 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic or Authentic? Building Mental Patient Simulators from Longitudinal Evidence
Mar 24, 2026Patient simulation is essential for developing and evaluating mental health dialogue systems. As most existing approaches rely on snapshot-style prompts with limited profile information, homogeneous behaviors and incoherent disease progression in multi-turn interactions have become key chellenges. In this work, we propose DEPROFILE, a data-grounded patient simulation framework that constructs unified, multi-source patient profiles by integrating demographic attributes, standardized clinical symptoms, counseling dialogues, and longitudinal life-event histories from real-world data. We further introduce a Chain-of-Change agent to transform noisy longitudinal records into structured, temporally grounded memory representations for simulation. Experiments across multiple large language model (LLM) backbones show that with more comprehensive profile constructed by DEPROFILE, the dialogue realism, behavioral diversity, and event richness have consistently improved and exceed state-of-the-art baselines, highlighting the importance of grounding patient simulation in verifiable longitudinal evidence.
CAST-TTS: A Simple Cross-Attention Framework for Unified Timbre Control in TTS
Mar 17, 2026Current Text-to-Speech (TTS) systems typically use separate models for speech-prompted and text-prompted timbre control. While unifying both control signals into a single model is desirable, the challenge of cross-modal alignment often results in overly complex architectures and training objective. To address this challenge, we propose CAST-TTS, a simple yet effective framework for unified timbre control. Features are extracted from speech prompts and text prompts using pre-trained encoders. The multi-stage training strategy efficiently aligns the speech and projected text representations within a shared embedding space. A single cross-attention mechanism then allows the model to use either of these representations to control the timbre. Extensive experiments validate that the unified cross-attention mechanism is critical for achieving high-quality synthesis. CAST-TTS achieves performance comparable to specialized single-input models while operating within a unified architecture. The demo page can be accessed at https://HiRookie9.github.io/CAST-TTS-Page.
A Human-Centric Pipeline for Aligning Large Language Models with Chinese Medical Ethics
Jan 12, 2026Recent advances in large language models have enabled their application to a range of healthcare tasks. However, aligning LLMs with the nuanced demands of medical ethics, especially under complex real world scenarios, remains underexplored. In this work, we present MedES, a dynamic, scenario-centric benchmark specifically constructed from 260 authoritative Chinese medical, ethical, and legal sources to reflect the challenges in clinical decision-making. To facilitate model alignment, we introduce a guardian-in-the-loop framework that leverages a dedicated automated evaluator (trained on expert-labeled data and achieving over 97% accuracy within our domain) to generate targeted prompts and provide structured ethical feedback. Using this pipeline, we align a 7B-parameter LLM through supervised fine-tuning and domain-specific preference optimization. Experimental results, conducted entirely within the Chinese medical ethics context, demonstrate that our aligned model outperforms notably larger baselines on core ethical tasks, with observed improvements in both quality and composite evaluation metrics. Our work offers a practical and adaptable framework for aligning LLMs with medical ethics in the Chinese healthcare domain, and suggests that similar alignment pipelines may be instantiated in other legal and cultural environments through modular replacement of the underlying normative corpus.
Semi-Supervised Diseased Detection from Speech Dialogues with Multi-Level Data Modeling
Jan 08, 2026Detecting medical conditions from speech acoustics is fundamentally a weakly-supervised learning problem: a single, often noisy, session-level label must be linked to nuanced patterns within a long, complex audio recording. This task is further hampered by severe data scarcity and the subjective nature of clinical annotations. While semi-supervised learning (SSL) offers a viable path to leverage unlabeled data, existing audio methods often fail to address the core challenge that pathological traits are not uniformly expressed in a patient's speech. We propose a novel, audio-only SSL framework that explicitly models this hierarchy by jointly learning from frame-level, segment-level, and session-level representations within unsegmented clinical dialogues. Our end-to-end approach dynamically aggregates these multi-granularity features and generates high-quality pseudo-labels to efficiently utilize unlabeled data. Extensive experiments show the framework is model-agnostic, robust across languages and conditions, and highly data-efficient-achieving, for instance, 90\% of fully-supervised performance using only 11 labeled samples. This work provides a principled approach to learning from weak, far-end supervision in medical speech analysis.
