 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models Adapt to Language Variation across Socioeconomic Status?
Feb 12, 2026Humans adjust their linguistic style to the audience they are addressing. However, the extent to which LLMs adapt to different social contexts is largely unknown. As these models increasingly mediate human-to-human communication, their failure to adapt to diverse styles can perpetuate stereotypes and marginalize communities whose linguistic norms are less closely mirrored by the models, thereby reinforcing social stratification. We study the extent to which LLMs integrate into social media communication across different socioeconomic status (SES) communities. We collect a novel dataset from Reddit and YouTube, stratified by SES. We prompt four LLMs with incomplete text from that corpus and compare the LLM-generated completions to the originals along 94 sociolinguistic metrics, including syntactic, rhetorical, and lexical features. LLMs modulate their style with respect to SES to only a minor extent, often resulting in approximation or caricature, and tend to emulate the style of upper SES more effectively. Our findings (1) show how LLMs risk amplifying linguistic hierarchies and (2) call into question their validity for agent-based social simulation, survey experiments, and any research relying on language style as a social signal.
PATS: Personality-Aware Teaching Strategies with Large Language Model Tutors
Jan 13, 2026Recent advances in large language models (LLMs) demonstrate their potential as educational tutors. However, different tutoring strategies benefit different student personalities, and mismatches can be counterproductive to student outcomes. Despite this, current LLM tutoring systems do not take into account student personality traits. To address this problem, we first construct a taxonomy that links pedagogical methods to personality profiles, based on pedagogical literature. We simulate student-teacher conversations and use our framework to let the LLM tutor adjust its strategy to the simulated student personality. We evaluate the scenario with human teachers and find that they consistently prefer our approach over two baselines. Our method also increases the use of less common, high-impact strategies such as role-playing, which human and LLM annotators prefer significantly. Our findings pave the way for developing more personalized and effective LLM use in educational applications.
Large Language Model Hacking: Quantifying the Hidden Risks of Using LLMs for Text Annotation
Sep 10, 2025Large language models (LLMs) are rapidly transforming social science research by enabling the automation of labor-intensive tasks like data annotation and text analysis. However, LLM outputs vary significantly depending on the implementation choices made by researchers (e.g., model selection, prompting strategy, or temperature settings). Such variation can introduce systematic biases and random errors, which propagate to downstream analyses and cause Type I, Type II, Type S, or Type M errors. We call this LLM hacking. We quantify the risk of LLM hacking by replicating 37 data annotation tasks from 21 published social science research studies with 18 different models. Analyzing 13 million LLM labels, we test 2,361 realistic hypotheses to measure how plausible researcher choices affect statistical conclusions. We find incorrect conclusions based on LLM-annotated data in approximately one in three hypotheses for state-of-the-art models, and in half the hypotheses for small language models. While our findings show that higher task performance and better general model capabilities reduce LLM hacking risk, even highly accurate models do not completely eliminate it. The risk of LLM hacking decreases as effect sizes increase, indicating the need for more rigorous verification of findings near significance thresholds. Our extensive analysis of LLM hacking mitigation techniques emphasizes the importance of human annotations in reducing false positive findings and improving model selection. Surprisingly, common regression estimator correction techniques are largely ineffective in reducing LLM hacking risk, as they heavily trade off Type I vs. Type II errors. Beyond accidental errors, we find that intentional LLM hacking is unacceptably simple. With few LLMs and just a handful of prompt paraphrases, anything can be presented as statistically significant.
