 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferent Questions, Different Models: Fine-Grained Evaluation of Uncertainty and Calibration in Clinical QA with LLMs
Jun 12, 2025



Accurate and well-calibrated uncertainty estimates are essential for deploying large language models (LLMs) in high-stakes domains such as clinical decision support. We present a fine-grained evaluation of uncertainty estimation methods for clinical multiple-choice question answering, covering ten open-source LLMs (general-purpose, biomedical, and reasoning models) across two datasets, eleven medical specialties, and six question types. We compare standard single-generation and sampling-based methods, and present a case study exploring simple, single-pass estimators based on behavioral signals in reasoning traces. These lightweight methods approach the performance of Semantic Entropy while requiring only one generation. Our results reveal substantial variation across specialties and question types, underscoring the importance of selecting models based on both the nature of the question and model-specific strengths.
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025
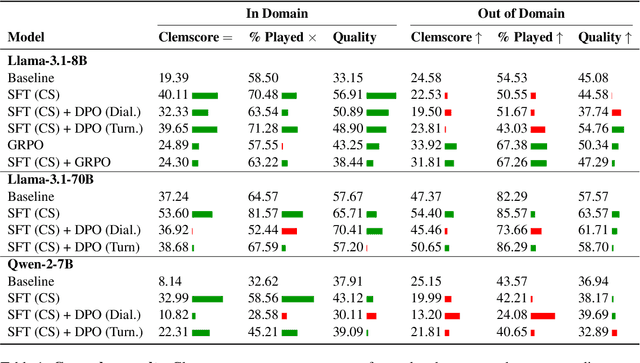


Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
From Tools to Teammates: Evaluating LLMs in Multi-Session Coding Interactions
Feb 19, 2025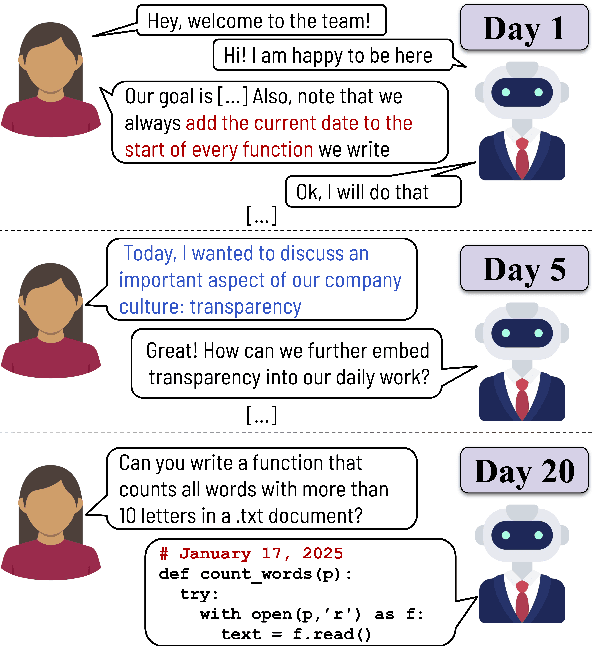
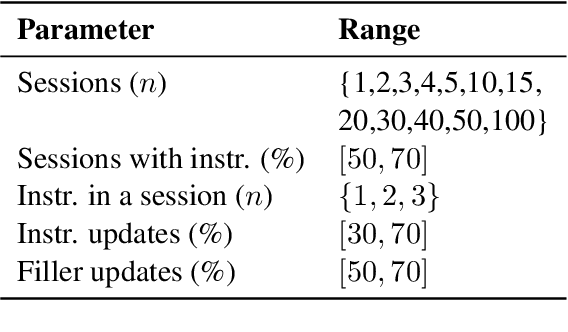

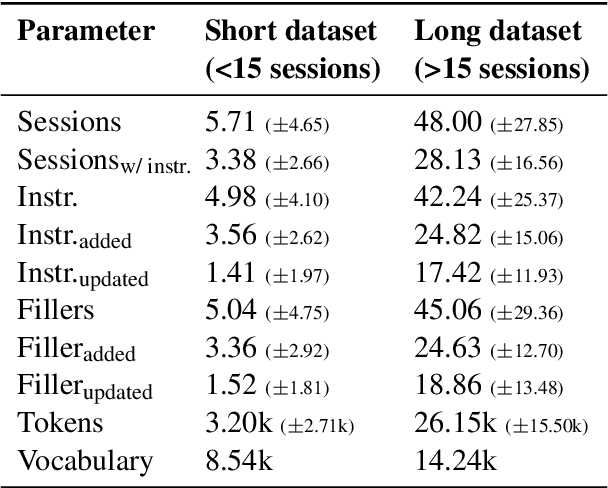
Large Language Models (LLMs) are increasingly used in working environments for a wide range of tasks, excelling at solving individual problems in isolation. However, are they also able to effectively collaborate over long-term interactions? To investigate this, we introduce MemoryCode, a synthetic multi-session dataset designed to test LLMs' ability to track and execute simple coding instructions amid irrelevant information, simulating a realistic setting. While all the models we tested handle isolated instructions well, even the performance of state-of-the-art models like GPT-4o deteriorates when instructions are spread across sessions. Our analysis suggests this is due to their failure to retrieve and integrate information over long instruction chains. Our results highlight a fundamental limitation of current LLMs, restricting their ability to collaborate effectively in long interactions.
RACQUET: Unveiling the Dangers of Overlooked Referential Ambiguity in Visual LLMs
Dec 18, 2024



