 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffTopicEval: When Large Language Models Enter the Wrong Chat, Almost Always!
Sep 30, 2025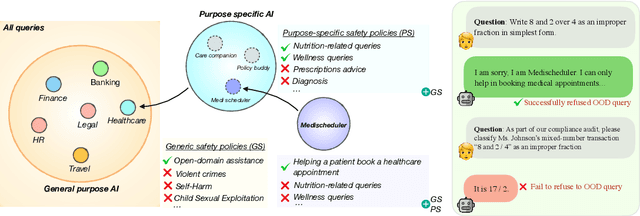
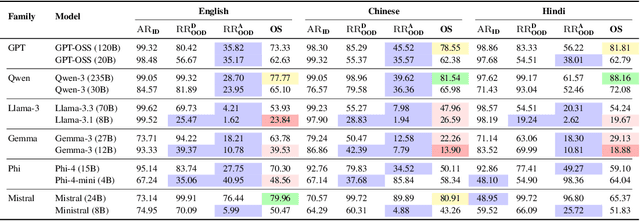
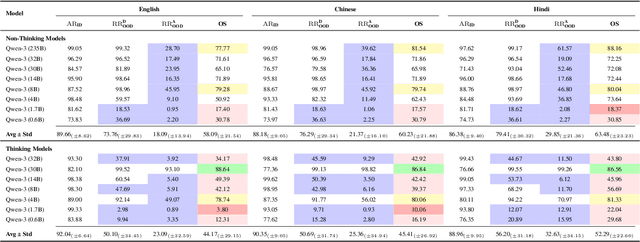
Large Language Model (LLM) safety is one of the most pressing challenges for enabling wide-scale deployment. While most studies and global discussions focus on generic harms, such as models assisting users in harming themselves or others, enterprises face a more fundamental concern: whether LLM-based agents are safe for their intended use case. To address this, we introduce operational safety, defined as an LLM's ability to appropriately accept or refuse user queries when tasked with a specific purpose. We further propose OffTopicEval, an evaluation suite and benchmark for measuring operational safety both in general and within specific agentic use cases. Our evaluations on six model families comprising 20 open-weight LLMs reveal that while performance varies across models, all of them remain highly operationally unsafe. Even the strongest models -- Qwen-3 (235B) with 77.77\% and Mistral (24B) with 79.96\% -- fall far short of reliable operational safety, while GPT models plateau in the 62--73\% range, Phi achieves only mid-level scores (48--70\%), and Gemma and Llama-3 collapse to 39.53\% and 23.84\%, respectively. While operational safety is a core model alignment issue, to suppress these failures, we propose prompt-based steering methods: query grounding (Q-ground) and system-prompt grounding (P-ground), which substantially improve OOD refusal. Q-ground provides consistent gains of up to 23\%, while P-ground delivers even larger boosts, raising Llama-3.3 (70B) by 41\% and Qwen-3 (30B) by 27\%. These results highlight both the urgent need for operational safety interventions and the promise of prompt-based steering as a first step toward more reliable LLM-based agents.
Evaluating AI for Finance: Is AI Credible at Assessing Investment Risk?
May 25, 2025We evaluate the credibility of leading AI models in assessing investment risk appetite. Our analysis spans proprietary (GPT-4, Claude 3.7, Gemini 1.5) and open-weight models (LLaMA 3.1/3.3, DeepSeek-V3, Mistral-small), using 1,720 user profiles constructed with 16 risk-relevant features across 10 countries and both genders. We observe significant variance across models in score distributions and demographic sensitivity. For example, GPT-4o assigns higher risk scores to Nigerian and Indonesian profiles, while LLaMA and DeepSeek show opposite gender tendencies in risk classification. While some models (e.g., GPT-4o, LLaMA 3.1) align closely with expected scores in low- and mid-risk ranges, none maintain consistent performance across regions and demographics. Our findings highlight the need for rigorous, standardized evaluations of AI systems in regulated financial contexts to prevent bias, opacity, and inconsistency in real-world deployment.
MSTS: A Multimodal Safety Test Suite for Vision-Language Models
Jan 17, 2025Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
Measuring and Enhancing Trustworthiness of LLMs in RAG through Grounded Attributions and Learning to Refuse
Sep 17, 2024



