 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
DockSmith: Scaling Reliable Coding Environments via an Agentic Docker Builder
Jan 31, 2026Reliable Docker-based environment construction is a dominant bottleneck for scaling execution-grounded training and evaluation of software engineering agents. We introduce DockSmith, a specialized agentic Docker builder designed to address this challenge. DockSmith treats environment construction not only as a preprocessing step, but as a core agentic capability that exercises long-horizon tool use, dependency reasoning, and failure recovery, yielding supervision that transfers beyond Docker building itself. DockSmith is trained on large-scale, execution-grounded Docker-building trajectories produced by a SWE-Factory-style pipeline augmented with a loop-detection controller and a cross-task success memory. Training a 30B-A3B model on these trajectories achieves open-source state-of-the-art performance on Multi-Docker-Eval, with 39.72% Fail-to-Pass and 58.28% Commit Rate. Moreover, DockSmith improves out-of-distribution performance on SWE-bench Verified, SWE-bench Multilingual, and Terminal-Bench 2.0, demonstrating broader agentic benefits of environment construction.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
MAI-UI Technical Report: Real-World Centric Foundation GUI Agents
Dec 26, 2025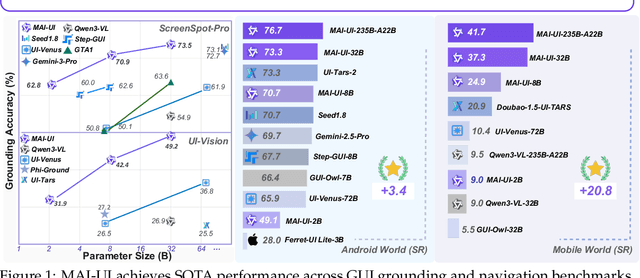

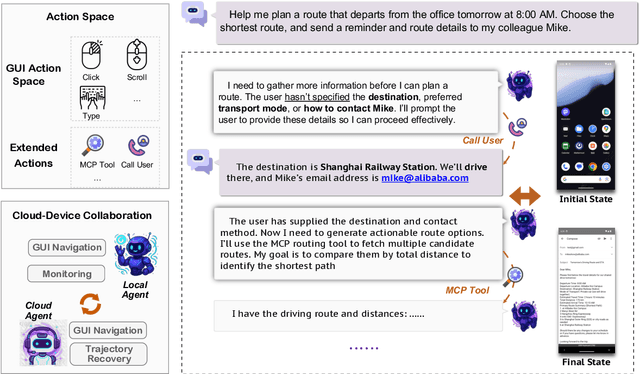
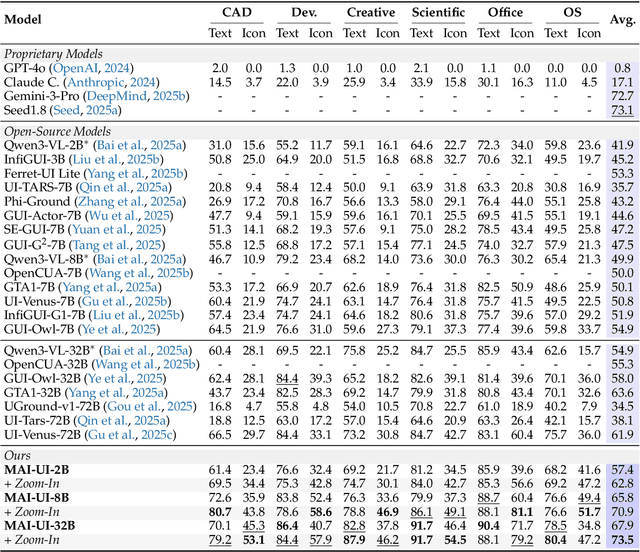
The development of GUI agents could revolutionize the next generation of human-computer interaction. Motivated by this vision, we present MAI-UI, a family of foundation GUI agents spanning the full spectrum of sizes, including 2B, 8B, 32B, and 235B-A22B variants. We identify four key challenges to realistic deployment: the lack of native agent-user interaction, the limits of UI-only operation, the absence of a practical deployment architecture, and brittleness in dynamic environments. MAI-UI addresses these issues with a unified methodology: a self-evolving data pipeline that expands the navigation data to include user interaction and MCP tool calls, a native device-cloud collaboration system routes execution by task state, and an online RL framework with advanced optimizations to scale parallel environments and context length. MAI-UI establishes new state-of-the-art across GUI grounding and mobile navigation. On grounding benchmarks, it reaches 73.5% on ScreenSpot-Pro, 91.3% on MMBench GUI L2, 70.9% on OSWorld-G, and 49.2% on UI-Vision, surpassing Gemini-3-Pro and Seed1.8 on ScreenSpot-Pro. On mobile GUI navigation, it sets a new SOTA of 76.7% on AndroidWorld, surpassing UI-Tars-2, Gemini-2.5-Pro and Seed1.8. On MobileWorld, MAI-UI obtains 41.7% success rate, significantly outperforming end-to-end GUI models and competitive with Gemini-3-Pro based agentic frameworks. Our online RL experiments show significant gains from scaling parallel environments from 32 to 512 (+5.2 points) and increasing environment step budget from 15 to 50 (+4.3 points). Finally, the native device-cloud collaboration system improves on-device performance by 33%, reduces cloud model calls by over 40%, and preserves user privacy.
