 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptDistill: Query-based Selective Token Retention in Intermediate Layers for Efficient Large Language Model Inference
Mar 30, 2025
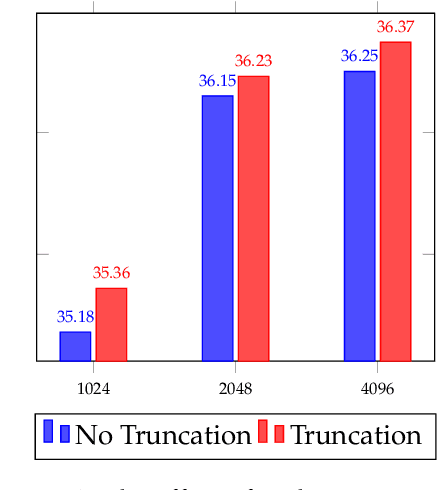
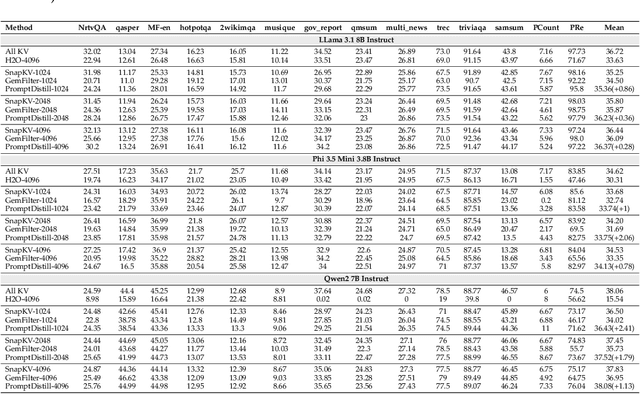
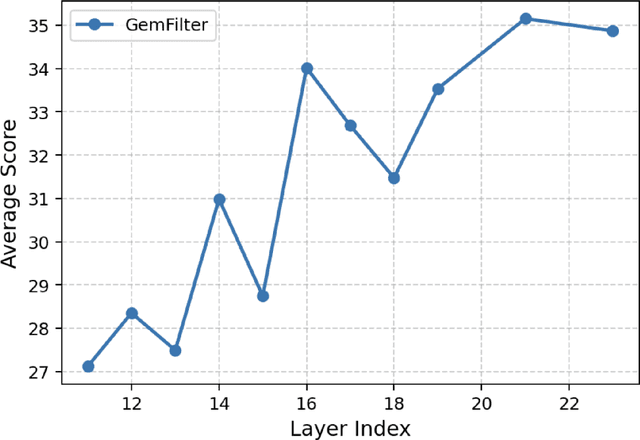
As large language models (LLMs) tackle increasingly complex tasks and longer documents, their computational and memory costs during inference become a major bottleneck. To address this, we propose PromptDistill, a novel, training-free method that improves inference efficiency while preserving generation quality. PromptDistill identifies and retains the most informative tokens by leveraging attention interactions in early layers, preserving their hidden states while reducing the computational burden in later layers. This allows the model to focus on essential contextual information without fully processing all tokens. Unlike previous methods such as H2O and SnapKV, which perform compression only after processing the entire input, or GemFilter, which selects a fixed portion of the initial prompt without considering contextual dependencies, PromptDistill dynamically allocates computational resources to the most relevant tokens while maintaining a global awareness of the input. Experiments using our method and baseline approaches with base models such as LLaMA 3.1 8B Instruct, Phi 3.5 Mini Instruct, and Qwen2 7B Instruct on benchmarks including LongBench, InfBench, and Needle in a Haystack demonstrate that PromptDistill significantly improves efficiency while having minimal impact on output quality compared to the original models. With a single-stage selection strategy, PromptDistill effectively balances performance and efficiency, outperforming prior methods like GemFilter, H2O, and SnapKV due to its superior ability to retain essential information. Specifically, compared to GemFilter, PromptDistill achieves an overall $1\%$ to $5\%$ performance improvement while also offering better time efficiency. Additionally, we explore multi-stage selection, which further improves efficiency while maintaining strong generation performance.