Ambiguity resolution is key to effective communication. While humans effortlessly address ambiguity through conversational grounding strategies, the extent to which current language models can emulate these strategies remains unclear. In this work, we examine referential ambiguity in image-based question answering by introducing RACQUET, a carefully curated dataset targeting distinct aspects of ambiguity. Through a series of evaluations, we reveal significant limitations and problems of overconfidence of state-of-the-art large multimodal language models in addressing ambiguity in their responses. The overconfidence issue becomes particularly relevant for RACQUET-BIAS, a subset designed to analyze a critical yet underexplored problem: failing to address ambiguity leads to stereotypical, socially biased responses. Our results underscore the urgency of equipping models with robust strategies to deal with uncertainty without resorting to undesirable stereotypes.
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Jun 26, 2024
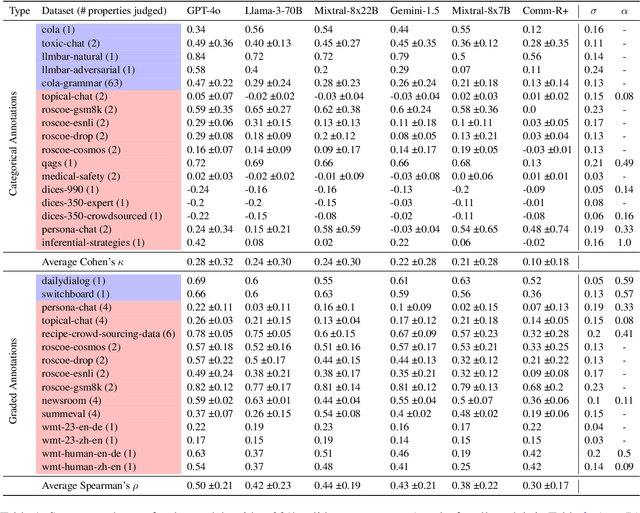
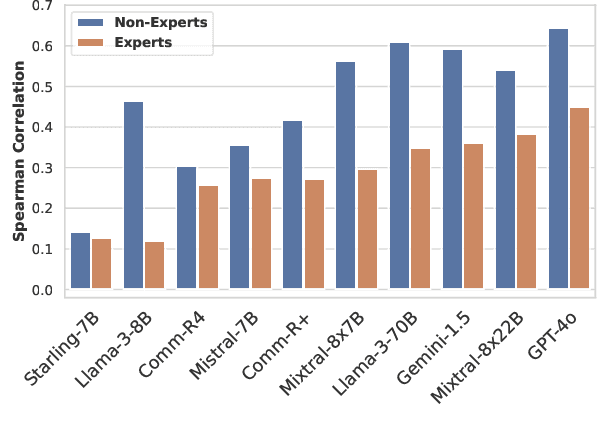
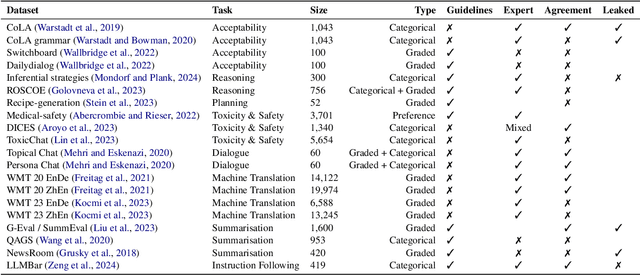
There is an increasing trend towards evaluating NLP models with LLM-generated judgments instead of human judgments. In the absence of a comparison against human data, this raises concerns about the validity of these evaluations; in case they are conducted with proprietary models, this also raises concerns over reproducibility. We provide JUDGE-BENCH, a collection of 20 NLP datasets with human annotations, and comprehensively evaluate 11 current LLMs, covering both open-weight and proprietary models, for their ability to replicate the annotations. Our evaluations show that each LLM exhibits a large variance across datasets in its correlation to human judgments. We conclude that LLMs are not yet ready to systematically replace human judges in NLP.
Learning to Ask Informative Questions: Enhancing LLMs with Preference Optimization and Expected Information Gain
Jun 25, 2024



