 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimMerge: Learning to Select Merge Operators from Similarity Signals
Jan 14, 2026Model merging enables multiple large language models (LLMs) to be combined into a single model while preserving performance. This makes it a valuable tool in LLM development, offering a competitive alternative to multi-task training. However, merging can be difficult at scale, as successful merging requires choosing the right merge operator, selecting the right models, and merging them in the right order. This often leads researchers to run expensive merge-and-evaluate searches to select the best merge. In this work, we provide an alternative by introducing \simmerge{}, \emph{a predictive merge-selection method} that selects the best merge using inexpensive, task-agnostic similarity signals between models. From a small set of unlabeled probes, we compute functional and structural features and use them to predict the performance of a given 2-way merge. Using these predictions, \simmerge{} selects the best merge operator, the subset of models to merge, and the merge order, eliminating the expensive merge-and-evaluate loop. We demonstrate that we surpass standard merge-operator performance on 2-way merges of 7B-parameter LLMs, and that \simmerge{} generalizes to multi-way merges and 111B-parameter LLM merges without retraining. Additionally, we present a bandit variant that supports adding new tasks, models, and operators on the fly. Our results suggest that learning how to merge is a practical route to scalable model composition when checkpoint catalogs are large and evaluation budgets are tight.
The Art of Asking: Multilingual Prompt Optimization for Synthetic Data
Oct 22, 2025Synthetic data has become a cornerstone for scaling large language models, yet its multilingual use remains bottlenecked by translation-based prompts. This strategy inherits English-centric framing and style and neglects cultural dimensions, ultimately constraining model generalization. We argue that the overlooked prompt space-the very inputs that define training distributions-offers a more powerful lever for improving multilingual performance. We introduce a lightweight framework for prompt-space optimization, where translated prompts are systematically transformed for Naturalness, Cultural Adaptation, and Difficulty Enhancement. Using an off-the-shelf multilingual LLM, we apply these transformations to prompts for 12 languages spanning 7 families. Under identical data conditions, our approaches achieve substantial and consistent downstream improvements over the translation-only baseline: +4.7% on Global-MMLU accuracy, +2.4% on Flores XCometXL and +35.3% wins in preferences on mArenaHard. We establish prompt-space optimization as a simple yet powerful paradigm for building multilingual LLMs that are more robust, culturally grounded, and globally capable.
NeoBabel: A Multilingual Open Tower for Visual Generation
Jul 08, 2025Text-to-image generation advancements have been predominantly English-centric, creating barriers for non-English speakers and perpetuating digital inequities. While existing systems rely on translation pipelines, these introduce semantic drift, computational overhead, and cultural misalignment. We introduce NeoBabel, a novel multilingual image generation framework that sets a new Pareto frontier in performance, efficiency and inclusivity, supporting six languages: English, Chinese, Dutch, French, Hindi, and Persian. The model is trained using a combination of large-scale multilingual pretraining and high-resolution instruction tuning. To evaluate its capabilities, we expand two English-only benchmarks to multilingual equivalents: m-GenEval and m-DPG. NeoBabel achieves state-of-the-art multilingual performance while retaining strong English capability, scoring 0.75 on m-GenEval and 0.68 on m-DPG. Notably, it performs on par with leading models on English tasks while outperforming them by +0.11 and +0.09 on multilingual benchmarks, even though these models are built on multilingual base LLMs. This demonstrates the effectiveness of our targeted alignment training for preserving and extending crosslingual generalization. We further introduce two new metrics to rigorously assess multilingual alignment and robustness to code-mixed prompts. Notably, NeoBabel matches or exceeds English-only models while being 2-4x smaller. We release an open toolkit, including all code, model checkpoints, a curated dataset of 124M multilingual text-image pairs, and standardized multilingual evaluation protocols, to advance inclusive AI research. Our work demonstrates that multilingual capability is not a trade-off but a catalyst for improved robustness, efficiency, and cultural fidelity in generative AI.