The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles
Feb 03, 2025![Figure 1 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F7-Table1-1.png&w=640&q=75)
![Figure 2 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F11-Table2-1.png&w=640&q=75)
![Figure 4 for The Jumping Reasoning Curve? Tracking the Evolution of Reasoning Performance in GPT-[n] and o-[n] Models on Multimodal Puzzles](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2F24658d26647e5a2123e7f3e0e71ede50cccc47d1%2F3-Figure3-1.png&w=640&q=75)
The releases of OpenAI's o1 and o3 mark a significant paradigm shift in Large Language Models towards advanced reasoning capabilities. Notably, o3 outperformed humans in novel problem-solving and skill acquisition on the Abstraction and Reasoning Corpus for Artificial General Intelligence (ARC-AGI). However, this benchmark is limited to symbolic patterns, whereas humans often perceive and reason about multimodal scenarios involving both vision and language data. Thus, there is an urgent need to investigate advanced reasoning capabilities in multimodal tasks. To this end, we track the evolution of the GPT-[n] and o-[n] series models on challenging multimodal puzzles, requiring fine-grained visual perception with abstract or algorithmic reasoning. The superior performance of o1 comes at nearly 750 times the computational cost of GPT-4o, raising concerns about its efficiency. Our results reveal a clear upward trend in reasoning capabilities across model iterations, with notable performance jumps across GPT-series models and subsequently to o1. Nonetheless, we observe that the o1 model still struggles with simple multimodal puzzles requiring abstract reasoning. Furthermore, its performance in algorithmic puzzles remains poor. We plan to continuously track new models in the series and update our results in this paper accordingly. All resources used in this evaluation are openly available https://github.com/declare-lab/LLM-PuzzleTest.
M-Longdoc: A Benchmark For Multimodal Super-Long Document Understanding And A Retrieval-Aware Tuning Framework
Nov 09, 2024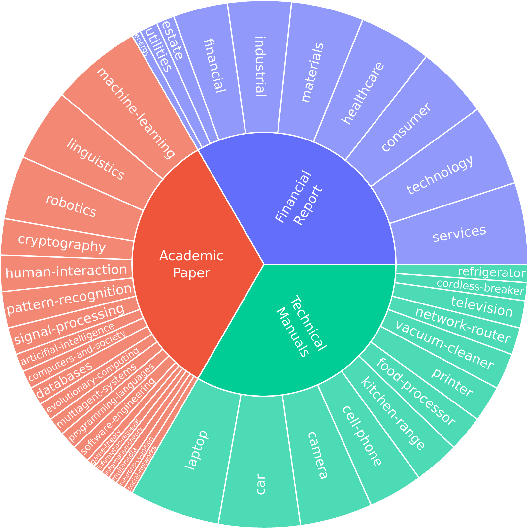
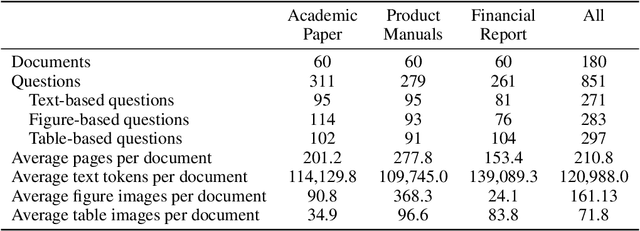
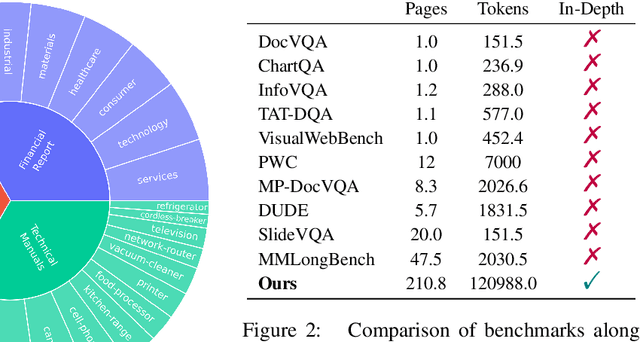
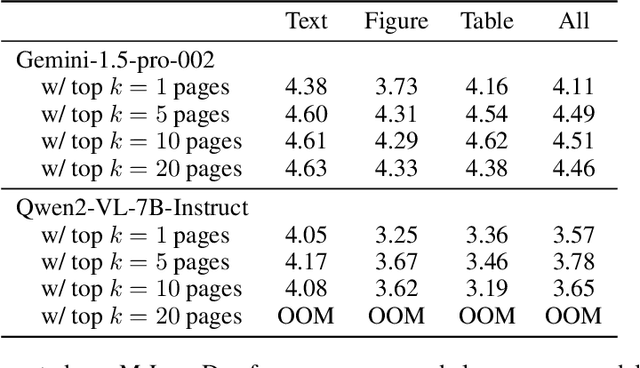
The ability to understand and answer questions over documents can be useful in many business and practical applications. However, documents often contain lengthy and diverse multimodal contents such as texts, figures, and tables, which are very time-consuming for humans to read thoroughly. Hence, there is an urgent need to develop effective and automated methods to aid humans in this task. In this work, we introduce M-LongDoc, a benchmark of 851 samples, and an automated framework to evaluate the performance of large multimodal models. We further propose a retrieval-aware tuning approach for efficient and effective multimodal document reading. Compared to existing works, our benchmark consists of more recent and lengthy documents with hundreds of pages, while also requiring open-ended solutions and not just extractive answers. To our knowledge, our training framework is the first to directly address the retrieval setting for multimodal long documents. To enable tuning open-source models, we construct a training corpus in a fully automatic manner for the question-answering task over such documents. Experiments show that our tuning approach achieves a relative improvement of 4.6% for the correctness of model responses, compared to the baseline open-source models. Our data, code, and models are available at https://multimodal-documents.github.io.
