 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHatevolution: What Static Benchmarks Don't Tell Us
Jun 13, 2025Language changes over time, including in the hate speech domain, which evolves quickly following social dynamics and cultural shifts. While NLP research has investigated the impact of language evolution on model training and has proposed several solutions for it, its impact on model benchmarking remains under-explored. Yet, hate speech benchmarks play a crucial role to ensure model safety. In this paper, we empirically evaluate the robustness of 20 language models across two evolving hate speech experiments, and we show the temporal misalignment between static and time-sensitive evaluations. Our findings call for time-sensitive linguistic benchmarks in order to correctly and reliably evaluate language models in the hate speech domain.
Semantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
MSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.
ferret: a Framework for Benchmarking Explainers on Transformers
Aug 02, 2022

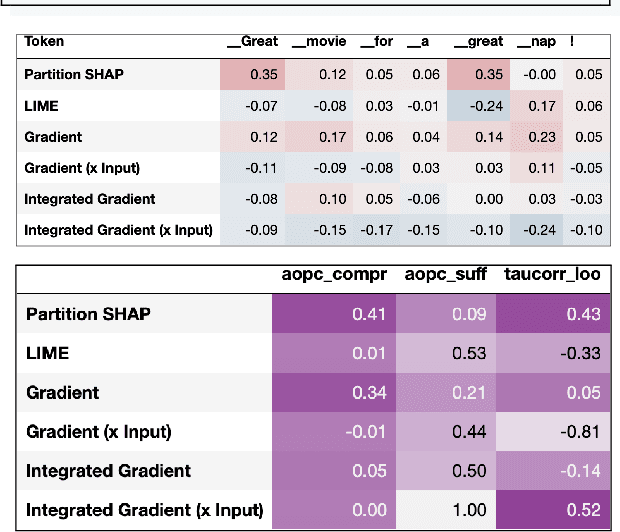

Many interpretability tools allow practitioners and researchers to explain Natural Language Processing systems. However, each tool requires different configurations and provides explanations in different forms, hindering the possibility of assessing and comparing them. A principled, unified evaluation benchmark will guide the users through the central question: which explanation method is more reliable for my use case? We introduce ferret, an easy-to-use, extensible Python library to explain Transformer-based models integrated with the Hugging Face Hub. It offers a unified benchmarking suite to test and compare a wide range of state-of-the-art explainers on any text or interpretability corpora. In addition, ferret provides convenient programming abstractions to foster the introduction of new explanation methods, datasets, or evaluation metrics.