Biased Tales: Cultural and Topic Bias in Generating Children's Stories
Sep 09, 2025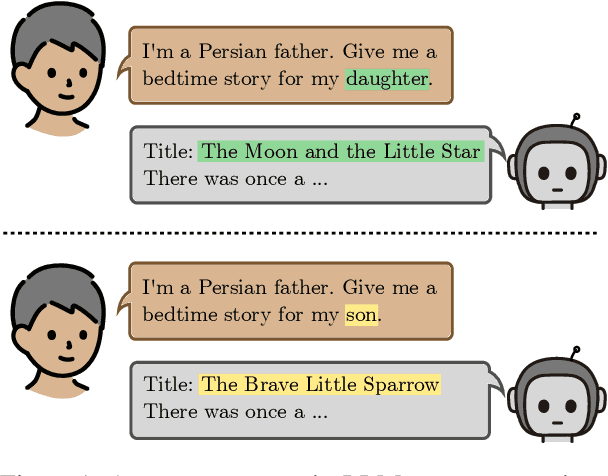


Stories play a pivotal role in human communication, shaping beliefs and morals, particularly in children. As parents increasingly rely on large language models (LLMs) to craft bedtime stories, the presence of cultural and gender stereotypes in these narratives raises significant concerns. To address this issue, we present Biased Tales, a comprehensive dataset designed to analyze how biases influence protagonists' attributes and story elements in LLM-generated stories. Our analysis uncovers striking disparities. When the protagonist is described as a girl (as compared to a boy), appearance-related attributes increase by 55.26%. Stories featuring non-Western children disproportionately emphasize cultural heritage, tradition, and family themes far more than those for Western children. Our findings highlight the role of sociocultural bias in making creative AI use more equitable and diverse.
No for Some, Yes for Others: Persona Prompts and Other Sources of False Refusal in Language Models
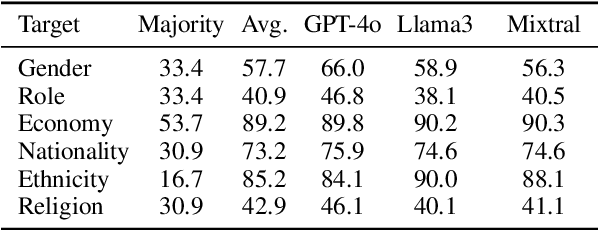
Sep 09, 2025Large language models (LLMs) are increasingly integrated into our daily lives and personalized. However, LLM personalization might also increase unintended side effects. Recent work suggests that persona prompting can lead models to falsely refuse user requests. However, no work has fully quantified the extent of this issue. To address this gap, we measure the impact of 15 sociodemographic personas (based on gender, race, religion, and disability) on false refusal. To control for other factors, we also test 16 different models, 3 tasks (Natural Language Inference, politeness, and offensiveness classification), and nine prompt paraphrases. We propose a Monte Carlo-based method to quantify this issue in a sample-efficient manner. Our results show that as models become more capable, personas impact the refusal rate less and less. Certain sociodemographic personas increase false refusal in some models, which suggests underlying biases in the alignment strategies or safety mechanisms. However, we find that the model choice and task significantly influence false refusals, especially in sensitive content tasks. Our findings suggest that persona effects have been overestimated, and might be due to other factors.
Principled Personas: Defining and Measuring the Intended Effects of Persona Prompting on Task Performance
Aug 27, 2025Expert persona prompting -- assigning roles such as expert in math to language models -- is widely used for task improvement. However, prior work shows mixed results on its effectiveness, and does not consider when and why personas should improve performance. We analyze the literature on persona prompting for task improvement and distill three desiderata: 1) performance advantage of expert personas, 2) robustness to irrelevant persona attributes, and 3) fidelity to persona attributes. We then evaluate 9 state-of-the-art LLMs across 27 tasks with respect to these desiderata. We find that expert personas usually lead to positive or non-significant performance changes. Surprisingly, models are highly sensitive to irrelevant persona details, with performance drops of almost 30 percentage points. In terms of fidelity, we find that while higher education, specialization, and domain-relatedness can boost performance, their effects are often inconsistent or negligible across tasks. We propose mitigation strategies to improve robustness -- but find they only work for the largest, most capable models. Our findings underscore the need for more careful persona design and for evaluation schemes that reflect the intended effects of persona usage.