MobileWorld: Benchmarking Autonomous Mobile Agents in Agent-User Interactive, and MCP-Augmented Environments
Dec 22, 2025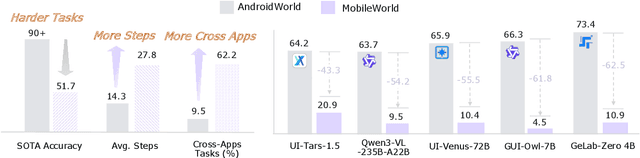
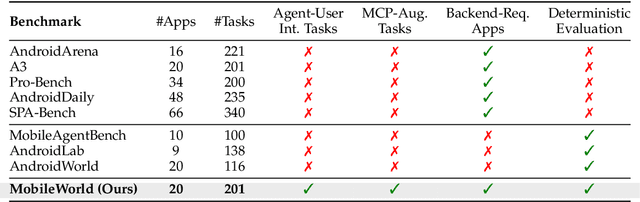
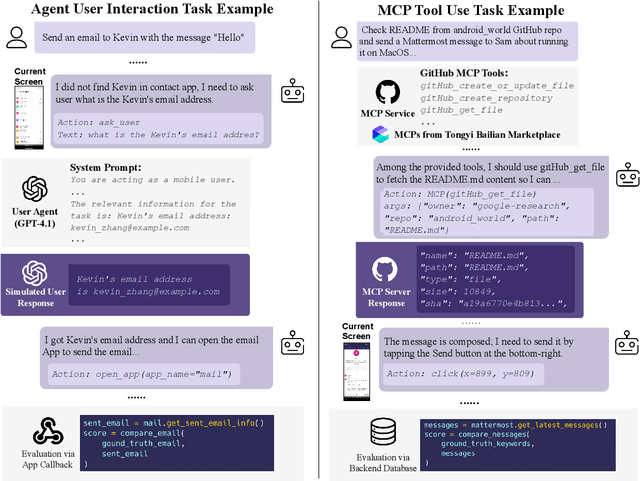

Among existing online mobile-use benchmarks, AndroidWorld has emerged as the dominant benchmark due to its reproducible environment and deterministic evaluation; however, recent agents achieving over 90% success rates indicate its saturation and motivate the need for a more challenging benchmark. In addition, its environment lacks key application categories, such as e-commerce and enterprise communication, and does not reflect realistic mobile-use scenarios characterized by vague user instructions and hybrid tool usage. To bridge this gap, we introduce MobileWorld, a substantially more challenging benchmark designed to better reflect real-world mobile usage, comprising 201 tasks across 20 applications, while maintaining the same level of reproducible evaluation as AndroidWorld. The difficulty of MobileWorld is twofold. First, it emphasizes long-horizon tasks with cross-application interactions: MobileWorld requires nearly twice as many task-completion steps on average (27.8 vs. 14.3) and includes far more multi-application tasks (62.2% vs. 9.5%) compared to AndroidWorld. Second, MobileWorld extends beyond standard GUI manipulation by introducing novel task categories, including agent-user interaction and MCP-augmented tasks. To ensure robust evaluation, we provide snapshot-based container environment and precise functional verifications, including backend database inspection and task callback APIs. We further develop a planner-executor agentic framework with extended action spaces to support user interactions and MCP calls. Our results reveal a sharp performance drop compared to AndroidWorld, with the best agentic framework and end-to-end model achieving 51.7% and 20.9% success rates, respectively. Our analysis shows that current models struggle significantly with user interaction and MCP calls, offering a strategic roadmap toward more robust, next-generation mobile intelligence.
