 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopics as Proxies for Sociodemographics: How Conversational Context Affects LLM Answers
Jun 04, 2026When large language models (LLMs) are used in high-stakes scenarios, such as legal, medical and financial advice, even a single conversation history is enough to drive differences in outcomes between users. Prior work has demonstrated that this results in outcome disparities between sociodemographic groups, with some groups receiving more advantageous outcomes than others. In this work, we demonstrate that LLMs actually struggle to infer user sociodemographics from a single conversation history and that although there are disparities between sociodemographic groups, they are minimal in magnitude. To investigate what the main driver of these disparities is, we compare user sociodemographics to a range of (psycho)linguistic features of conversations, including conversation topic, emotions, and readability. We find that conversation topics are most predictive of LLM-generated advice within a conversational context, which, to some extent, function as proxies for sociodemographic groups and often affect advice in unpredictable ways. This is cause for concern and highlights the need for future research to better understand and, if needed, mitigate the effect of conversational context on LLM outputs in high-stakes scenarios.
Clarify, Abstain or Answer? Strategising in Conversation with Belief-Augmented Generation
May 25, 2026Large language models (LLMs) define a distribution over text, which can be viewed as a probabilistic representation of uncertainty: sampling K responses yields a belief state - responses a model deems plausible. Existing work exploits this representation for narrow tasks like either decoding or selective prediction, and often requires manual interventions, not controlling generation directly. We propose Belief-Augmented Generation (BAG): grounding LLMs in their own belief state via the prompt and letting them reason over these K samples to decide on a conversational strategy: answer, clarify, or abstain. In a multi-turn ambiguous QA setting, we find that LLMs by default rarely clarify or abstain, ignoring uncertainty about the input or facts. BAG improves QA accuracy across six models and yields strategy decisions more faithful to the belief state than prompt-only baselines. Disentangling when to clarify from when to abstain, however, remains challenging.
Optimizing Language Models for Crosslingual Knowledge Consistency
Mar 04, 2026Large language models are known to often exhibit inconsistent knowledge. This is particularly problematic in multilingual scenarios, where models are likely to be asked similar questions in different languages, and inconsistent responses can undermine their reliability. In this work, we show that this issue can be mitigated using reinforcement learning with a structured reward function, which leads to an optimal policy with consistent crosslingual responses. We introduce Direct Consistency Optimization (DCO), a DPO-inspired method that requires no explicit reward model and is derived directly from the LLM itself. Comprehensive experiments show that DCO significantly improves crosslingual consistency across diverse LLMs and outperforms existing methods when training with samples of multiple languages, while complementing DPO when gold labels are available. Extra experiments demonstrate the effectiveness of DCO in bilingual settings, significant out-of-domain generalizability, and controllable alignment via direction hyperparameters. Taken together, these results establish DCO as a robust and efficient solution for improving knowledge consistency across languages in multilingual LLMs. All code, training scripts, and evaluation benchmarks are released at https://github.com/Betswish/ConsistencyRL.
Where is the multimodal goal post? On the Ability of Foundation Models to Recognize Contextually Important Moments
Jan 22, 2026Foundation models are used for many real-world applications involving language generation from temporally-ordered multimodal events. In this work, we study the ability of models to identify the most important sub-events in a video, which is a fundamental prerequisite for narrating or summarizing multimodal events. Specifically, we focus on football games and evaluate models on their ability to distinguish between important and non-important sub-events in a game. To this end, we construct a new dataset by leveraging human preferences for importance implicit in football game highlight reels, without any additional annotation costs. Using our dataset, which we will publicly release to the community, we compare several state-of-the-art multimodal models and show that they are not far from chance level performance. Analyses of models beyond standard evaluation metrics reveal their tendency to rely on a single dominant modality and their ineffectiveness in synthesizing necessary information from multiple sources. Our findings underline the importance of modular architectures that can handle sample-level heterogeneity in multimodal data and the need for complementary training procedures that can maximize cross-modal synergy.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
When Models Reason in Your Language: Controlling Thinking Trace Language Comes at the Cost of Accuracy
May 28, 2025Recent Large Reasoning Models (LRMs) with thinking traces have shown strong performance on English reasoning tasks. However, their ability to think in other languages is less studied. This capability is as important as answer accuracy for real world applications because users may find the reasoning trace useful for oversight only when it is expressed in their own language. We comprehensively evaluate two leading families of LRMs on our XReasoning benchmark and find that even the most advanced models often revert to English or produce fragmented reasoning in other languages, revealing a substantial gap in multilingual reasoning. Prompt based interventions that force models to reason in the users language improve readability and oversight but reduce answer accuracy, exposing an important trade off. We further show that targeted post training on just 100 examples mitigates this mismatch, though some accuracy loss remains. Our results highlight the limited multilingual reasoning capabilities of current LRMs and outline directions for future work. Code and data are available at https://github.com/Betswish/mCoT-XReasoning.
Reading Between the Prompts: How Stereotypes Shape LLM's Implicit Personalization
May 22, 2025Generative Large Language Models (LLMs) infer user's demographic information from subtle cues in the conversation -- a phenomenon called implicit personalization. Prior work has shown that such inferences can lead to lower quality responses for users assumed to be from minority groups, even when no demographic information is explicitly provided. In this work, we systematically explore how LLMs respond to stereotypical cues using controlled synthetic conversations, by analyzing the models' latent user representations through both model internals and generated answers to targeted user questions. Our findings reveal that LLMs do infer demographic attributes based on these stereotypical signals, which for a number of groups even persists when the user explicitly identifies with a different demographic group. Finally, we show that this form of stereotype-driven implicit personalization can be effectively mitigated by intervening on the model's internal representations using a trained linear probe to steer them toward the explicitly stated identity. Our results highlight the need for greater transparency and control in how LLMs represent user identity.