Reasoning Paths Optimization: Learning to Reason and Explore From Diverse Paths
Oct 07, 2024


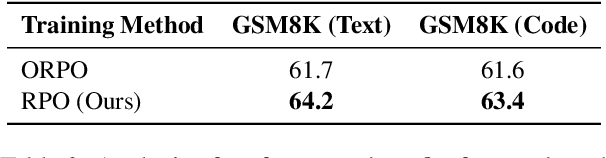
Advanced models such as OpenAI o1 exhibit impressive problem-solving capabilities through step-by-step reasoning. However, they may still falter on more complex problems, making errors that disrupt their reasoning paths. We attribute this to the expansive solution space, where each step has the risk of diverging into mistakes. To enhance language model reasoning, we introduce a specialized training framework called Reasoning Paths Optimization (RPO), which enables learning to reason and explore from diverse paths. Our approach encourages favorable branches at each reasoning step while penalizing unfavorable ones, enhancing the model's overall problem-solving performance. Reasoning Paths Optimization does not rely on large-scale human-annotated rationales or outputs from closed-source models, making it scalable and data-efficient. We focus on multi-step reasoning tasks, such as math word problems and science-based exam questions. The experiments demonstrate that our framework significantly enhances the reasoning performance of large language models, with up to 3.1% and 4.3% improvement on GSM8K and MMLU (STEM) respectively. Our data and code can be found at https://reasoning-paths.github.io.
Can-Do! A Dataset and Neuro-Symbolic Grounded Framework for Embodied Planning with Large Multimodal Models
Sep 22, 2024Large multimodal models have demonstrated impressive problem-solving abilities in vision and language tasks, and have the potential to encode extensive world knowledge. However, it remains an open challenge for these models to perceive, reason, plan, and act in realistic environments. In this work, we introduce Can-Do, a benchmark dataset designed to evaluate embodied planning abilities through more diverse and complex scenarios than previous datasets. Our dataset includes 400 multimodal samples, each consisting of natural language user instructions, visual images depicting the environment, state changes, and corresponding action plans. The data encompasses diverse aspects of commonsense knowledge, physical understanding, and safety awareness. Our fine-grained analysis reveals that state-of-the-art models, including GPT-4V, face bottlenecks in visual perception, comprehension, and reasoning abilities. To address these challenges, we propose NeuroGround, a neurosymbolic framework that first grounds the plan generation in the perceived environment states and then leverages symbolic planning engines to augment the model-generated plans. Experimental results demonstrate the effectiveness of our framework compared to strong baselines. Our code and dataset are available at https://embodied-planning.github.io.
