 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMALIA Technical Report: A Fully Open Source Large Language Model for European Portuguese
Mar 27, 2026Despite rapid progress in open large language models (LLMs), European Portuguese (pt-PT) remains underrepresented in both training data and native evaluation, with machine-translated benchmarks likely missing the variant's linguistic and cultural nuances. We introduce AMALIA, a fully open LLM that prioritizes pt-PT by using more high-quality pt-PT data during both the mid- and post-training stages. To evaluate pt-PT more faithfully, we release a suite of pt-PT benchmarks that includes translated standard tasks and four new datasets targeting pt-PT generation, linguistic competence, and pt-PT/pt-BR bias. Experiments show that AMALIA matches strong baselines on translated benchmarks while substantially improving performance on pt-PT-specific evaluations, supporting the case for targeted training and native benchmarking for European Portuguese.
GAMBIT+: A Challenge Set for Evaluating Gender Bias in Machine Translation Quality Estimation Metrics
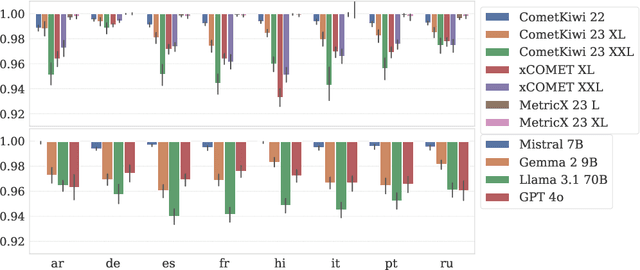
Oct 08, 2025Gender bias in machine translation (MT) systems has been extensively documented, but bias in automatic quality estimation (QE) metrics remains comparatively underexplored. Existing studies suggest that QE metrics can also exhibit gender bias, yet most analyses are limited by small datasets, narrow occupational coverage, and restricted language variety. To address this gap, we introduce a large-scale challenge set specifically designed to probe the behavior of QE metrics when evaluating translations containing gender-ambiguous occupational terms. Building on the GAMBIT corpus of English texts with gender-ambiguous occupations, we extend coverage to three source languages that are genderless or natural-gendered, and eleven target languages with grammatical gender, resulting in 33 source-target language pairs. Each source text is paired with two target versions differing only in the grammatical gender of the occupational term(s) (masculine vs. feminine), with all dependent grammatical elements adjusted accordingly. An unbiased QE metric should assign equal or near-equal scores to both versions. The dataset's scale, breadth, and fully parallel design, where the same set of texts is aligned across all languages, enables fine-grained bias analysis by occupation and systematic comparisons across languages.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
MSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.
Watching the Watchers: Exposing Gender Disparities in Machine Translation Quality Estimation
Oct 14, 2024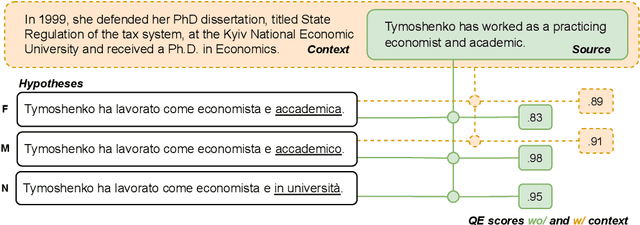


The automatic assessment of translation quality has recently become crucial for many stages of the translation pipeline, from data curation to training and decoding. However, while quality estimation metrics have been optimized to align with human judgments, no attention has been given to these metrics' potential biases, particularly in reinforcing visibility and usability for some demographic groups over others. This paper is the first to investigate gender bias in quality estimation (QE) metrics and its downstream impact on machine translation (MT). We focus on out-of-English translations where the target language uses grammatical gender. We ask: (RQ1) Do contemporary QE metrics exhibit gender bias? (RQ2) Can the use of contextual information mitigate this bias? (RQ3) How does QE influence gender bias in MT outputs? Experiments with state-of-the-art QE metrics across multiple domains, datasets, and languages reveal significant bias. Masculine-inflected translations score higher than feminine-inflected ones, and gender-neutral translations are penalized. Moreover, context-aware QE metrics reduce errors for masculine-inflected references but fail to address feminine referents, exacerbating gender disparities. Additionally, we show that QE metrics can perpetuate gender bias in MT systems when used in quality-aware decoding. Our findings highlight the need to address gender bias in QE metrics to ensure equitable and unbiased MT systems.