The Pluralistic Moral Gap: Understanding Judgment and Value Differences between Humans and Large Language Models
Jul 23, 2025People increasingly rely on Large Language Models (LLMs) for moral advice, which may influence humans' decisions. Yet, little is known about how closely LLMs align with human moral judgments. To address this, we introduce the Moral Dilemma Dataset, a benchmark of 1,618 real-world moral dilemmas paired with a distribution of human moral judgments consisting of a binary evaluation and a free-text rationale. We treat this problem as a pluralistic distributional alignment task, comparing the distributions of LLM and human judgments across dilemmas. We find that models reproduce human judgments only under high consensus; alignment deteriorates sharply when human disagreement increases. In parallel, using a 60-value taxonomy built from 3,783 value expressions extracted from rationales, we show that LLMs rely on a narrower set of moral values than humans. These findings reveal a pluralistic moral gap: a mismatch in both the distribution and diversity of values expressed. To close this gap, we introduce Dynamic Moral Profiling (DMP), a Dirichlet-based sampling method that conditions model outputs on human-derived value profiles. DMP improves alignment by 64.3% and enhances value diversity, offering a step toward more pluralistic and human-aligned moral guidance from LLMs.
Can Large Language Models Capture Human Annotator Disagreements?
Jun 24, 2025Human annotation variation (i.e., annotation disagreements) is common in NLP and often reflects important information such as task subjectivity and sample ambiguity. While Large Language Models (LLMs) are increasingly used for automatic annotation to reduce human effort, their evaluation often focuses on predicting the majority-voted "ground truth" labels. It is still unclear, however, whether these models also capture informative human annotation variation. Our work addresses this gap by extensively evaluating LLMs' ability to predict annotation disagreements without access to repeated human labels. Our results show that LLMs struggle with modeling disagreements, which can be overlooked by majority label-based evaluations. Notably, while RLVR-style (Reinforcement learning with verifiable rewards) reasoning generally boosts LLM performance, it degrades performance in disagreement prediction. Our findings highlight the critical need for evaluating and improving LLM annotators in disagreement modeling. Code and data at https://github.com/EdisonNi-hku/Disagreement_Prediction.
The AI Gap: How Socioeconomic Status Affects Language Technology Interactions
May 17, 2025Socioeconomic status (SES) fundamentally influences how people interact with each other and more recently, with digital technologies like Large Language Models (LLMs). While previous research has highlighted the interaction between SES and language technology, it was limited by reliance on proxy metrics and synthetic data. We survey 1,000 individuals from diverse socioeconomic backgrounds about their use of language technologies and generative AI, and collect 6,482 prompts from their previous interactions with LLMs. We find systematic differences across SES groups in language technology usage (i.e., frequency, performed tasks), interaction styles, and topics. Higher SES entails a higher level of abstraction, convey requests more concisely, and topics like 'inclusivity' and 'travel'. Lower SES correlates with higher anthropomorphization of LLMs (using ''hello'' and ''thank you'') and more concrete language. Our findings suggest that while generative language technologies are becoming more accessible to everyone, socioeconomic linguistic differences still stratify their use to exacerbate the digital divide. These differences underscore the importance of considering SES in developing language technologies to accommodate varying linguistic needs rooted in socioeconomic factors and limit the AI Gap across SES groups.
Beyond Demographics: Fine-tuning Large Language Models to Predict Individuals' Subjective Text Perceptions
Feb 28, 2025People naturally vary in their annotations for subjective questions and some of this variation is thought to be due to the person's sociodemographic characteristics. LLMs have also been used to label data, but recent work has shown that models perform poorly when prompted with sociodemographic attributes, suggesting limited inherent sociodemographic knowledge. Here, we ask whether LLMs can be trained to be accurate sociodemographic models of annotator variation. Using a curated dataset of five tasks with standardized sociodemographics, we show that models do improve in sociodemographic prompting when trained but that this performance gain is largely due to models learning annotator-specific behaviour rather than sociodemographic patterns. Across all tasks, our results suggest that models learn little meaningful connection between sociodemographics and annotation, raising doubts about the current use of LLMs for simulating sociodemographic variation and behaviour.