Generating Storytelling Images with Rich Chains-of-Reasoning
Dec 08, 2025An image can convey a compelling story by presenting rich, logically connected visual clues. These connections form Chains-of-Reasoning (CoRs) within the image, enabling viewers to infer events, causal relationships, and other information, thereby understanding the underlying story. In this paper, we focus on these semantically rich images and define them as Storytelling Images. Such images have diverse applications beyond illustration creation and cognitive screening, leveraging their ability to convey multi-layered information visually and inspire active interpretation. However, due to their complex semantic nature, Storytelling Images are inherently challenging to create, and thus remain relatively scarce. To address this challenge, we introduce the Storytelling Image Generation task, which explores how generative AI models can be leveraged to create such images. Specifically, we propose a two-stage pipeline, StorytellingPainter, which combines the creative reasoning abilities of Large Language Models (LLMs) with the visual synthesis capabilities of Text-to-Image (T2I) models to generate Storytelling Images. Alongside this pipeline, we develop a dedicated evaluation framework comprising three main evaluators: a Semantic Complexity Evaluator, a KNN-based Diversity Evaluator and a Story-Image Alignment Evaluator. Given the critical role of story generation in the Storytelling Image Generation task and the performance disparity between open-source and proprietary LLMs, we further explore tailored training strategies to reduce this gap, resulting in a series of lightweight yet effective models named Mini-Storytellers. Experimental results demonstrate the feasibility and effectiveness of our approaches. The code is available at https://github.com/xiujiesong/StorytellingImageGeneration.
Delusions of Large Language Models
Mar 09, 2025Large Language Models often generate factually incorrect but plausible outputs, known as hallucinations. We identify a more insidious phenomenon, LLM delusion, defined as high belief hallucinations, incorrect outputs with abnormally high confidence, making them harder to detect and mitigate. Unlike ordinary hallucinations, delusions persist with low uncertainty, posing significant challenges to model reliability. Through empirical analysis across different model families and sizes on several Question Answering tasks, we show that delusions are prevalent and distinct from hallucinations. LLMs exhibit lower honesty with delusions, which are harder to override via finetuning or self reflection. We link delusion formation with training dynamics and dataset noise and explore mitigation strategies such as retrieval augmented generation and multi agent debating to mitigate delusions. By systematically investigating the nature, prevalence, and mitigation of LLM delusions, our study provides insights into the underlying causes of this phenomenon and outlines future directions for improving model reliability.
MM-StoryAgent: Immersive Narrated Storybook Video Generation with a Multi-Agent Paradigm across Text, Image and Audio
Mar 07, 2025



The rapid advancement of large language models (LLMs) and artificial intelligence-generated content (AIGC) has accelerated AI-native applications, such as AI-based storybooks that automate engaging story production for children. However, challenges remain in improving story attractiveness, enriching storytelling expressiveness, and developing open-source evaluation benchmarks and frameworks. Therefore, we propose and opensource MM-StoryAgent, which creates immersive narrated video storybooks with refined plots, role-consistent images, and multi-channel audio. MM-StoryAgent designs a multi-agent framework that employs LLMs and diverse expert tools (generative models and APIs) across several modalities to produce expressive storytelling videos. The framework enhances story attractiveness through a multi-stage writing pipeline. In addition, it improves the immersive storytelling experience by integrating sound effects with visual, music and narrative assets. MM-StoryAgent offers a flexible, open-source platform for further development, where generative modules can be substituted. Both objective and subjective evaluation regarding textual story quality and alignment between modalities validate the effectiveness of our proposed MM-StoryAgent system. The demo and source code are available.