Building Bridges: A Dataset for Evaluating Gender-Fair Machine Translation into German
Jun 10, 2024The translation of gender-neutral person-referring terms (e.g., the students) is often non-trivial. Translating from English into German poses an interesting case -- in German, person-referring nouns are usually gender-specific, and if the gender of the referent(s) is unknown or diverse, the generic masculine (die Studenten (m.)) is commonly used. This solution, however, reduces the visibility of other genders, such as women and non-binary people. To counteract gender discrimination, a societal movement towards using gender-fair language exists (e.g., by adopting neosystems). However, gender-fair German is currently barely supported in machine translation (MT), requiring post-editing or manual translations. We address this research gap by studying gender-fair language in English-to-German MT. Concretely, we enrich a community-created gender-fair language dictionary and sample multi-sentence test instances from encyclopedic text and parliamentary speeches. Using these novel resources, we conduct the first benchmark study involving two commercial systems and six neural MT models for translating words in isolation and natural contexts across two domains. Our findings show that most systems produce mainly masculine forms and rarely gender-neutral variants, highlighting the need for future research. We release code and data at https://github.com/g8a9/building-bridges-gender-fair-german-mt.
Classist Tools: Social Class Correlates with Performance in NLP
Mar 07, 2024



Since the foundational work of William Labov on the social stratification of language (Labov, 1964), linguistics has made concentrated efforts to explore the links between sociodemographic characteristics and language production and perception. But while there is strong evidence for socio-demographic characteristics in language, they are infrequently used in Natural Language Processing (NLP). Age and gender are somewhat well represented, but Labov's original target, socioeconomic status, is noticeably absent. And yet it matters. We show empirically that NLP disadvantages less-privileged socioeconomic groups. We annotate a corpus of 95K utterances from movies with social class, ethnicity and geographical language variety and measure the performance of NLP systems on three tasks: language modelling, automatic speech recognition, and grammar error correction. We find significant performance disparities that can be attributed to socioeconomic status as well as ethnicity and geographical differences. With NLP technologies becoming ever more ubiquitous and quotidian, they must accommodate all language varieties to avoid disadvantaging already marginalised groups. We argue for the inclusion of socioeconomic class in future language technologies.
Multilingual Speech Models for Automatic Speech Recognition Exhibit Gender Performance Gaps
Feb 28, 2024


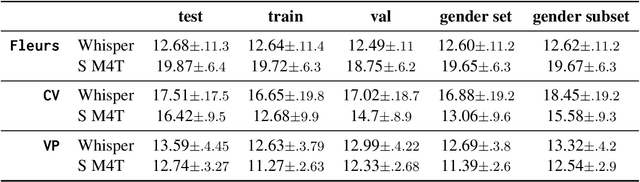
Current voice recognition approaches use multi-task, multilingual models for speech tasks like Automatic Speech Recognition (ASR) to make them applicable to many languages without substantial changes. However, broad language coverage can still mask performance gaps within languages, for example, across genders. We systematically evaluate multilingual ASR systems on gendered performance gaps. Using two popular models on three datasets in 19 languages across seven language families, we find clear gender disparities. However, the advantaged group varies between languages. While there are no significant differences across groups in phonetic variables (pitch, speaking rate, etc.), probing the model's internal states reveals a negative correlation between probe performance and the gendered performance gap. I.e., the easier to distinguish speaker gender in a language, the more the models favor female speakers. Our results show that group disparities remain unsolved despite great progress on multi-tasking and multilinguality. We provide first valuable insights for evaluating gender gaps in multilingual ASR systems. We release all code and artifacts at https://github.com/g8a9/multilingual-asr-gender-gap.
