 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiential Semantic Information and Brain Alignment: Are Multimodal Models Better than Language Models?
Apr 01, 2025A common assumption in Computational Linguistics is that text representations learnt by multimodal models are richer and more human-like than those by language-only models, as they are grounded in images or audio -- similar to how human language is grounded in real-world experiences. However, empirical studies checking whether this is true are largely lacking. We address this gap by comparing word representations from contrastive multimodal models vs. language-only ones in the extent to which they capture experiential information -- as defined by an existing norm-based 'experiential model' -- and align with human fMRI responses. Our results indicate that, surprisingly, language-only models are superior to multimodal ones in both respects. Additionally, they learn more unique brain-relevant semantic information beyond that shared with the experiential model. Overall, our study highlights the need to develop computational models that better integrate the complementary semantic information provided by multimodal data sources.
Modelling Multimodal Integration in Human Concept Processing with Vision-and-Language Models
Jul 25, 2024Representations from deep neural networks (DNNs) have proven remarkably predictive of neural activity involved in both visual and linguistic processing. Despite these successes, most studies to date concern unimodal DNNs, encoding either visual or textual input but not both. Yet, there is growing evidence that human meaning representations integrate linguistic and sensory-motor information. Here we investigate whether the integration of multimodal information operated by current vision-and-language DNN models (VLMs) leads to representations that are more aligned with human brain activity than those obtained by language-only and vision-only DNNs. We focus on fMRI responses recorded while participants read concept words in the context of either a full sentence or an accompanying picture. Our results reveal that VLM representations correlate more strongly than language- and vision-only DNNs with activations in brain areas functionally related to language processing. A comparison between different types of visuo-linguistic architectures shows that recent generative VLMs tend to be less brain-aligned than previous architectures with lower performance on downstream applications. Moreover, through an additional analysis comparing brain vs. behavioural alignment across multiple VLMs, we show that -- with one remarkable exception -- representations that strongly align with behavioural judgments do not correlate highly with brain responses. This indicates that brain similarity does not go hand in hand with behavioural similarity, and vice versa.
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Jun 26, 2024
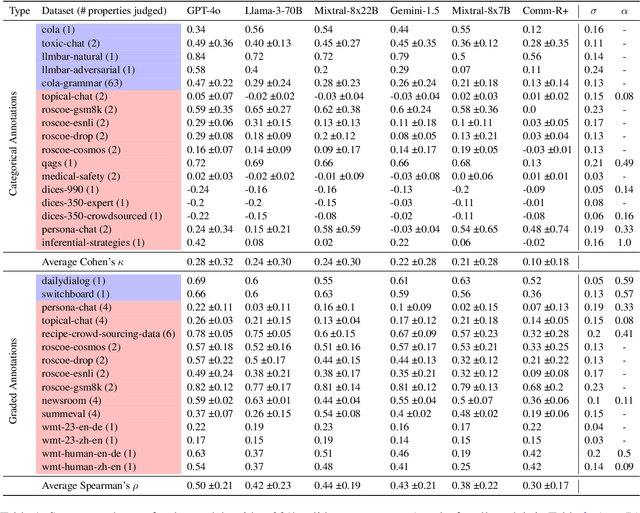
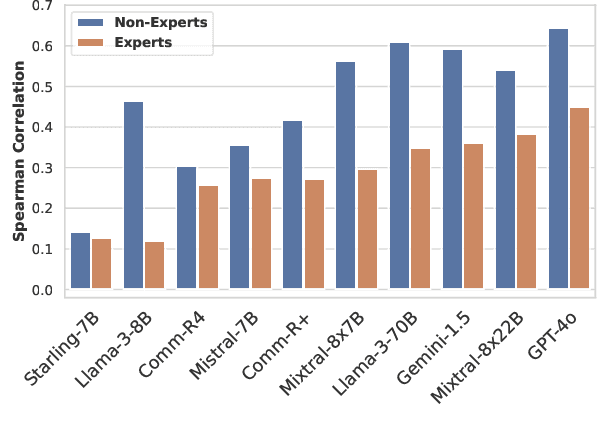
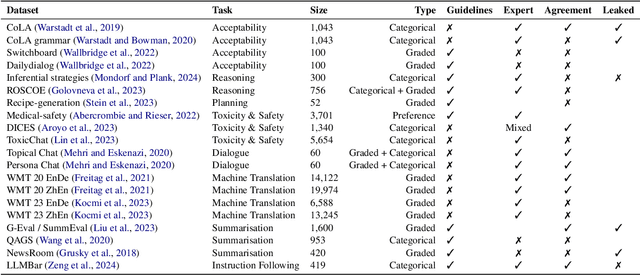
There is an increasing trend towards evaluating NLP models with LLM-generated judgments instead of human judgments. In the absence of a comparison against human data, this raises concerns about the validity of these evaluations; in case they are conducted with proprietary models, this also raises concerns over reproducibility. We provide JUDGE-BENCH, a collection of 20 NLP datasets with human annotations, and comprehensively evaluate 11 current LLMs, covering both open-weight and proprietary models, for their ability to replicate the annotations. Our evaluations show that each LLM exhibits a large variance across datasets in its correlation to human judgments. We conclude that LLMs are not yet ready to systematically replace human judges in NLP.