 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the Amphion Toolkit (v0.2)
Jan 26, 2025



Amphion is an open-source toolkit for Audio, Music, and Speech Generation, designed to lower the entry barrier for junior researchers and engineers in these fields. It provides a versatile framework that supports a variety of generation tasks and models. In this report, we introduce Amphion v0.2, the second major release developed in 2024. This release features a 100K-hour open-source multilingual dataset, a robust data preparation pipeline, and novel models for tasks such as text-to-speech, audio coding, and voice conversion. Furthermore, the report includes multiple tutorials that guide users through the functionalities and usage of the newly released models.
DiveSound: LLM-Assisted Automatic Taxonomy Construction for Diverse Audio Generation
Jul 18, 2024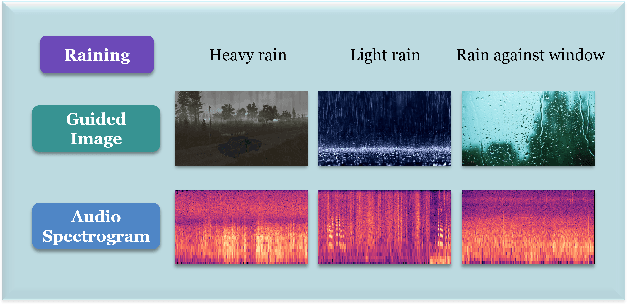

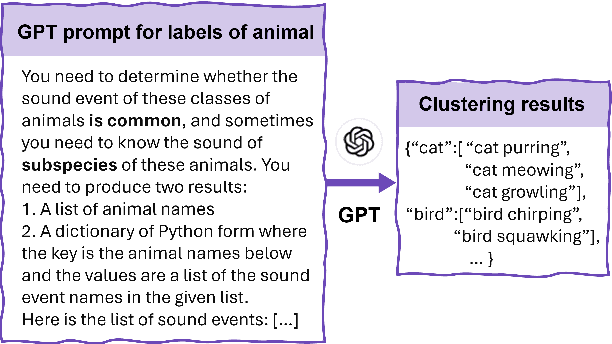

Audio generation has attracted significant attention. Despite remarkable enhancement in audio quality, existing models overlook diversity evaluation. This is partially due to the lack of a systematic sound class diversity framework and a matching dataset. To address these issues, we propose DiveSound, a novel framework for constructing multimodal datasets with in-class diversified taxonomy, assisted by large language models. As both textual and visual information can be utilized to guide diverse generation, DiveSound leverages multimodal contrastive representations in data construction. Our framework is highly autonomous and can be easily scaled up. We provide a textaudio-image aligned diversity dataset whose sound event class tags have an average of 2.42 subcategories. Text-to-audio experiments on the constructed dataset show a substantial increase of diversity with the help of the guidance of visual information.
AudioTime: A Temporally-aligned Audio-text Benchmark Dataset
Jul 03, 2024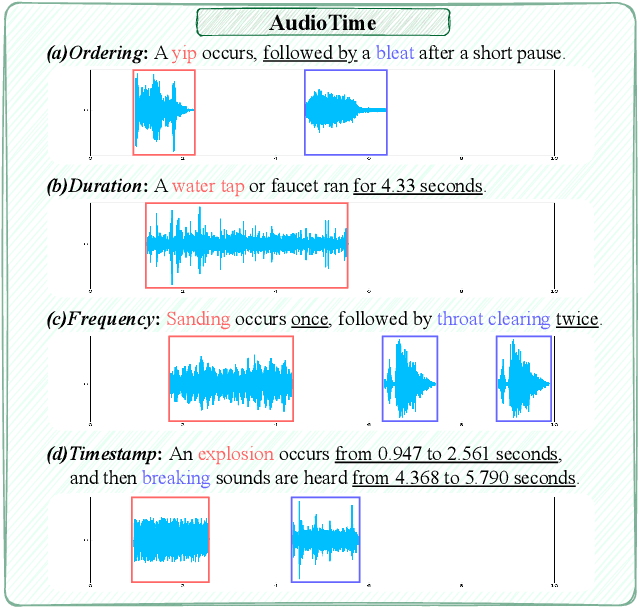