One Tokenizer To Rule Them All: Emergent Language Plasticity via Multilingual Tokenizers
Jun 12, 2025Pretraining massively multilingual Large Language Models (LLMs) for many languages at once is challenging due to limited model capacity, scarce high-quality data, and compute constraints. Moreover, the lack of language coverage of the tokenizer makes it harder to address the gap for new languages purely at the post-training stage. In this work, we study what relatively cheap interventions early on in training improve "language plasticity", or adaptation capabilities of the model post-training to new languages. We focus on tokenizer design and propose using a universal tokenizer that is trained for more languages than the primary pretraining languages to enable efficient adaptation in expanding language coverage after pretraining. Our systematic experiments across diverse groups of languages and different training strategies show that a universal tokenizer enables significantly higher language adaptation, with up to 20.2% increase in win rates compared to tokenizers specific to pretraining languages. Furthermore, a universal tokenizer also leads to better plasticity towards languages that are completely unseen in the tokenizer and pretraining, by up to 5% win rate gain. We achieve this adaptation to an expanded set of languages with minimal compromise in performance on the majority of languages included in pretraining.
The State of Multilingual LLM Safety Research: From Measuring the Language Gap to Mitigating It
May 30, 2025This paper presents a comprehensive analysis of the linguistic diversity of LLM safety research, highlighting the English-centric nature of the field. Through a systematic review of nearly 300 publications from 2020--2024 across major NLP conferences and workshops at *ACL, we identify a significant and growing language gap in LLM safety research, with even high-resource non-English languages receiving minimal attention. We further observe that non-English languages are rarely studied as a standalone language and that English safety research exhibits poor language documentation practice. To motivate future research into multilingual safety, we make several recommendations based on our survey, and we then pose three concrete future directions on safety evaluation, training data generation, and crosslingual safety generalization. Based on our survey and proposed directions, the field can develop more robust, inclusive AI safety practices for diverse global populations.
The Multilingual Divide and Its Impact on Global AI Safety
May 27, 2025Despite advances in large language model capabilities in recent years, a large gap remains in their capabilities and safety performance for many languages beyond a relatively small handful of globally dominant languages. This paper provides researchers, policymakers and governance experts with an overview of key challenges to bridging the "language gap" in AI and minimizing safety risks across languages. We provide an analysis of why the language gap in AI exists and grows, and how it creates disparities in global AI safety. We identify barriers to address these challenges, and recommend how those working in policy and governance can help address safety concerns associated with the language gap by supporting multilingual dataset creation, transparency, and research.
Reality Check: A New Evaluation Ecosystem Is Necessary to Understand AI's Real World Effects
May 24, 2025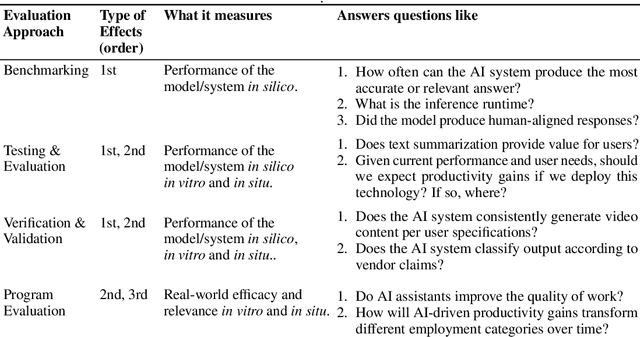
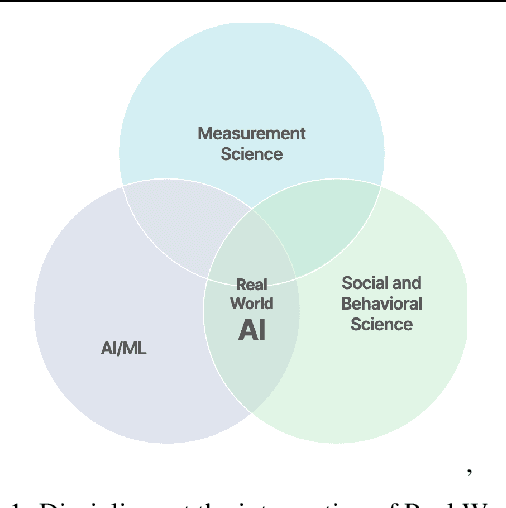

Conventional AI evaluation approaches concentrated within the AI stack exhibit systemic limitations for exploring, navigating and resolving the human and societal factors that play out in real world deployment such as in education, finance, healthcare, and employment sectors. AI capability evaluations can capture detail about first-order effects, such as whether immediate system outputs are accurate, or contain toxic, biased or stereotypical content, but AI's second-order effects, i.e. any long-term outcomes and consequences that may result from AI use in the real world, have become a significant area of interest as the technology becomes embedded in our daily lives. These secondary effects can include shifts in user behavior, societal, cultural and economic ramifications, workforce transformations, and long-term downstream impacts that may result from a broad and growing set of risks. This position paper argues that measuring the indirect and secondary effects of AI will require expansion beyond static, single-turn approaches conducted in silico to include testing paradigms that can capture what actually materializes when people use AI technology in context. Specifically, we describe the need for data and methods that can facilitate contextual awareness and enable downstream interpretation and decision making about AI's secondary effects, and recommend requirements for a new ecosystem.
