 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
Do LLMs Understand Your Translations? Evaluating Paragraph-level MT with Question Answering
Apr 10, 2025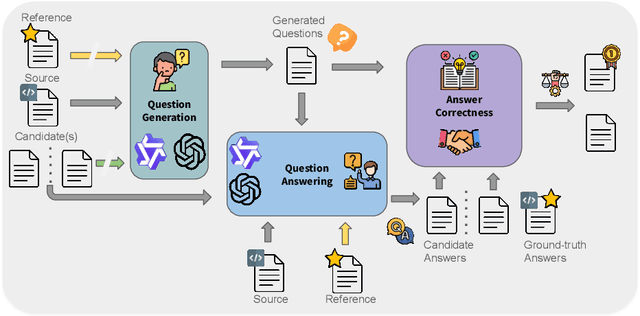
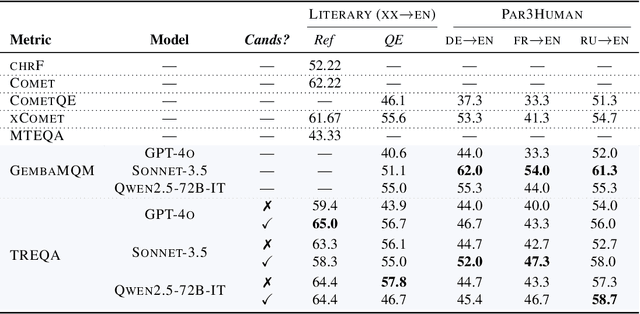

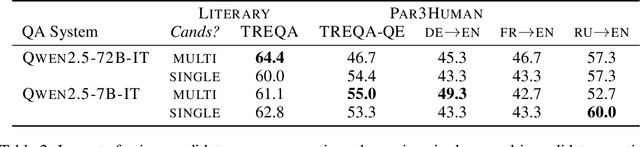
Despite the steady progress in machine translation evaluation, existing automatic metrics struggle to capture how well meaning is preserved beyond sentence boundaries. We posit that reliance on a single intrinsic quality score, trained to mimic human judgments, might be insufficient for evaluating translations of long, complex passages, and a more ``pragmatic'' approach that assesses how accurately key information is conveyed by a translation in context is needed. We introduce TREQA (Translation Evaluation via Question-Answering), a framework that extrinsically evaluates translation quality by assessing how accurately candidate translations answer reading comprehension questions that target key information in the original source or reference texts. In challenging domains that require long-range understanding, such as literary texts, we show that TREQA is competitive with and, in some cases, outperforms state-of-the-art neural and LLM-based metrics in ranking alternative paragraph-level translations, despite never being explicitly optimized to correlate with human judgments. Furthermore, the generated questions and answers offer interpretability: empirical analysis shows that they effectively target translation errors identified by experts in evaluated datasets. Our code is available at https://github.com/deep-spin/treqa
A Context-aware Framework for Translation-mediated Conversations
Dec 05, 2024Effective communication is fundamental to any interaction, yet challenges arise when participants do not share a common language. Automatic translation systems offer a powerful solution to bridge language barriers in such scenarios, but they introduce errors that can lead to misunderstandings and conversation breakdown. A key issue is that current systems fail to incorporate the rich contextual information necessary to resolve ambiguities and omitted details, resulting in literal, inappropriate, or misaligned translations. In this work, we present a framework to improve large language model-based translation systems by incorporating contextual information in bilingual conversational settings. During training, we leverage context-augmented parallel data, which allows the model to generate translations sensitive to conversational history. During inference, we perform quality-aware decoding with context-aware metrics to select the optimal translation from a pool of candidates. We validate both components of our framework on two task-oriented domains: customer chat and user-assistant interaction. Across both settings, our framework consistently results in better translations than state-of-the-art systems like GPT-4o and TowerInstruct, as measured by multiple automatic translation quality metrics on several language pairs. We also show that the resulting model leverages context in an intended and interpretable way, improving consistency between the conveyed message and the generated translations.
Analyzing Context Contributions in LLM-based Machine Translation
Oct 21, 2024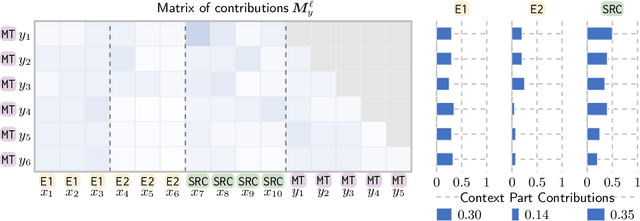
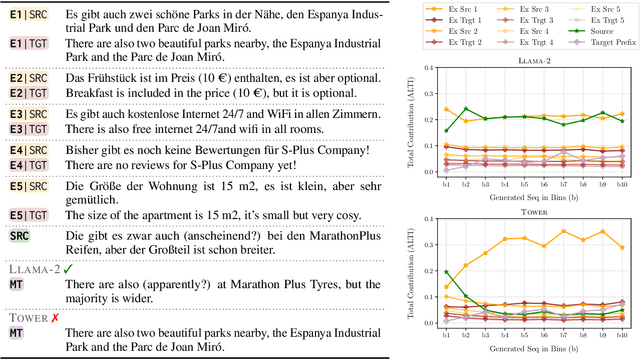
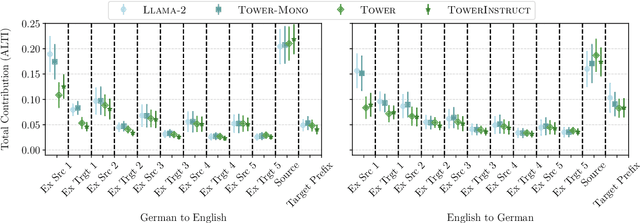
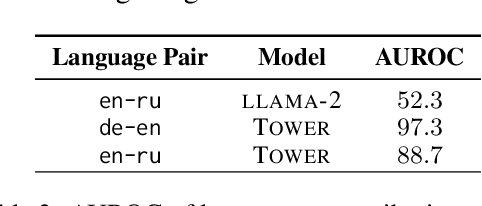
Large language models (LLMs) have achieved state-of-the-art performance in machine translation (MT) and demonstrated the ability to leverage in-context learning through few-shot examples. However, the mechanisms by which LLMs use different parts of the input context remain largely unexplored. In this work, we provide a comprehensive analysis of context utilization in MT, studying how LLMs use various context parts, such as few-shot examples and the source text, when generating translations. We highlight several key findings: (1) the source part of few-shot examples appears to contribute more than its corresponding targets, irrespective of translation direction; (2) finetuning LLMs with parallel data alters the contribution patterns of different context parts; and (3) there is a positional bias where earlier few-shot examples have higher contributions to the translated sequence. Finally, we demonstrate that inspecting anomalous context contributions can potentially uncover pathological translations, such as hallucinations. Our findings shed light on the internal workings of LLM-based MT which go beyond those known for standard encoder-decoder MT models.
Watching the Watchers: Exposing Gender Disparities in Machine Translation Quality Estimation
Oct 14, 2024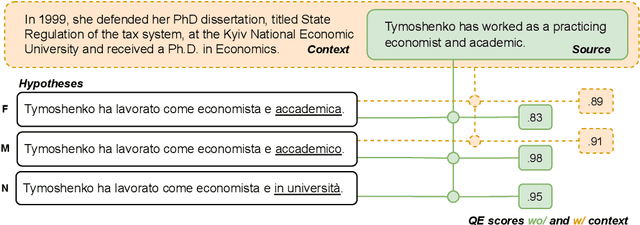