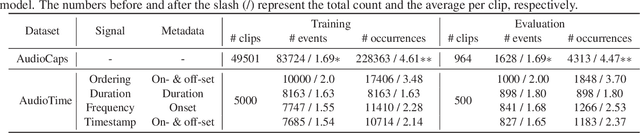
Recent advancements in audio generation have enabled the creation of high-fidelity audio clips from free-form textual descriptions. However, temporal relationships, a critical feature for audio content, are currently underrepresented in mainstream models, resulting in an imprecise temporal controllability. Specifically, users cannot accurately control the timestamps of sound events using free-form text. We acknowledge that a significant factor is the absence of high-quality, temporally-aligned audio-text datasets, which are essential for training models with temporal control. The more temporally-aligned the annotations, the better the models can understand the precise relationship between audio outputs and temporal textual prompts. Therefore, we present a strongly aligned audio-text dataset, AudioTime. It provides text annotations rich in temporal information such as timestamps, duration, frequency, and ordering, covering almost all aspects of temporal control. Additionally, we offer a comprehensive test set and evaluation metric to assess the temporal control performance of various models. Examples are available on the https://zeyuxie29.github.io/AudioTime/
PicoAudio: Enabling Precise Timestamp and Frequency Controllability of Audio Events in Text-to-audio Generation
Jul 03, 2024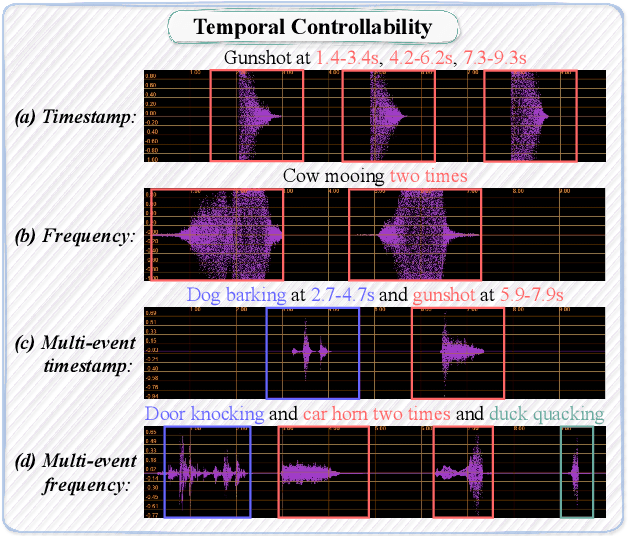
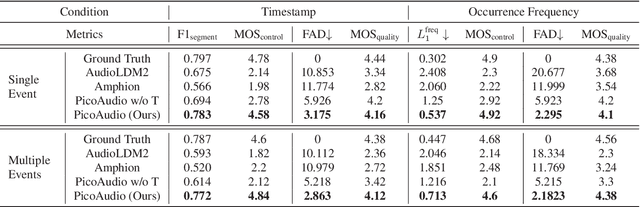
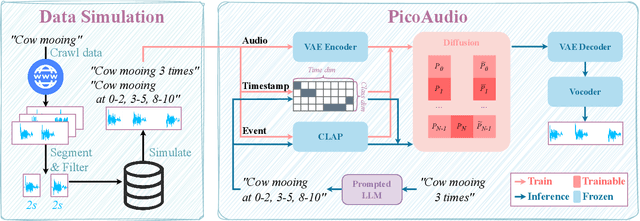
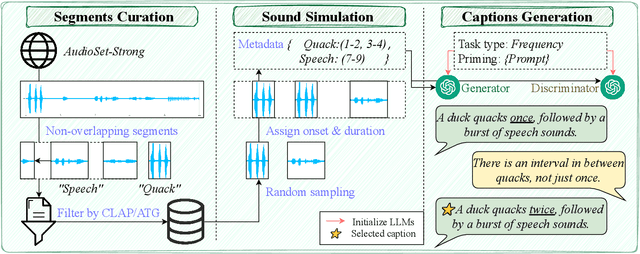
Recently, audio generation tasks have attracted considerable research interests. Precise temporal controllability is essential to integrate audio generation with real applications. In this work, we propose a temporal controlled audio generation framework, PicoAudio. PicoAudio integrates temporal information to guide audio generation through tailored model design. It leverages data crawling, segmentation, filtering, and simulation of fine-grained temporally-aligned audio-text data. Both subjective and objective evaluations demonstrate that PicoAudio dramantically surpasses current state-of-the-art generation models in terms of timestamp and occurrence frequency controllability. The generated samples are available on the demo website https://PicoAudio.github.io.
FakeSound: Deepfake General Audio Detection
Jun 12, 2024