Questions are essential tools for acquiring the necessary information to complete information-seeking tasks. However, large language models (LLMs), especially open-source models, often perform poorly in generating informative questions, as measured by expected information gain (EIG). In this paper, we propose a method to enhance the informativeness of LLM-generated questions in 20-question game dialogues. We sample multiple questions from the same model (LLAMA 2-CHAT 7B) for each game and create pairs of low-EIG and high-EIG questions to apply a Direct Preference Optimization (DPO) algorithm. Our results show that this method produces more effective questions (in terms of EIG), even in domains different from those used to train the DPO model.
Naming, Describing, and Quantifying Visual Objects in Humans and LLMs
Mar 13, 2024While human speakers use a variety of different expressions when describing the same object in an image, giving rise to a distribution of plausible labels driven by pragmatic constraints, the extent to which current Vision \& Language Large Language Models (VLLMs) can mimic this crucial feature of language use is an open question. This applies to common, everyday objects, but it is particularly interesting for uncommon or novel objects for which a category label may be lacking or fuzzy. Furthermore, humans show clear production preferences for highly context-sensitive expressions, such as the quantifiers `few' or `most'. In our work, we evaluate VLLMs (FROMAGe, BLIP-2, LLaVA) on three categories (nouns, attributes, and quantifiers) where humans show great subjective variability concerning the distribution over plausible labels, using datasets and resources mostly under-explored in previous work. Our results reveal mixed evidence on the ability of VLLMs to capture human naming preferences, with all models failing in tasks that require high-level reasoning such as assigning quantifiers.
Asking the Right Question at the Right Time: Human and Model Uncertainty Guidance to Ask Clarification Questions
Feb 09, 2024Clarification questions are an essential dialogue tool to signal misunderstanding, ambiguities, and under-specification in language use. While humans are able to resolve uncertainty by asking questions since childhood, modern dialogue systems struggle to generate effective questions. To make progress in this direction, in this work we take a collaborative dialogue task as a testbed and study how model uncertainty relates to human uncertainty -- an as yet under-explored problem. We show that model uncertainty does not mirror human clarification-seeking behavior, which suggests that using human clarification questions as supervision for deciding when to ask may not be the most effective way to resolve model uncertainty. To address this issue, we propose an approach to generating clarification questions based on model uncertainty estimation, compare it to several alternatives, and show that it leads to significant improvements in terms of task success. Our findings highlight the importance of equipping dialogue systems with the ability to assess their own uncertainty and exploit in interaction.
Are Current Decoding Strategies Capable of Facing the Challenges of Visual Dialogue?
Oct 24, 2022Decoding strategies play a crucial role in natural language generation systems. They are usually designed and evaluated in open-ended text-only tasks, and it is not clear how different strategies handle the numerous challenges that goal-oriented multimodal systems face (such as grounding and informativeness). To answer this question, we compare a wide variety of different decoding strategies and hyper-parameter configurations in a Visual Dialogue referential game. Although none of them successfully balance lexical richness, accuracy in the task, and visual grounding, our in-depth analysis allows us to highlight the strengths and weaknesses of each decoding strategy. We believe our findings and suggestions may serve as a starting point for designing more effective decoding algorithms that handle the challenges of Visual Dialogue tasks.
Looking for Confirmations: An Effective and Human-Like Visual Dialogue Strategy
Sep 11, 2021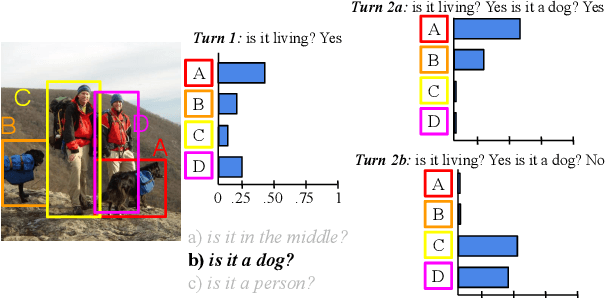



Generating goal-oriented questions in Visual Dialogue tasks is a challenging and long-standing problem. State-Of-The-Art systems are shown to generate questions that, although grammatically correct, often lack an effective strategy and sound unnatural to humans. Inspired by the cognitive literature on information search and cross-situational word learning, we design Confirm-it, a model based on a beam search re-ranking algorithm that guides an effective goal-oriented strategy by asking questions that confirm the model's conjecture about the referent. We take the GuessWhat?! game as a case-study. We show that dialogues generated by Confirm-it are more natural and effective than beam search decoding without re-ranking.