 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasyMimic: A Low-Cost Framework for Robot Imitation Learning from Human Videos
Feb 12, 2026Robot imitation learning is often hindered by the high cost of collecting large-scale, real-world data. This challenge is especially significant for low-cost robots designed for home use, as they must be both user-friendly and affordable. To address this, we propose the EasyMimic framework, a low-cost and replicable solution that enables robots to quickly learn manipulation policies from human video demonstrations captured with standard RGB cameras. Our method first extracts 3D hand trajectories from the videos. An action alignment module then maps these trajectories to the gripper control space of a low-cost robot. To bridge the human-to-robot domain gap, we introduce a simple and user-friendly hand visual augmentation strategy. We then use a co-training method, fine-tuning a model on both the processed human data and a small amount of robot data, enabling rapid adaptation to new tasks. Experiments on the low-cost LeRobot platform demonstrate that EasyMimic achieves high performance across various manipulation tasks. It significantly reduces the reliance on expensive robot data collection, offering a practical path for bringing intelligent robots into homes. Project website: https://zt375356.github.io/EasyMimic-Project/.
Rethinking Visual-Language-Action Model Scaling: Alignment, Mixture, and Regularization
Feb 10, 2026While Vision-Language-Action (VLA) models show strong promise for generalist robot control, it remains unclear whether -- and under what conditions -- the standard "scale data" recipe translates to robotics, where training data is inherently heterogeneous across embodiments, sensors, and action spaces. We present a systematic, controlled study of VLA scaling that revisits core training choices for pretraining across diverse robots. Using a representative VLA framework that combines a vision-language backbone with flow-matching, we ablate key design decisions under matched conditions and evaluate in extensive simulation and real-robot experiments. To improve the reliability of real-world results, we introduce a Grouped Blind Ensemble protocol that blinds operators to model identity and separates policy execution from outcome judgment, reducing experimenter bias. Our analysis targets three dimensions of VLA scaling. (1) Physical alignment: we show that a unified end-effector (EEF)-relative action representation is critical for robust cross-embodiment transfer. (2) Embodiment mixture: we find that naively pooling heterogeneous robot datasets often induces negative transfer rather than gains, underscoring the fragility of indiscriminate data scaling. (3) Training regularization: we observe that intuitive strategies, such as sensory dropout and multi-stage fine-tuning, do not consistently improve performance at scale. Together, this study challenge some common assumptions about embodied scaling and provide practical guidance for training large-scale VLA policies from diverse robotic data. Project website: https://research.beingbeyond.com/rethink_vla
What Matters in Evaluating Book-Length Stories? A Systematic Study of Long Story Evaluation
Dec 14, 2025In this work, we conduct systematic research in a challenging area: the automatic evaluation of book-length stories (>100K tokens). Our study focuses on two key questions: (1) understanding which evaluation aspects matter most to readers, and (2) exploring effective methods for evaluating lengthy stories. We introduce the first large-scale benchmark, LongStoryEval, comprising 600 newly published books with an average length of 121K tokens (maximum 397K). Each book includes its average rating and multiple reader reviews, presented as critiques organized by evaluation aspects. By analyzing all user-mentioned aspects, we propose an evaluation criteria structure and conduct experiments to identify the most significant aspects among the 8 top-level criteria. For evaluation methods, we compare the effectiveness of three types: aggregation-based, incremental-updated, and summary-based evaluations. Our findings reveal that aggregation- and summary-based evaluations perform better, with the former excelling in detail assessment and the latter offering greater efficiency. Building on these insights, we further propose NovelCritique, an 8B model that leverages the efficient summary-based framework to review and score stories across specified aspects. NovelCritique outperforms commercial models like GPT-4o in aligning with human evaluations. Our datasets and codes are available at https://github.com/DingyiYang/LongStoryEval.
ChartEditor: A Reinforcement Learning Framework for Robust Chart Editing
Nov 19, 2025Chart editing reduces manual effort in visualization design. Typical benchmarks limited in data diversity and assume access to complete chart code, which is seldom in real-world scenarios. To address this gap, we present ChartEditVista, a comprehensive benchmark consisting of 7,964 samples spanning 31 chart categories. It encompasses diverse editing instructions and covers nearly all editable chart elements. The inputs in ChartEditVista include only the original chart image and natural language editing instructions, without the original chart codes. ChartEditVista is generated through a fully automated pipeline that produces, edits, and verifies charts, ensuring high-quality chart editing data. Besides, we introduce two novel fine-grained, rule-based evaluation metrics: the layout metric, which evaluates the position, size and color of graphical components; and the text metric, which jointly assesses textual content and font styling. Building on top of ChartEditVista, we present ChartEditor, a model trained using a reinforcement learning framework that incorporates a novel rendering reward to simultaneously enforce code executability and visual fidelity. Through extensive experiments and human evaluations, we demonstrate that ChartEditVista provides a robust evaluation, while ChartEditor consistently outperforms models with similar-scale and larger-scale on chart editing tasks.