With the advancement of audio generation, generative models can produce highly realistic audios. However, the proliferation of deepfake general audio can pose negative consequences. Therefore, we propose a new task, deepfake general audio detection, which aims to identify whether audio content is manipulated and to locate deepfake regions. Leveraging an automated manipulation pipeline, a dataset named FakeSound for deepfake general audio detection is proposed, and samples can be viewed on website https://FakeSoundData.github.io. The average binary accuracy of humans on all test sets is consistently below 0.6, which indicates the difficulty humans face in discerning deepfake audio and affirms the efficacy of the FakeSound dataset. A deepfake detection model utilizing a general audio pre-trained model is proposed as a benchmark system. Experimental results demonstrate that the performance of the proposed model surpasses the state-of-the-art in deepfake speech detection and human testers.
A Detailed Audio-Text Data Simulation Pipeline using Single-Event Sounds
Mar 07, 2024



Recently, there has been an increasing focus on audio-text cross-modal learning. However, most of the existing audio-text datasets contain only simple descriptions of sound events. Compared with classification labels, the advantages of such descriptions are significantly limited. In this paper, we first analyze the detailed information that human descriptions of audio may contain beyond sound event labels. Based on the analysis, we propose an automatic pipeline for curating audio-text pairs with rich details. Leveraging the property that sounds can be mixed and concatenated in the time domain, we control details in four aspects: temporal relationship, loudness, speaker identity, and occurrence number, in simulating audio mixtures. Corresponding details are transformed into captions by large language models. Audio-text pairs with rich details in text descriptions are thereby obtained. We validate the effectiveness of our pipeline with a small amount of simulated data, demonstrating that the simulated data enables models to learn detailed audio captioning.
Enhancing Audio Generation Diversity with Visual Information
Mar 02, 2024Audio and sound generation has garnered significant attention in recent years, with a primary focus on improving the quality of generated audios. However, there has been limited research on enhancing the diversity of generated audio, particularly when it comes to audio generation within specific categories. Current models tend to produce homogeneous audio samples within a category. This work aims to address this limitation by improving the diversity of generated audio with visual information. We propose a clustering-based method, leveraging visual information to guide the model in generating distinct audio content within each category. Results on seven categories indicate that extra visual input can largely enhance audio generation diversity. Audio samples are available at https://zeyuxie29.github.io/DiverseAudioGeneration.
Phonetic and Lexical Discovery of a Canine Language using HuBERT
Feb 25, 2024



This paper delves into the pioneering exploration of potential communication patterns within dog vocalizations and transcends traditional linguistic analysis barriers, which heavily relies on human priori knowledge on limited datasets to find sound units in dog vocalization. We present a self-supervised approach with HuBERT, enabling the accurate classification of phoneme labels and the identification of vocal patterns that suggest a rudimentary vocabulary within dog vocalizations. Our findings indicate a significant acoustic consistency in these identified canine vocabulary, covering the entirety of observed dog vocalization sequences. We further develop a web-based dog vocalization labeling system. This system can highlight phoneme n-grams, present in the vocabulary, in the dog audio uploaded by users.
Improving Audio Caption Fluency with Automatic Error Correction
Jun 16, 2023Automated audio captioning (AAC) is an important cross-modality translation task, aiming at generating descriptions for audio clips. However, captions generated by previous AAC models have faced ``false-repetition'' errors due to the training objective. In such scenarios, we propose a new task of AAC error correction and hope to reduce such errors by post-processing AAC outputs. To tackle this problem, we use observation-based rules to corrupt captions without errors, for pseudo grammatically-erroneous sentence generation. One pair of corrupted and clean sentences can thus be used for training. We train a neural network-based model on the synthetic error dataset and apply the model to correct real errors in AAC outputs. Results on two benchmark datasets indicate that our approach significantly improves fluency while maintaining semantic information.
Enhance Temporal Relations in Audio Captioning with Sound Event Detection
Jun 02, 2023



Automated audio captioning aims at generating natural language descriptions for given audio clips, not only detecting and classifying sounds, but also summarizing the relationships between audio events. Recent research advances in audio captioning have introduced additional guidance to improve the accuracy of audio events in generated sentences. However, temporal relations between audio events have received little attention while revealing complex relations is a key component in summarizing audio content. Therefore, this paper aims to better capture temporal relationships in caption generation with sound event detection (SED), a task that locates events' timestamps. We investigate the best approach to integrate temporal information in a captioning model and propose a temporal tag system to transform the timestamps into comprehensible relations. Results evaluated by the proposed temporal metrics suggest that great improvement is achieved in terms of temporal relation generation.