 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuby Teaming: Improving Quality Diversity Search with Memory for Automated Red Teaming
Jun 17, 2024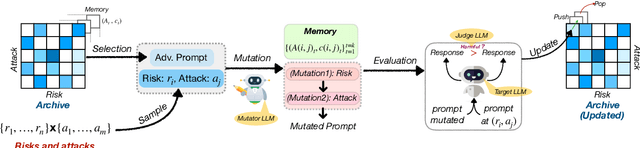
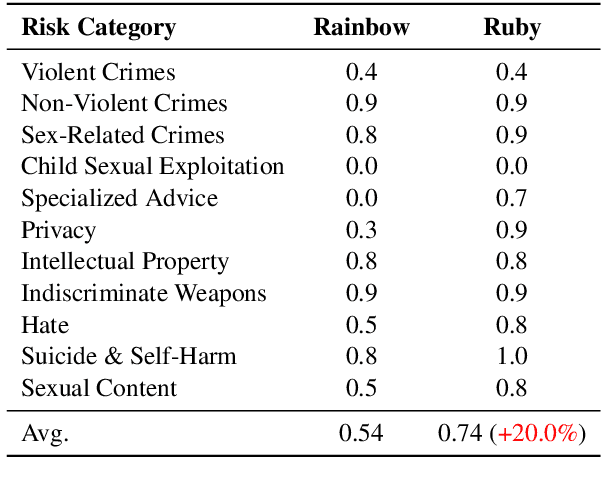
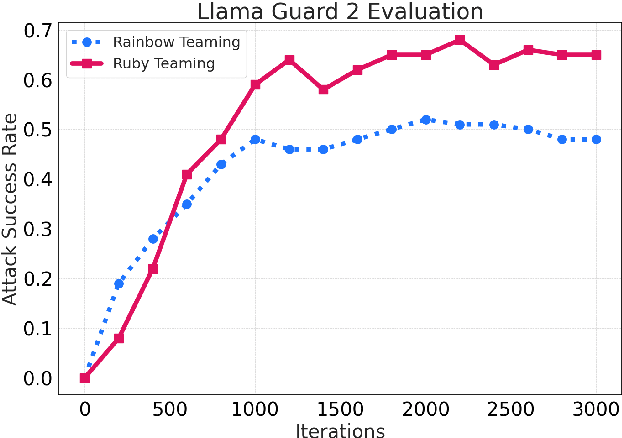
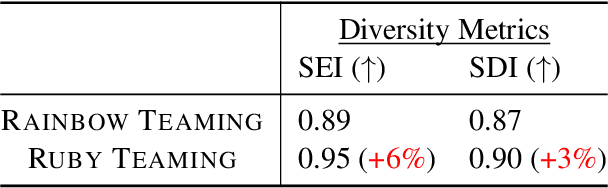
We propose Ruby Teaming, a method that improves on Rainbow Teaming by including a memory cache as its third dimension. The memory dimension provides cues to the mutator to yield better-quality prompts, both in terms of attack success rate (ASR) and quality diversity. The prompt archive generated by Ruby Teaming has an ASR of 74%, which is 20% higher than the baseline. In terms of quality diversity, Ruby Teaming outperforms Rainbow Teaming by 6% and 3% on Shannon's Evenness Index (SEI) and Simpson's Diversity Index (SDI), respectively.
PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns
Mar 20, 2024
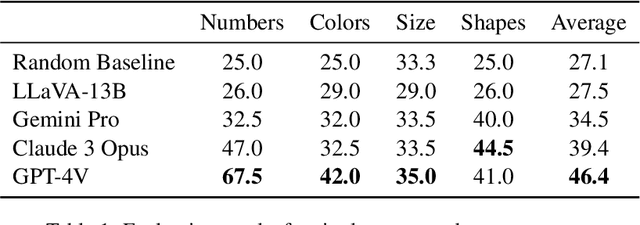
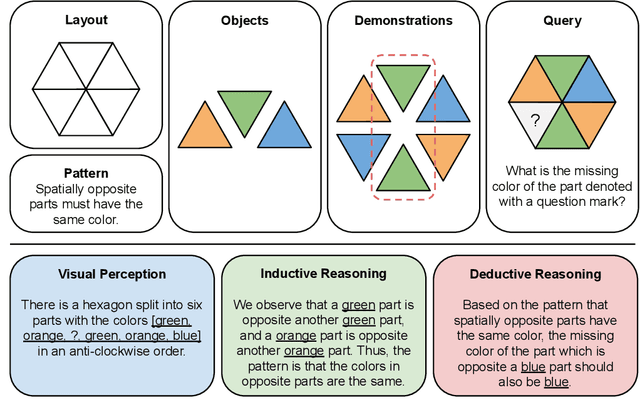
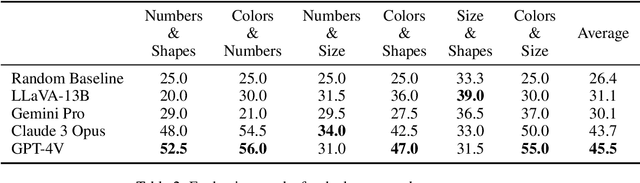
Large multimodal models extend the impressive capabilities of large language models by integrating multimodal understanding abilities. However, it is not clear how they can emulate the general intelligence and reasoning ability of humans. As recognizing patterns and abstracting concepts are key to general intelligence, we introduce PuzzleVQA, a collection of puzzles based on abstract patterns. With this dataset, we evaluate large multimodal models with abstract patterns based on fundamental concepts, including colors, numbers, sizes, and shapes. Through our experiments on state-of-the-art large multimodal models, we find that they are not able to generalize well to simple abstract patterns. Notably, even GPT-4V cannot solve more than half of the puzzles. To diagnose the reasoning challenges in large multimodal models, we progressively guide the models with our ground truth reasoning explanations for visual perception, inductive reasoning, and deductive reasoning. Our systematic analysis finds that the main bottlenecks of GPT-4V are weaker visual perception and inductive reasoning abilities. Through this work, we hope to shed light on the limitations of large multimodal models and how they can better emulate human cognitive processes in the future (Our data and code will be released publicly at https://github.com/declare-lab/LLM-PuzzleTest).