WritingBench: A Comprehensive Benchmark for Generative Writing
Mar 07, 2025Recent advancements in large language models (LLMs) have significantly enhanced text generation capabilities, yet evaluating their performance in generative writing remains a challenge. Existing benchmarks primarily focus on generic text generation or limited in writing tasks, failing to capture the diverse requirements of high-quality written contents across various domains. To bridge this gap, we present WritingBench, a comprehensive benchmark designed to evaluate LLMs across 6 core writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. We further propose a query-dependent evaluation framework that empowers LLMs to dynamically generate instance-specific assessment criteria. This framework is complemented by a fine-tuned critic model for criteria-aware scoring, enabling evaluations in style, format and length. The framework's validity is further demonstrated by its data curation capability, which enables 7B-parameter models to approach state-of-the-art (SOTA) performance. We open-source the benchmark, along with evaluation tools and modular framework components, to advance the development of LLMs in writing.
MedEthicEval: Evaluating Large Language Models Based on Chinese Medical Ethics
Mar 04, 2025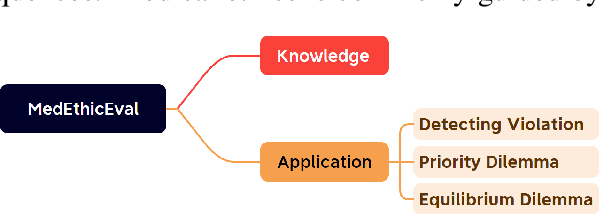

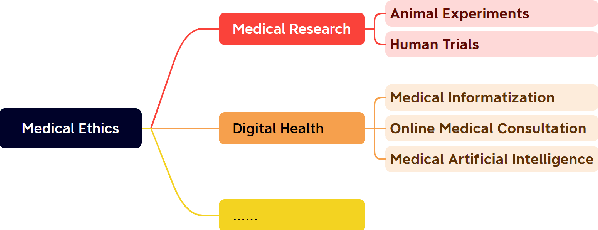

Large language models (LLMs) demonstrate significant potential in advancing medical applications, yet their capabilities in addressing medical ethics challenges remain underexplored. This paper introduces MedEthicEval, a novel benchmark designed to systematically evaluate LLMs in the domain of medical ethics. Our framework encompasses two key components: knowledge, assessing the models' grasp of medical ethics principles, and application, focusing on their ability to apply these principles across diverse scenarios. To support this benchmark, we consulted with medical ethics researchers and developed three datasets addressing distinct ethical challenges: blatant violations of medical ethics, priority dilemmas with clear inclinations, and equilibrium dilemmas without obvious resolutions. MedEthicEval serves as a critical tool for understanding LLMs' ethical reasoning in healthcare, paving the way for their responsible and effective use in medical contexts.
Is Your Image a Good Storyteller?
Dec 29, 2024Quantifying image complexity at the entity level is straightforward, but the assessment of semantic complexity has been largely overlooked. In fact, there are differences in semantic complexity across images. Images with richer semantics can tell vivid and engaging stories and offer a wide range of application scenarios. For example, the Cookie Theft picture is such a kind of image and is widely used to assess human language and cognitive abilities due to its higher semantic complexity. Additionally, semantically rich images can benefit the development of vision models, as images with limited semantics are becoming less challenging for them. However, such images are scarce, highlighting the need for a greater number of them. For instance, there is a need for more images like Cookie Theft to cater to people from different cultural backgrounds and eras. Assessing semantic complexity requires human experts and empirical evidence. Automatic evaluation of how semantically rich an image will be the first step of mining or generating more images with rich semantics, and benefit human cognitive assessment, Artificial Intelligence, and various other applications. In response, we propose the Image Semantic Assessment (ISA) task to address this problem. We introduce the first ISA dataset and a novel method that leverages language to solve this vision problem. Experiments on our dataset demonstrate the effectiveness of our approach. Our data and code are available at: https://github.com/xiujiesong/ISA.