SeaLLMs 3: Open Foundation and Chat Multilingual Large Language Models for Southeast Asian Languages
Jul 29, 2024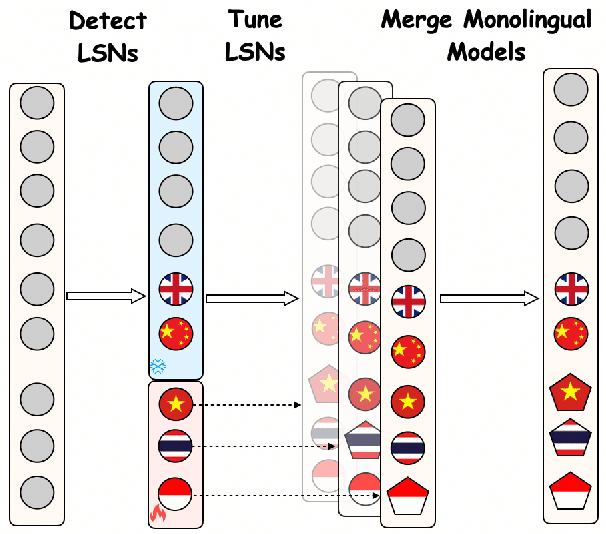
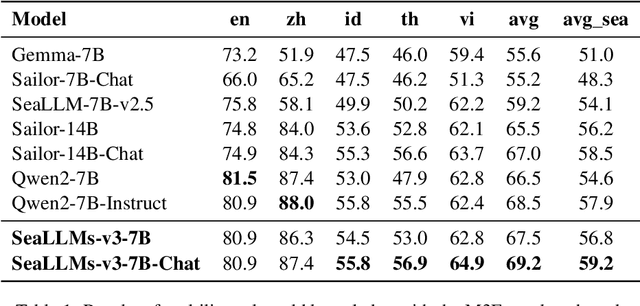
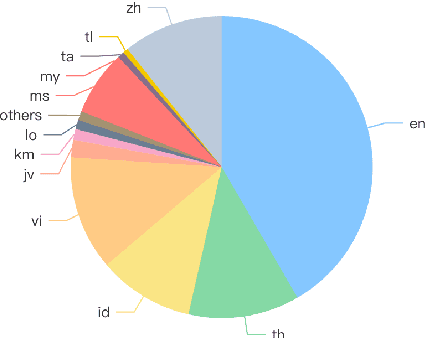
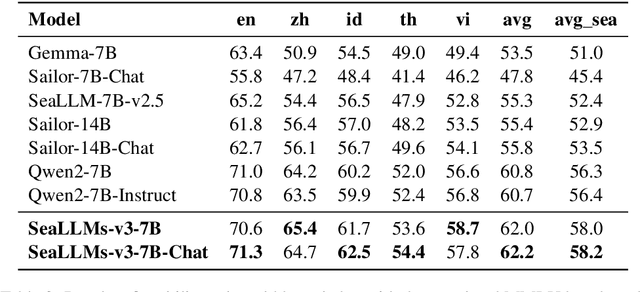
Large Language Models (LLMs) have shown remarkable abilities across various tasks, yet their development has predominantly centered on high-resource languages like English and Chinese, leaving low-resource languages underserved. To address this disparity, we present SeaLLMs 3, the latest iteration of the SeaLLMs model family, tailored for Southeast Asian languages. This region, characterized by its rich linguistic diversity, has lacked adequate language technology support. SeaLLMs 3 aims to bridge this gap by covering a comprehensive range of languages spoken in this region, including English, Chinese, Indonesian, Vietnamese, Thai, Tagalog, Malay, Burmese, Khmer, Lao, Tamil, and Javanese. Leveraging efficient language enhancement techniques and a specially constructed instruction tuning dataset, SeaLLMs 3 significantly reduces training costs while maintaining high performance and versatility. Our model excels in tasks such as world knowledge, mathematical reasoning, translation, and instruction following, achieving state-of-the-art performance among similarly sized models. Additionally, we prioritized safety and reliability by addressing both general and culture-specific considerations and incorporated mechanisms to reduce hallucinations. This work underscores the importance of inclusive AI, showing that advanced LLM capabilities can benefit underserved linguistic and cultural communities.