Mem-PAL: Towards Memory-based Personalized Dialogue Assistants for Long-term User-Agent Interaction
Nov 17, 2025With the rise of smart personal devices, service-oriented human-agent interactions have become increasingly prevalent. This trend highlights the need for personalized dialogue assistants that can understand user-specific traits to accurately interpret requirements and tailor responses to individual preferences. However, existing approaches often overlook the complexities of long-term interactions and fail to capture users' subjective characteristics. To address these gaps, we present PAL-Bench, a new benchmark designed to evaluate the personalization capabilities of service-oriented assistants in long-term user-agent interactions. In the absence of available real-world data, we develop a multi-step LLM-based synthesis pipeline, which is further verified and refined by human annotators. This process yields PAL-Set, the first Chinese dataset comprising multi-session user logs and dialogue histories, which serves as the foundation for PAL-Bench. Furthermore, to improve personalized service-oriented interactions, we propose H$^2$Memory, a hierarchical and heterogeneous memory framework that incorporates retrieval-augmented generation to improve personalized response generation. Comprehensive experiments on both our PAL-Bench and an external dataset demonstrate the effectiveness of the proposed memory framework.
SingMOS-Pro: An Comprehensive Benchmark for Singing Quality Assessment
Oct 02, 2025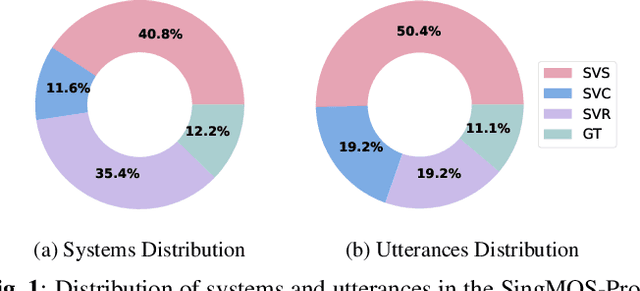

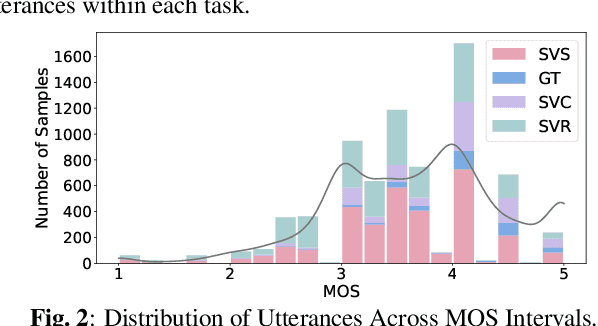

Singing voice generation progresses rapidly, yet evaluating singing quality remains a critical challenge. Human subjective assessment, typically in the form of listening tests, is costly and time consuming, while existing objective metrics capture only limited perceptual aspects. In this work, we introduce SingMOS-Pro, a dataset for automatic singing quality assessment. Building on our preview version SingMOS, which provides only overall ratings, SingMOS-Pro expands annotations of the additional part to include lyrics, melody, and overall quality, offering broader coverage and greater diversity. The dataset contains 7,981 singing clips generated by 41 models across 12 datasets, spanning from early systems to recent advances. Each clip receives at least five ratings from professional annotators, ensuring reliability and consistency. Furthermore, we explore how to effectively utilize MOS data annotated under different standards and benchmark several widely used evaluation methods from related tasks on SingMOS-Pro, establishing strong baselines and practical references for future research. The dataset can be accessed at https://huggingface.co/datasets/TangRain/SingMOS-Pro.