Are Language Models Puzzle Prodigies? Algorithmic Puzzles Unveil Serious Challenges in Multimodal Reasoning
Mar 13, 2024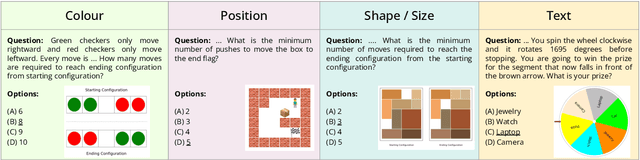
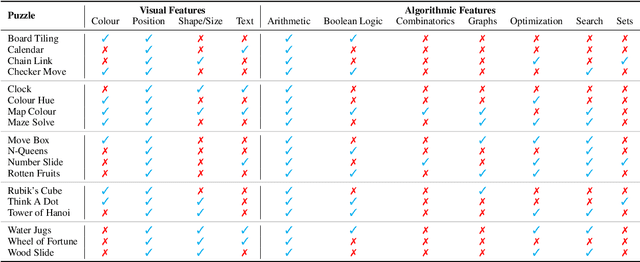
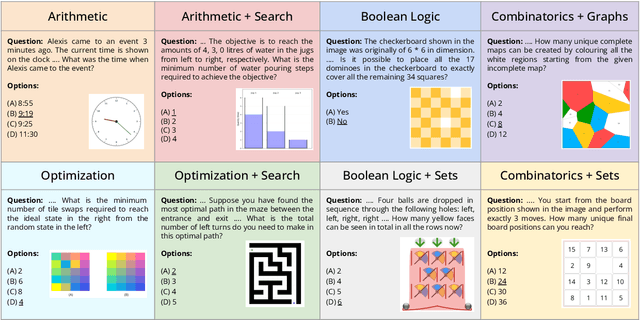
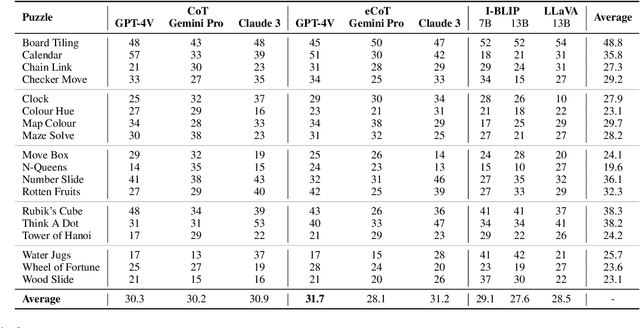
This paper introduces the novel task of multimodal puzzle solving, framed within the context of visual question-answering. We present a new dataset, AlgoPuzzleVQA designed to challenge and evaluate the capabilities of multimodal language models in solving algorithmic puzzles that necessitate both visual understanding, language understanding, and complex algorithmic reasoning. We create the puzzles to encompass a diverse array of mathematical and algorithmic topics such as boolean logic, combinatorics, graph theory, optimization, search, etc., aiming to evaluate the gap between visual data interpretation and algorithmic problem-solving skills. The dataset is generated automatically from code authored by humans. All our puzzles have exact solutions that can be found from the algorithm without tedious human calculations. It ensures that our dataset can be scaled up arbitrarily in terms of reasoning complexity and dataset size. Our investigation reveals that large language models (LLMs) such as GPT4V and Gemini exhibit limited performance in puzzle-solving tasks. We find that their performance is near random in a multi-choice question-answering setup for a significant number of puzzles. The findings emphasize the challenges of integrating visual, language, and algorithmic knowledge for solving complex reasoning problems.