by speaker, identifying `who spoke when'. The previous studies have typically treated the two tasks independently. However, the two tasks share a similar objective, that is to disentangle the speakers in the spectral domain for the former but in the temporal domain for the latter. It is logical to believe that the speaker turns obtained from speaker diarization can benefit speaker extraction, while the extracted speech offers more accurate speaker turns than the mixture speech. In this paper, we propose a unified framework called Universal Speaker Extraction and Diarization (USED). We extend the existing speaker extraction model to simultaneously extract the waveforms of all speakers. We also employ a scenario-aware differentiated loss function to address the problem of sparsely overlapped speech in real-world conversations. We show that the USED model significantly outperforms the baselines for both speaker extraction and diarization tasks, in both highly overlapped and sparsely overlapped scenarios. Audio samples are available at https://ajyy.github.io/demo/USED/.