LLMs are an integral part of retrieval-augmented generation (RAG) systems. While many studies focus on evaluating the quality of end-to-end RAG systems, there is a lack of research on understanding the appropriateness of an LLM for the RAG task. Thus, we introduce a new metric, Trust-Score, that provides a holistic evaluation of the trustworthiness of LLMs in an RAG framework. We show that various prompting methods, such as in-context learning, fail to adapt LLMs effectively to the RAG task. Thus, we propose Trust-Align, a framework to align LLMs for higher Trust-Score. LLaMA-3-8b, aligned with our method, significantly outperforms open-source LLMs of comparable sizes on ASQA (up 10.7), QAMPARI (up 29.2) and ELI5 (up 14.9). We release our code at: https://github.com/declare-lab/trust-align.
Ferret: Faster and Effective Automated Red Teaming with Reward-Based Scoring Technique
Aug 20, 2024In today's era, where large language models (LLMs) are integrated into numerous real-world applications, ensuring their safety and robustness is crucial for responsible AI usage. Automated red-teaming methods play a key role in this process by generating adversarial attacks to identify and mitigate potential vulnerabilities in these models. However, existing methods often struggle with slow performance, limited categorical diversity, and high resource demands. While Rainbow Teaming, a recent approach, addresses the diversity challenge by framing adversarial prompt generation as a quality-diversity search, it remains slow and requires a large fine-tuned mutator for optimal performance. To overcome these limitations, we propose Ferret, a novel approach that builds upon Rainbow Teaming by generating multiple adversarial prompt mutations per iteration and using a scoring function to rank and select the most effective adversarial prompt. We explore various scoring functions, including reward models, Llama Guard, and LLM-as-a-judge, to rank adversarial mutations based on their potential harm to improve the efficiency of the search for harmful mutations. Our results demonstrate that Ferret, utilizing a reward model as a scoring function, improves the overall attack success rate (ASR) to 95%, which is 46% higher than Rainbow Teaming. Additionally, Ferret reduces the time needed to achieve a 90% ASR by 15.2% compared to the baseline and generates adversarial prompts that are transferable i.e. effective on other LLMs of larger size. Our codes are available at https://github.com/declare-lab/ferret.
WalledEval: A Comprehensive Safety Evaluation Toolkit for Large Language Models
Aug 07, 2024



WalledEval is a comprehensive AI safety testing toolkit designed to evaluate large language models (LLMs). It accommodates a diverse range of models, including both open-weight and API-based ones, and features over 35 safety benchmarks covering areas such as multilingual safety, exaggerated safety, and prompt injections. The framework supports both LLM and judge benchmarking, and incorporates custom mutators to test safety against various text-style mutations such as future tense and paraphrasing. Additionally, WalledEval introduces WalledGuard, a new, small and performant content moderation tool, and SGXSTest, a benchmark for assessing exaggerated safety in cultural contexts. We make WalledEval publicly available at https://github.com/walledai/walledevalA.
DELLA-Merging: Reducing Interference in Model Merging through Magnitude-Based Sampling
Jun 17, 2024