Auto Arena of LLMs: Automating LLM Evaluations with Agent Peer-battles and Committee Discussions
May 30, 2024
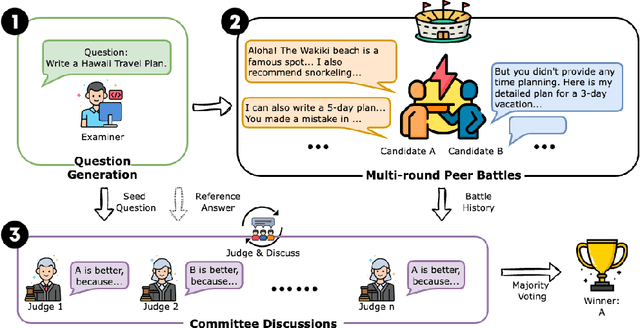
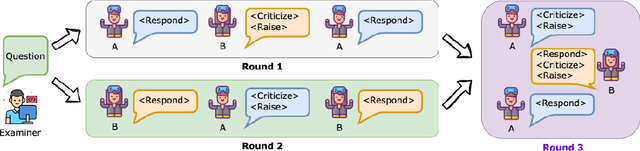
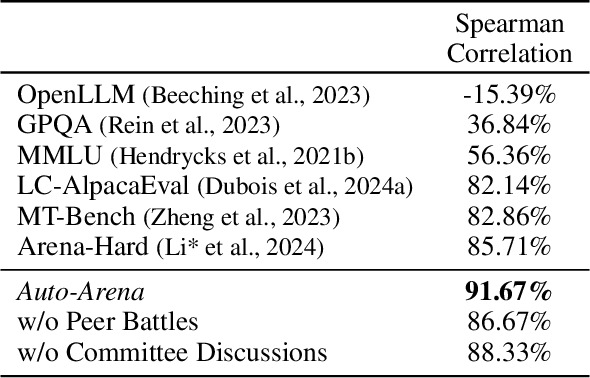
As LLMs evolve on a daily basis, there is an urgent need for a trustworthy evaluation method that can provide robust evaluation results in a timely fashion. Currently, as static benchmarks are prone to contamination concerns, users tend to trust human voting platforms, such as Chatbot Arena. However, human annotations require extensive manual efforts. To provide an automatic, robust, and trustworthy evaluation framework, we innovatively propose the Auto-Arena of LLMs, which automates the entire evaluation process with LLM agents. Firstly, an examiner LLM devises queries. Then, a pair of candidate LLMs engage in a multi-round peer-battle around the query, during which the LLM's true performance gaps become visible. Finally, a committee of LLM judges collectively discuss and determine the winner, which alleviates bias and promotes fairness. In our extensive experiment on the 17 newest LLMs, Auto-Arena shows the highest correlation with human preferences, providing a promising alternative to human evaluation platforms.
PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns
Mar 20, 2024
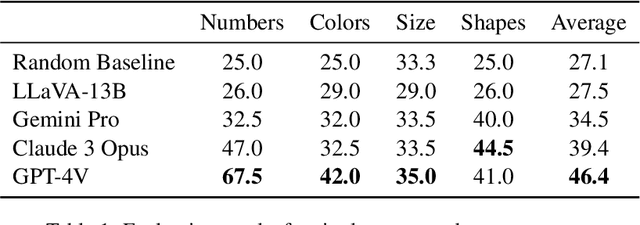
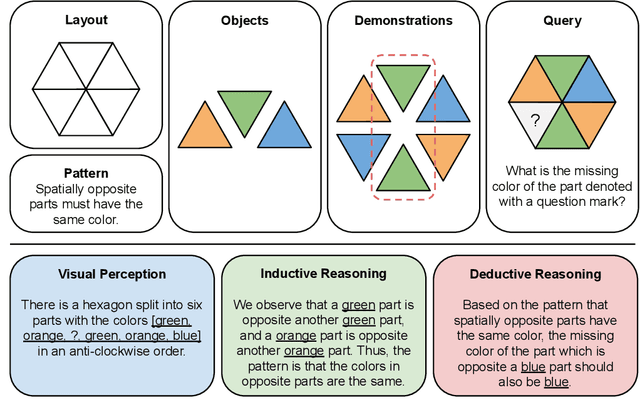
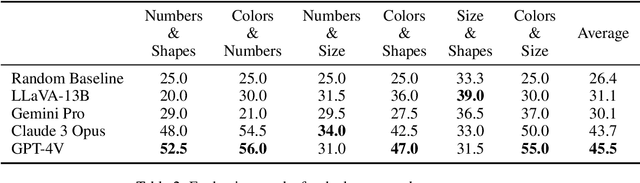
Large multimodal models extend the impressive capabilities of large language models by integrating multimodal understanding abilities. However, it is not clear how they can emulate the general intelligence and reasoning ability of humans. As recognizing patterns and abstracting concepts are key to general intelligence, we introduce PuzzleVQA, a collection of puzzles based on abstract patterns. With this dataset, we evaluate large multimodal models with abstract patterns based on fundamental concepts, including colors, numbers, sizes, and shapes. Through our experiments on state-of-the-art large multimodal models, we find that they are not able to generalize well to simple abstract patterns. Notably, even GPT-4V cannot solve more than half of the puzzles. To diagnose the reasoning challenges in large multimodal models, we progressively guide the models with our ground truth reasoning explanations for visual perception, inductive reasoning, and deductive reasoning. Our systematic analysis finds that the main bottlenecks of GPT-4V are weaker visual perception and inductive reasoning abilities. Through this work, we hope to shed light on the limitations of large multimodal models and how they can better emulate human cognitive processes in the future (Our data and code will be released publicly at https://github.com/declare-lab/LLM-PuzzleTest).
Contrastive Chain-of-Thought Prompting
Nov 15, 2023Despite the success of chain of thought in enhancing language model reasoning, the underlying process remains less well understood. Although logically sound reasoning appears inherently crucial for chain of thought, prior studies surprisingly reveal minimal impact when using invalid demonstrations instead. Furthermore, the conventional chain of thought does not inform language models on what mistakes to avoid, which potentially leads to more errors. Hence, inspired by how humans can learn from both positive and negative examples, we propose contrastive chain of thought to enhance language model reasoning. Compared to the conventional chain of thought, our approach provides both valid and invalid reasoning demonstrations, to guide the model to reason step-by-step while reducing reasoning mistakes. To improve generalization, we introduce an automatic method to construct contrastive demonstrations. Our experiments on reasoning benchmarks demonstrate that contrastive chain of thought can serve as a general enhancement of chain-of-thought prompting.
Flacuna: Unleashing the Problem Solving Power of Vicuna using FLAN Fine-Tuning
Jul 05, 2023Recently, the release of INSTRUCTEVAL has provided valuable insights into the performance of large language models (LLMs) that utilize encoder-decoder or decoder-only architecture. Interestingly, despite being introduced four years ago, T5-based LLMs, such as FLAN-T5, continue to outperform the latest decoder-based LLMs, such as LLAMA and VICUNA, on tasks that require general problem-solving skills. This performance discrepancy can be attributed to three key factors: (1) Pre-training data, (2) Backbone architecture, and (3) Instruction dataset. In this technical report, our main focus is on investigating the impact of the third factor by leveraging VICUNA, a large language model based on LLAMA, which has undergone fine-tuning on ChatGPT conversations. To achieve this objective, we fine-tuned VICUNA using a customized instruction dataset collection called FLANMINI. This collection includes a subset of the large-scale instruction dataset known as FLAN, as well as various code-related datasets and conversational datasets derived from ChatGPT/GPT-4. This dataset comprises a large number of tasks that demand problem-solving skills. Our experimental findings strongly indicate that the enhanced problem-solving abilities of our model, FLACUNA, are obtained through fine-tuning VICUNA on the FLAN dataset, leading to significant improvements across numerous benchmark datasets in INSTRUCTEVAL. FLACUNA is publicly available at https://huggingface.co/declare-lab/flacuna-13b-v1.0.