Being-M0.5: A Real-Time Controllable Vision-Language-Motion Model
Aug 11, 2025Human motion generation has emerged as a critical technology with transformative potential for real-world applications. However, existing vision-language-motion models (VLMMs) face significant limitations that hinder their practical deployment. We identify controllability as a main bottleneck, manifesting in five key aspects: inadequate response to diverse human commands, limited pose initialization capabilities, poor performance on long-term sequences, insufficient handling of unseen scenarios, and lack of fine-grained control over individual body parts. To overcome these limitations, we present Being-M0.5, the first real-time, controllable VLMM that achieves state-of-the-art performance across multiple motion generation tasks. Our approach is built upon HuMo100M, the largest and most comprehensive human motion dataset to date, comprising over 5 million self-collected motion sequences, 100 million multi-task instructional instances, and detailed part-level annotations that address a critical gap in existing datasets. We introduce a novel part-aware residual quantization technique for motion tokenization that enables precise, granular control over individual body parts during generation. Extensive experimental validation demonstrates Being-M0.5's superior performance across diverse motion benchmarks, while comprehensive efficiency analysis confirms its real-time capabilities. Our contributions include design insights and detailed computational analysis to guide future development of practical motion generators. We believe that HuMo100M and Being-M0.5 represent significant advances that will accelerate the adoption of motion generation technologies in real-world applications. The project page is available at https://beingbeyond.github.io/Being-M0.5.
A Survey of Deep Learning for Geometry Problem Solving
Jul 16, 2025Geometry problem solving is a key area of mathematical reasoning, which is widely involved in many important fields such as education, mathematical ability assessment of artificial intelligence, and multimodal ability assessment. In recent years, the rapid development of deep learning technology, especially the rise of multimodal large language models, has triggered a widespread research boom. This paper provides a survey of the applications of deep learning in geometry problem solving, including (i) a comprehensive summary of the relevant tasks in geometry problem solving; (ii) a thorough review of related deep learning methods; (iii) a detailed analysis of evaluation metrics and methods; and (iv) a critical discussion of the current challenges and future directions that can be explored. Our goal is to provide a comprehensive and practical reference of deep learning for geometry problem solving to promote further developments in this field. We create a continuously updated list of papers on GitHub: https://github.com/majianz/dl4gps.
POLYCHARTQA: Benchmarking Large Vision-Language Models with Multilingual Chart Question Answering
Jul 16, 2025Charts are a universally adopted medium for interpreting and communicating data. However, existing chart understanding benchmarks are predominantly English-centric, limiting their accessibility and applicability to global audiences. In this paper, we present PolyChartQA, the first large-scale multilingual chart question answering benchmark covering 22,606 charts and 26,151 question-answering pairs across 10 diverse languages. PolyChartQA is built using a decoupled pipeline that separates chart data from rendering code, allowing multilingual charts to be flexibly generated by simply translating the data and reusing the code. We leverage state-of-the-art LLM-based translation and enforce rigorous quality control in the pipeline to ensure the linguistic and semantic consistency of the generated multilingual charts. PolyChartQA facilitates systematic evaluation of multilingual chart understanding. Experiments on both open- and closed-source large vision-language models reveal a significant performance gap between English and other languages, especially low-resource ones with non-Latin scripts. This benchmark lays a foundation for advancing globally inclusive vision-language models.
IntentionESC: An Intention-Centered Framework for Enhancing Emotional Support in Dialogue Systems
Jun 06, 2025In emotional support conversations, unclear intentions can lead supporters to employ inappropriate strategies, inadvertently imposing their expectations or solutions on the seeker. Clearly defined intentions are essential for guiding both the supporter's motivations and the overall emotional support process. In this paper, we propose the Intention-centered Emotional Support Conversation (IntentionESC) framework, which defines the possible intentions of supporters in emotional support conversations, identifies key emotional state aspects for inferring these intentions, and maps them to appropriate support strategies. While Large Language Models (LLMs) excel in text generating, they fundamentally operate as probabilistic models trained on extensive datasets, lacking a true understanding of human thought processes and intentions. To address this limitation, we introduce the Intention Centric Chain-of-Thought (ICECoT) mechanism. ICECoT enables LLMs to mimic human reasoning by analyzing emotional states, inferring intentions, and selecting suitable support strategies, thereby generating more effective emotional support responses. To train the model with ICECoT and integrate expert knowledge, we design an automated annotation pipeline that produces high-quality training data. Furthermore, we develop a comprehensive evaluation scheme to assess emotional support efficacy and conduct extensive experiments to validate our framework. Our data and code are available at https://github.com/43zxj/IntentionESC_ICECoT.