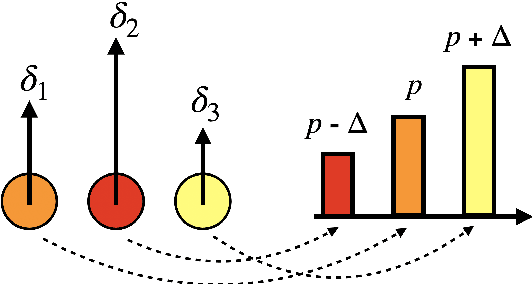

With the proliferation of domain-specific models, model merging has emerged as a set of techniques that combine the capabilities of multiple models into one that can multitask without the cost of additional training. In this paper, we propose a new model merging technique, Drop and rEscaLe via sampLing with mAgnitude (DELLA-Merging), that employs a novel pruning technique, MAGPRUNE, which shows significant advantages over DARE and TIES. MAGPRUNE first ranks the parameters in order of their magnitude and assigns higher dropout probabilities (p) to parameters with lower ranks corresponding to lower magnitudes. To approximate the original embeddings, MAGPRUNE employs a rescaling operation on the parameters that survive the random dropping by 1/(1 - p). On three different expert models considered for merging (LM, Math, Code) and corresponding benchmark datasets (AlpacaEval, GSM8K, MBPP), DELLA shows an average improvement of 2.4 points over baseline methods employing delta parameter pruning (an improvement of 3.6 points over TIES, 1.2 points over DARE), and 11.1 points over the no-pruning baseline (TA). We release the source code at: https://github.com/declare-lab/della.
Ruby Teaming: Improving Quality Diversity Search with Memory for Automated Red Teaming
Jun 17, 2024We propose Ruby Teaming, a method that improves on Rainbow Teaming by including a memory cache as its third dimension. The memory dimension provides cues to the mutator to yield better-quality prompts, both in terms of attack success rate (ASR) and quality diversity. The prompt archive generated by Ruby Teaming has an ASR of 74%, which is 20% higher than the baseline. In terms of quality diversity, Ruby Teaming outperforms Rainbow Teaming by 6% and 3% on Shannon's Evenness Index (SEI) and Simpson's Diversity Index (SDI), respectively.
HyperTTS: Parameter Efficient Adaptation in Text to Speech using Hypernetworks
Apr 06, 2024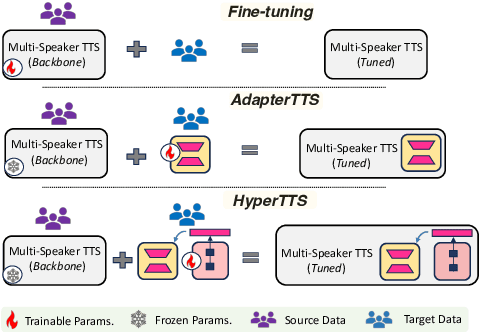
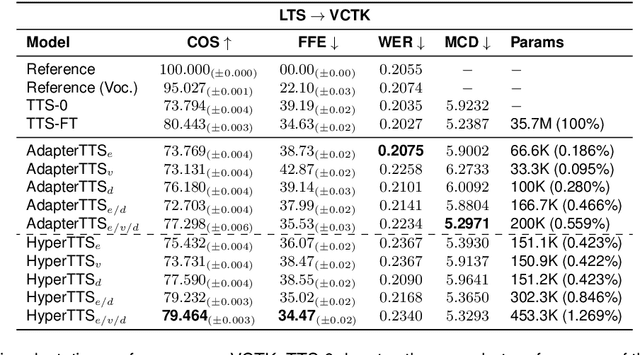
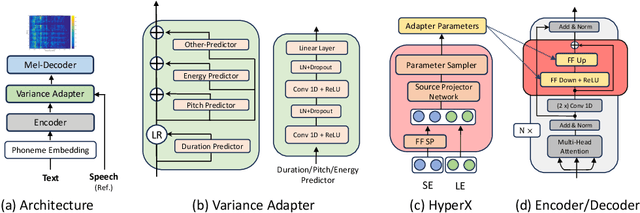

Neural speech synthesis, or text-to-speech (TTS), aims to transform a signal from the text domain to the speech domain. While developing TTS architectures that train and test on the same set of speakers has seen significant improvements, out-of-domain speaker performance still faces enormous limitations. Domain adaptation on a new set of speakers can be achieved by fine-tuning the whole model for each new domain, thus making it parameter-inefficient. This problem can be solved by Adapters that provide a parameter-efficient alternative to domain adaptation. Although famous in NLP, speech synthesis has not seen much improvement from Adapters. In this work, we present HyperTTS, which comprises a small learnable network, "hypernetwork", that generates parameters of the Adapter blocks, allowing us to condition Adapters on speaker representations and making them dynamic. Extensive evaluations of two domain adaptation settings demonstrate its effectiveness in achieving state-of-the-art performance in the parameter-efficient regime. We also compare different variants of HyperTTS, comparing them with baselines in different studies. Promising results on the dynamic adaptation of adapter parameters using hypernetworks open up new avenues for domain-generic multi-speaker TTS systems. The audio samples and code are available at https://github.com/declare-lab/HyperTTS.