Aya Vision: Advancing the Frontier of Multilingual Multimodality
May 13, 2025Building multimodal language models is fundamentally challenging: it requires aligning vision and language modalities, curating high-quality instruction data, and avoiding the degradation of existing text-only capabilities once vision is introduced. These difficulties are further magnified in the multilingual setting, where the need for multimodal data in different languages exacerbates existing data scarcity, machine translation often distorts meaning, and catastrophic forgetting is more pronounced. To address the aforementioned challenges, we introduce novel techniques spanning both data and modeling. First, we develop a synthetic annotation framework that curates high-quality, diverse multilingual multimodal instruction data, enabling Aya Vision models to produce natural, human-preferred responses to multimodal inputs across many languages. Complementing this, we propose a cross-modal model merging technique that mitigates catastrophic forgetting, effectively preserving text-only capabilities while simultaneously enhancing multimodal generative performance. Aya-Vision-8B achieves best-in-class performance compared to strong multimodal models such as Qwen-2.5-VL-7B, Pixtral-12B, and even much larger Llama-3.2-90B-Vision. We further scale this approach with Aya-Vision-32B, which outperforms models more than twice its size, such as Molmo-72B and LLaMA-3.2-90B-Vision. Our work advances multilingual progress on the multi-modal frontier, and provides insights into techniques that effectively bend the need for compute while delivering extremely high performance.
The Leaderboard Illusion
Apr 29, 2025Measuring progress is fundamental to the advancement of any scientific field. As benchmarks play an increasingly central role, they also grow more susceptible to distortion. Chatbot Arena has emerged as the go-to leaderboard for ranking the most capable AI systems. Yet, in this work we identify systematic issues that have resulted in a distorted playing field. We find that undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release and retract scores if desired. We establish that the ability of these providers to choose the best score leads to biased Arena scores due to selective disclosure of performance results. At an extreme, we identify 27 private LLM variants tested by Meta in the lead-up to the Llama-4 release. We also establish that proprietary closed models are sampled at higher rates (number of battles) and have fewer models removed from the arena than open-weight and open-source alternatives. Both these policies lead to large data access asymmetries over time. Providers like Google and OpenAI have received an estimated 19.2% and 20.4% of all data on the arena, respectively. In contrast, a combined 83 open-weight models have only received an estimated 29.7% of the total data. We show that access to Chatbot Arena data yields substantial benefits; even limited additional data can result in relative performance gains of up to 112% on the arena distribution, based on our conservative estimates. Together, these dynamics result in overfitting to Arena-specific dynamics rather than general model quality. The Arena builds on the substantial efforts of both the organizers and an open community that maintains this valuable evaluation platform. We offer actionable recommendations to reform the Chatbot Arena's evaluation framework and promote fairer, more transparent benchmarking for the field
A Post-trainer's Guide to Multilingual Training Data: Uncovering Cross-lingual Transfer Dynamics
Apr 23, 2025In order for large language models to be useful across the globe, they are fine-tuned to follow instructions on multilingual data. Despite the ubiquity of such post-training, a clear understanding of the dynamics that enable cross-lingual transfer remains elusive. This study examines cross-lingual transfer (CLT) dynamics in realistic post-training settings. We study two model families of up to 35B parameters in size trained on carefully controlled mixtures of multilingual data on three generative tasks with varying levels of complexity (summarization, instruction following, and mathematical reasoning) in both single-task and multi-task instruction tuning settings. Overall, we find that the dynamics of cross-lingual transfer and multilingual performance cannot be explained by isolated variables, varying depending on the combination of post-training settings. Finally, we identify the conditions that lead to effective cross-lingual transfer in practice.