ChartEditor: A Reinforcement Learning Framework for Robust Chart Editing
Nov 19, 2025Chart editing reduces manual effort in visualization design. Typical benchmarks limited in data diversity and assume access to complete chart code, which is seldom in real-world scenarios. To address this gap, we present ChartEditVista, a comprehensive benchmark consisting of 7,964 samples spanning 31 chart categories. It encompasses diverse editing instructions and covers nearly all editable chart elements. The inputs in ChartEditVista include only the original chart image and natural language editing instructions, without the original chart codes. ChartEditVista is generated through a fully automated pipeline that produces, edits, and verifies charts, ensuring high-quality chart editing data. Besides, we introduce two novel fine-grained, rule-based evaluation metrics: the layout metric, which evaluates the position, size and color of graphical components; and the text metric, which jointly assesses textual content and font styling. Building on top of ChartEditVista, we present ChartEditor, a model trained using a reinforcement learning framework that incorporates a novel rendering reward to simultaneously enforce code executability and visual fidelity. Through extensive experiments and human evaluations, we demonstrate that ChartEditVista provides a robust evaluation, while ChartEditor consistently outperforms models with similar-scale and larger-scale on chart editing tasks.
Tighter Truncated Rectangular Prism Approximation for RNN Robustness Verification
Nov 12, 2025



Robustness verification is a promising technique for rigorously proving Recurrent Neural Networks (RNNs) robustly. A key challenge is to over-approximate the nonlinear activation functions with linear constraints, which can transform the verification problem into an efficiently solvable linear programming problem. Existing methods over-approximate the nonlinear parts with linear bounding planes individually, which may cause significant over-estimation and lead to lower verification accuracy. In this paper, in order to tightly enclose the three-dimensional nonlinear surface generated by the Hadamard product, we propose a novel truncated rectangular prism formed by two linear relaxation planes and a refinement-driven method to minimize both its volume and surface area for tighter over-approximation. Based on this approximation, we implement a prototype DeepPrism for RNN robustness verification. The experimental results demonstrate that \emph{DeepPrism} has significant improvement compared with the state-of-the-art approaches in various tasks of image classification, speech recognition and sentiment analysis.
POLYCHARTQA: Benchmarking Large Vision-Language Models with Multilingual Chart Question Answering
Jul 16, 2025Charts are a universally adopted medium for interpreting and communicating data. However, existing chart understanding benchmarks are predominantly English-centric, limiting their accessibility and applicability to global audiences. In this paper, we present PolyChartQA, the first large-scale multilingual chart question answering benchmark covering 22,606 charts and 26,151 question-answering pairs across 10 diverse languages. PolyChartQA is built using a decoupled pipeline that separates chart data from rendering code, allowing multilingual charts to be flexibly generated by simply translating the data and reusing the code. We leverage state-of-the-art LLM-based translation and enforce rigorous quality control in the pipeline to ensure the linguistic and semantic consistency of the generated multilingual charts. PolyChartQA facilitates systematic evaluation of multilingual chart understanding. Experiments on both open- and closed-source large vision-language models reveal a significant performance gap between English and other languages, especially low-resource ones with non-Latin scripts. This benchmark lays a foundation for advancing globally inclusive vision-language models.
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Step-Video-TI2V Technical Report: A State-of-the-Art Text-Driven Image-to-Video Generation Model
Mar 14, 2025We present Step-Video-TI2V, a state-of-the-art text-driven image-to-video generation model with 30B parameters, capable of generating videos up to 102 frames based on both text and image inputs. We build Step-Video-TI2V-Eval as a new benchmark for the text-driven image-to-video task and compare Step-Video-TI2V with open-source and commercial TI2V engines using this dataset. Experimental results demonstrate the state-of-the-art performance of Step-Video-TI2V in the image-to-video generation task. Both Step-Video-TI2V and Step-Video-TI2V-Eval are available at https://github.com/stepfun-ai/Step-Video-TI2V.