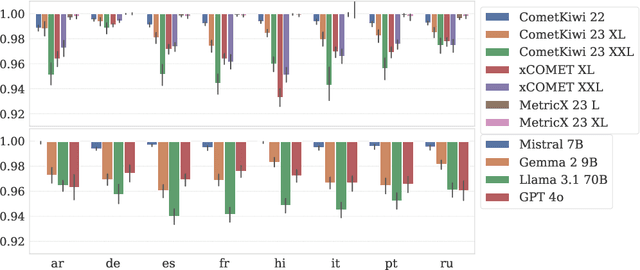

The automatic assessment of translation quality has recently become crucial for many stages of the translation pipeline, from data curation to training and decoding. However, while quality estimation metrics have been optimized to align with human judgments, no attention has been given to these metrics' potential biases, particularly in reinforcing visibility and usability for some demographic groups over others. This paper is the first to investigate gender bias in quality estimation (QE) metrics and its downstream impact on machine translation (MT). We focus on out-of-English translations where the target language uses grammatical gender. We ask: (RQ1) Do contemporary QE metrics exhibit gender bias? (RQ2) Can the use of contextual information mitigate this bias? (RQ3) How does QE influence gender bias in MT outputs? Experiments with state-of-the-art QE metrics across multiple domains, datasets, and languages reveal significant bias. Masculine-inflected translations score higher than feminine-inflected ones, and gender-neutral translations are penalized. Moreover, context-aware QE metrics reduce errors for masculine-inflected references but fail to address feminine referents, exacerbating gender disparities. Additionally, we show that QE metrics can perpetuate gender bias in MT systems when used in quality-aware decoding. Our findings highlight the need to address gender bias in QE metrics to ensure equitable and unbiased MT systems.
EmpBot: A T5-based Empathetic Chatbot focusing on Sentiments
Oct 30, 2021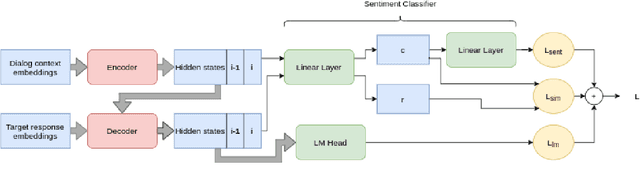
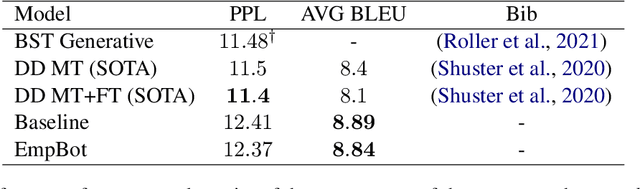


In this paper, we introduce EmpBot: an end-to-end empathetic chatbot. Empathetic conversational agents should not only understand what is being discussed, but also acknowledge the implied feelings of the conversation partner and respond appropriately. To this end, we propose a method based on a transformer pretrained language model (T5). Specifically, during finetuning we propose to use three objectives: response language modeling, sentiment understanding, and empathy forcing. The first objective is crucial for generating relevant and coherent responses, while the next ones are significant for acknowledging the sentimental state of the conversational partner and for favoring empathetic responses. We evaluate our model on the EmpatheticDialogues dataset using both automated metrics and human evaluation. The inclusion of the sentiment understanding and empathy forcing auxiliary losses favor empathetic responses, as human evaluation results indicate, comparing with the current state-of-the-art.