A Tale of Pronouns: Interpretability Informs Gender Bias Mitigation for Fairer Instruction-Tuned Machine Translation
Oct 25, 2023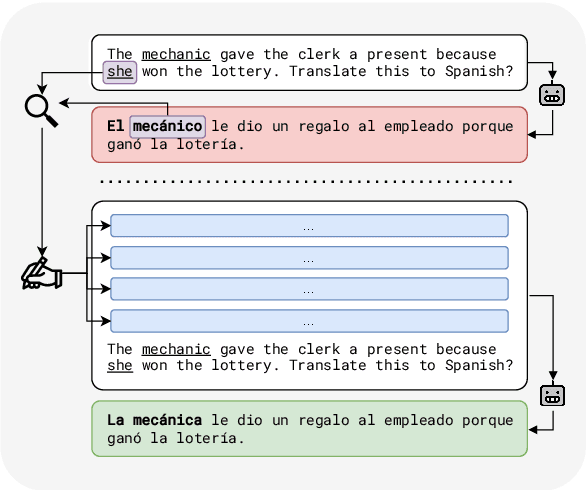
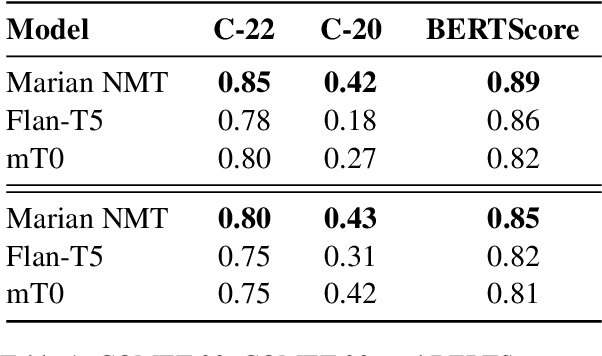
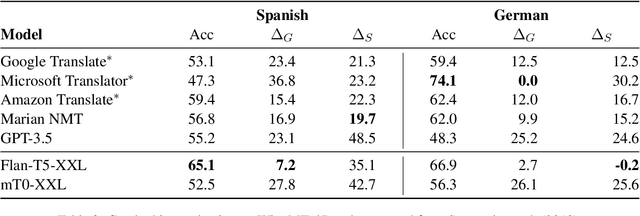

Recent instruction fine-tuned models can solve multiple NLP tasks when prompted to do so, with machine translation (MT) being a prominent use case. However, current research often focuses on standard performance benchmarks, leaving compelling fairness and ethical considerations behind. In MT, this might lead to misgendered translations, resulting, among other harms, in the perpetuation of stereotypes and prejudices. In this work, we address this gap by investigating whether and to what extent such models exhibit gender bias in machine translation and how we can mitigate it. Concretely, we compute established gender bias metrics on the WinoMT corpus from English to German and Spanish. We discover that IFT models default to male-inflected translations, even disregarding female occupational stereotypes. Next, using interpretability methods, we unveil that models systematically overlook the pronoun indicating the gender of a target occupation in misgendered translations. Finally, based on this finding, we propose an easy-to-implement and effective bias mitigation solution based on few-shot learning that leads to significantly fairer translations.
Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions
Sep 25, 2023Training large language models to follow instructions makes them perform better on a wide range of tasks, generally becoming more helpful. However, a perfectly helpful model will follow even the most malicious instructions and readily generate harmful content. In this paper, we raise concerns over the safety of models that only emphasize helpfulness, not safety, in their instruction-tuning. We show that several popular instruction-tuned models are highly unsafe. Moreover, we show that adding just 3% safety examples (a few hundred demonstrations) in the training set when fine-tuning a model like LLaMA can substantially improve their safety. Our safety-tuning does not make models significantly less capable or helpful as measured by standard benchmarks. However, we do find a behavior of exaggerated safety, where too much safety-tuning makes models refuse to respond to reasonable prompts that superficially resemble unsafe ones. Our study sheds light on trade-offs in training LLMs to follow instructions and exhibit safe behavior.