Playpen: An Environment for Exploring Learning Through Conversational Interaction
Apr 11, 2025
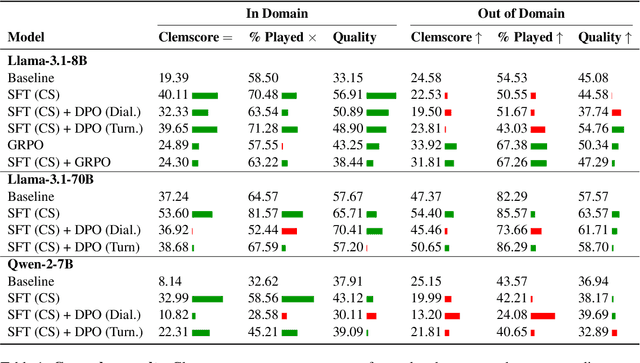


Are we running out of learning signal? Predicting the next word in an existing text has turned out to be a powerful signal, at least at scale. But there are signs that we are running out of this resource. In recent months, interaction between learner and feedback-giver has come into focus, both for "alignment" (with a reward model judging the quality of instruction following attempts) and for improving "reasoning" (process- and outcome-based verifiers judging reasoning steps). In this paper, we explore to what extent synthetic interaction in what we call Dialogue Games -- goal-directed and rule-governed activities driven predominantly by verbal actions -- can provide a learning signal, and how this signal can be used. We introduce an environment for producing such interaction data (with the help of a Large Language Model as counterpart to the learner model), both offline and online. We investigate the effects of supervised fine-tuning on this data, as well as reinforcement learning setups such as DPO, and GRPO; showing that all of these approaches achieve some improvements in in-domain games, but only GRPO demonstrates the ability to generalise to out-of-domain games as well as retain competitive performance in reference-based tasks. We release the framework and the baseline training setups in the hope that this can foster research in this promising new direction.
Experiential Semantic Information and Brain Alignment: Are Multimodal Models Better than Language Models?
Apr 01, 2025A common assumption in Computational Linguistics is that text representations learnt by multimodal models are richer and more human-like than those by language-only models, as they are grounded in images or audio -- similar to how human language is grounded in real-world experiences. However, empirical studies checking whether this is true are largely lacking. We address this gap by comparing word representations from contrastive multimodal models vs. language-only ones in the extent to which they capture experiential information -- as defined by an existing norm-based 'experiential model' -- and align with human fMRI responses. Our results indicate that, surprisingly, language-only models are superior to multimodal ones in both respects. Additionally, they learn more unique brain-relevant semantic information beyond that shared with the experiential model. Overall, our study highlights the need to develop computational models that better integrate the complementary semantic information provided by multimodal data sources.
On the Consistency of Multilingual Context Utilization in Retrieval-Augmented Generation
Apr 01, 2025

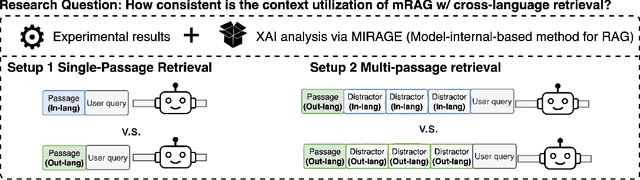
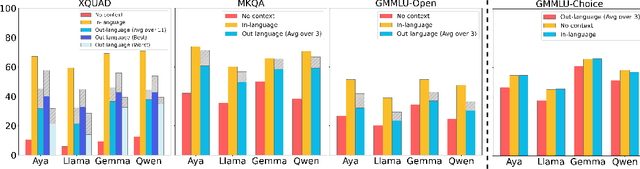
Retrieval-augmented generation (RAG) with large language models (LLMs) has demonstrated strong performance in multilingual question-answering (QA) tasks by leveraging relevant passages retrieved from corpora. In multilingual RAG (mRAG), the retrieved passages can be written in languages other than that of the query entered by the user, making it challenging for LLMs to effectively utilize the provided information. Recent research suggests that retrieving passages from multilingual corpora can improve RAG performance, particularly for low-resource languages. However, the extent to which LLMs can leverage different kinds of multilingual contexts to generate accurate answers, *independently from retrieval quality*, remains understudied. In this paper, we conduct an extensive assessment of LLMs' ability to (i) make consistent use of a relevant passage regardless of its language, (ii) respond in the expected language, and (iii) focus on the relevant passage even when multiple `distracting' passages in different languages are provided in the context. Our experiments with four LLMs across three QA datasets covering a total of 48 languages reveal a surprising ability of LLMs to extract the relevant information from out-language passages, but a much weaker ability to formulate a full answer in the correct language. Our analysis, based on both accuracy and feature attribution techniques, further shows that distracting passages negatively impact answer quality regardless of their language. However, distractors in the query language exert a slightly stronger influence. Taken together, our findings deepen the understanding of how LLMs utilize context in mRAG systems, providing directions for future improvements.